How to scale AI apps - Lessons from building a billion-scale AI Gateway
Discover the journey of Portkey.ai in building a billion-scale AI Gateway. Learn key lessons on managing costs, optimizing performance, and ensuring accuracy while scaling generative AI applications.

Scaling generative AI applications is no small feat. With over 600 teams relying on Portkey to serve 640 billion tokens, the journey from concept to billion-scale infrastructure has been both exhilarating and educational.
In this blog, we discuss the core lessons learned while building Portkey, an AI Gateway that simplifies deploying generative AI systems at scale. We’ll dive into why AI Gateways are essential, the challenges we tackled, and actionable takeaways.
The Birth of Portkey's AI Gateway
Before launching Portkey, Rohit Agarwal saw firsthand the challenges of scaling generative AI systems.
In his previous stints, he experimented with early versions of BERT and GPT-2. Despite generative AI’s promise, operational challenges like evolving models and lack of observability plagued these deployments.
These challenges shaped the vision for Portkey: a production infrastructure that lets teams deploy and scale their AI applications without getting tangled in operational complexity.
Why AI Gateways Are Critical
Deploying AI applications isn’t just about API calls; it’s about managing complexity at scale. AI Gateway is the central hub that simplifies this process, taking over tasks like prompt management, logging, and governance while connecting to models like OpenAI’s GPT or Anthropic’s Claude.
Without a gateway, teams often find themselves lost in:
- Black-box issues: No visibility into why a model fails.
- Model evolution: Uncertainty about switching models or retraining.
- Business risks: Legal and reputational risks tied to compliance failures.
The AI Gateway addresses these challenges by providing operational control with forward compatibility and governance structures for risk-free deployments.
Key Lessons from Building at Scale
Managing Costs
Scaling comes with cost challenges, but with thoughtful practices, they can be managed effectively:
- Start lean: Don’t stress costs at the prototype stage. As Rohit notes, “A16z shared a graph showing how the cost of LLMs has dropped significantly—like $2 for a year of heavy usage.”
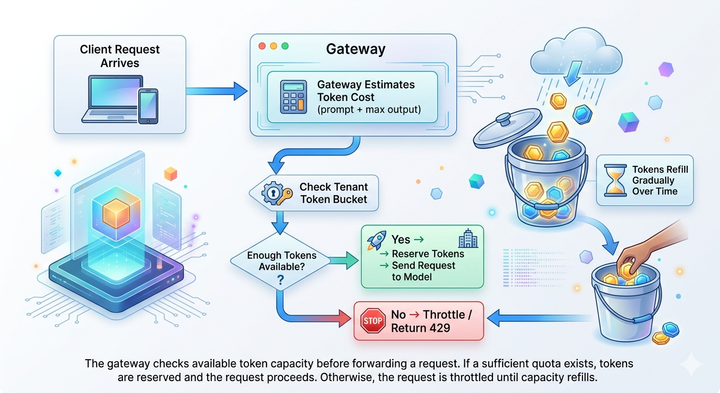
- Monitor usage: Set limits for different applications to prevent cost surges caused by rogue agents or excessive requests.
- Optimize with semantic caching: Cache similar requests to save costs while maintaining accuracy. This has yielded up to 60% cache hit rates for some customers.
- Shift to domain-specific models: As use cases mature, moving to fine-tuned or domain-specific models like LLaMA 3.2 can slash costs and improve performance.
Optimizing Performance
LLMs are powerful but notoriously unpredictable, with frequent latency spikes and downtime. Here’s how to stay ahead:
- Set up fallbacks and load balancing: Always have alternate models or regions ready to mitigate downtime.
- Route requests regionally: Decrease latency and align with compliance by routing requests to local models.
- Use perceived latency improvements: Techniques like streaming responses can enhance user experience, even if backend processing takes time.
Ensuring Accuracy
- Continuously refine prompts and monitor for regressions with tools like Promptfoo.
- Implement AI guardrails for safety, security, and accuracy to ensure outputs are relevant, complete, and unbiased.
Emerging Trends in Generative AI
As generative AI tools evolve, we’re likely to see:
- Voice as the interface: Conversational interactions with AI becoming the norm by 2025.
- Fine-tuned domain models: Custom models built on private datasets for higher accuracy and relevance.
- Enhanced agentic workflows: Observability and optimization for more autonomous systems.
Takeaways for AI teams
For startups and enterprises, here’s when to start focusing on the three pillars:
- Cost: Be vigilant when monthly usage surpasses $100 or when request volumes grow significantly.
- Performance: Implement retries, fallbacks, and load balancing as you approach production.
- Compliance: Prioritize guardrails post-product-market-fit to handle serious customer concerns.
Building an AI Gateway at a billion-scale has taught us one key truth: scaling generative AI isn’t just about technology—it’s about solving operational bottlenecks with precision.
AI Gateways offer a great solution to achieving cost efficiency, reliable performance, and accurate outputs, letting teams focus on innovation rather than infrastructure. Whether you’re a startup prototyping an idea or an enterprise scaling to billions of tokens, the lessons from Portkey’s journey are your blueprint to success.
Want to build smarter with AI? Explore how Portkey can power your generative AI applications today.