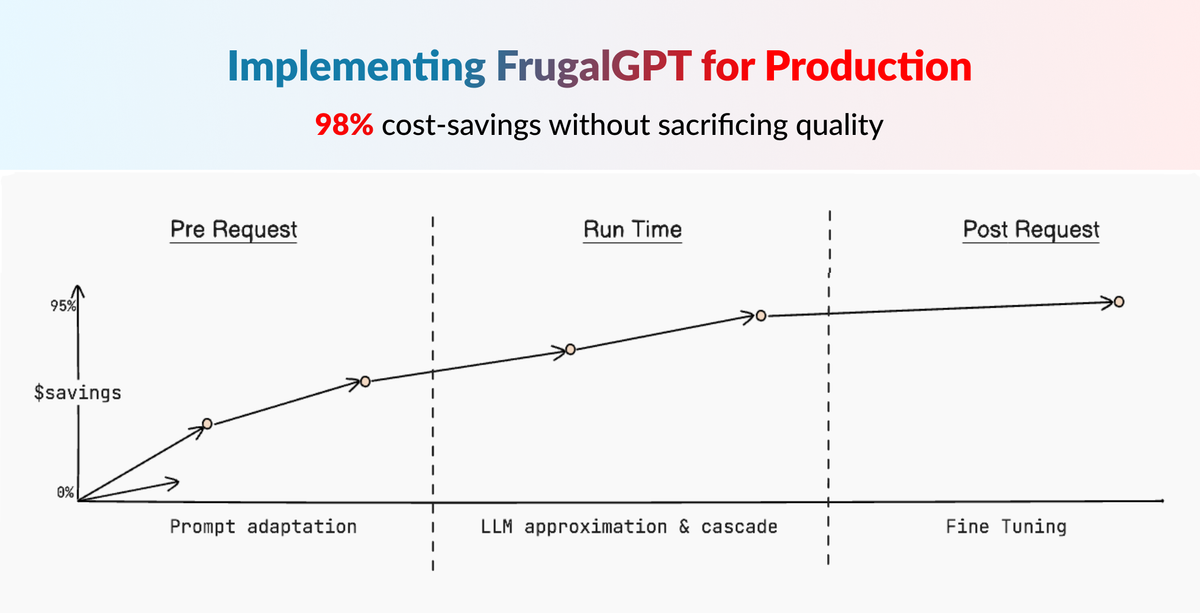
⭐️ Implementing FrugalGPT: Reducing LLM Costs & Improving Performance
FrugalGPT is a framework proposed by Lingjiao Chen, Matei Zaharia, and James Zou from Stanford University in their 2023 paper "FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance". The paper outlines strategies for more cost-effective and performant usage of large language model (LLM) APIs.
A year after its initial publication, FrugalGPT remains highly relevant and widely discussed in the AI community. Its enduring popularity stems from the pressing need to make LLM API usage more affordable and efficient as these models grow larger and more expensive.
The core of FrugalGPT revolves around three key techniques for reducing LLM inference costs:
- Prompt Adaptation - Using concise, optimized prompts to minimize prompt processing costs
- LLM Approximation - Utilizing caches and model fine-tuning to avoid repeated queries to expensive models
- LLM Cascade - Dynamically selecting the optimal set of LLMs to query based on the input
The authors demonstrate the potential of these techniques, showing that
"FrugalGPT can match the performance of the best individual LLM (e.g. GPT-4) with up to 98% cost reduction or improve the accuracy over GPT-4 by 4% with the same cost."
In this post, we'll delve into the practical implementation of these FrugalGPT strategies. We'll provide concrete code examples of how you can employ prompt adaptation, LLM approximation, and LLM cascade in your own AI applications to get the most out of LLMs while managing costs effectively. By adopting FrugalGPT techniques, you can significantly reduce your LLM operating expenses without sacrificing performance.
Let's put the theory of FrugalGPT into practice:
1. Prompt Adaptation
FrugalGPT wants us to either reduce the size of the prompt OR combine similar prompts together. The core idea is to minimize tokens and thus reduce LLM costs.
1.1 Decrease the prompt size
FrugalGPT proposes that instead of sending a lot of examples in a few-shot prompt, we could pick and choose the best ones, and thus reduce the prompt size.
While some larger models today don't necessarily need few-shot prompts, the technique does significantly increase accuracy across multiple tasks.
Let's take a classification example where we want to classify our incoming email based on the body into folders - Personal, Work, Events, Updates, Todos.
A few-shot prompt would look something like:
[{"role": "user", "content": "Identify the intent of incoming email by it's summary and classify it as Personal, Work, Events, Updates or Todos"},
{{examples}},
{"role": "user", "content": "Email: {{email_body}}"}]Where the examples would be formatted as human, assistant chats duets like this
[{"role": "user", "content": "Email: Hey, this is a reminder from your future self to take flowers home today"},
{"role": "assistant", "content": "Personal, Todos"}]
We have 20 such examples labeled already that we use as examples in this table
| email_body | labels |
|---|---|
| Hey, this is a reminder from your future self to take flowers home today | Personal, Todos |
| Your subscription to our newsletter will expire soon. Renew now for exclusive offers! | Updates |
The prompt with 20 examples is approximately 623 tokens and would cost 0.1 cents per request on gpt-3.5-turbo. Also, we might want to keep adding examples when emails are mislabeled to improve accuracy. This would further increase the cost of the prompt tokens.
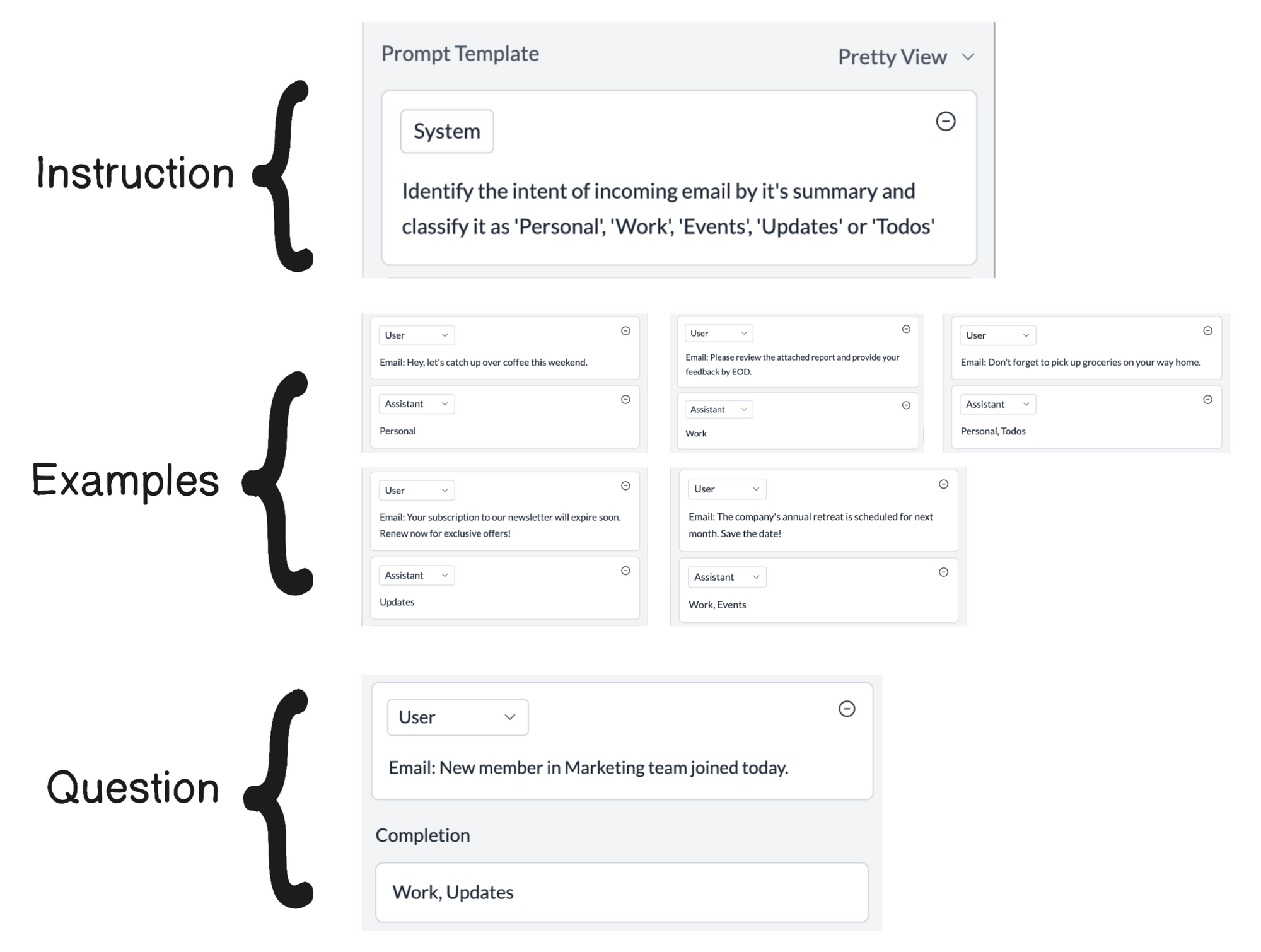
FrugalGPT suggests identifying the best examples to be used instead of all of them.
In this case, we could do a semantic similarity test between the incoming email and the example email bodies. Then, only pick the top k similar examples.
import numpy as np
from sklearn.metrics.pairise import cosine_similarity
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
def get_embeddings(texts):
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
with torch.no_grad():
model_output = model(**encoded_input)
embeddings = model_output.last_hidden_state[:, 0, :]
return embeddings.numpy()
# Assuming examples is a list of dictionaries with 'email_body' and 'labels' keys
example_embeddings = get_embeddings([ex['email_body'] for ex in examples])
def select_best_examples(query, examples, k=5):
query_embedding = get_embeddings([query])[0]
similarities = cosine_similarity([query_embedding], example_embeddings)[0]
top_k_indices = np.argsort(similarities)[-k:]
return [examples[i] for i in top_k_indices]
# Example usage
query_email = "Don't forget our lunch meeting at the new Italian place today at noon!"
best_examples = select_best_examples(query_email, examples)
few_shot_prompt = generate_prompt(best_examples, query_email) # Omitted for brevity
# Few-shot prompt now contains only the most relevant examples, reducing token count and costIf we pick only the top 5, we reduce our prompt token cost to 0.03 cents which is already a 70% reduction.
This is a great technique when using few-shot prompts for high accuracy. In production scenarios, this works really well.
1.2 Combine similar requests together
LLMs have been found to retain context for multiple tasks together and FrugalGPT proposes to use this to group multiple requests together thus decreasing the redundant prompt examples in each request.
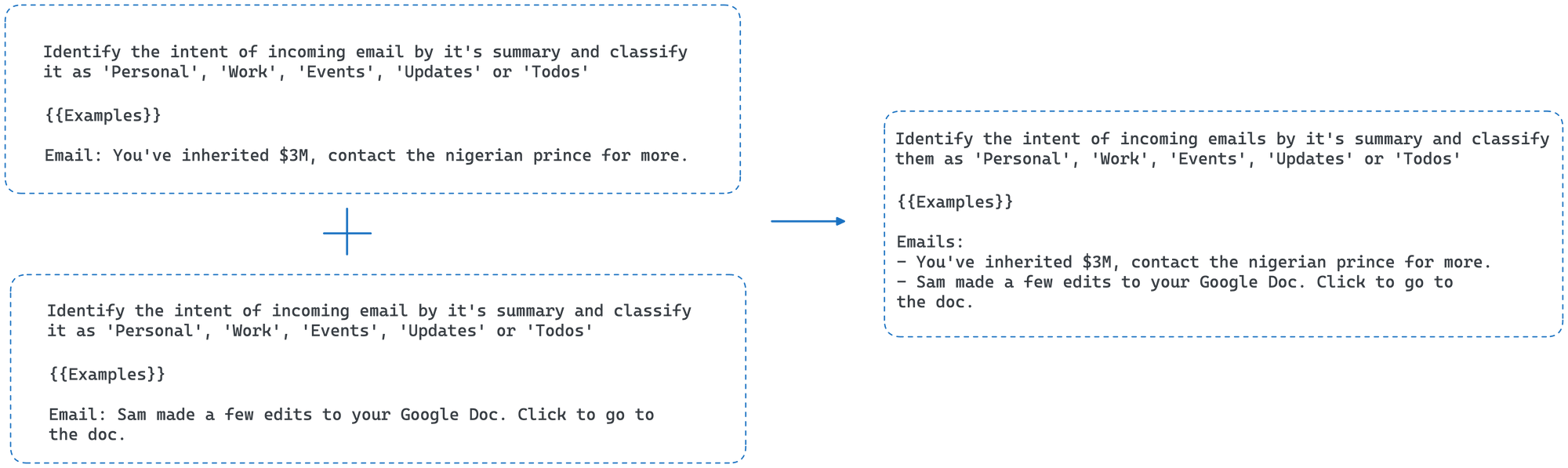
Using the same example as above, we could now try to classify multiple emails in a single request by tweaking the prompt like this:
[
{"role": "user", "content": "Identify the intent of the incoming emails by it's summary and classify it as 'Personal', 'Work', 'Events', 'Updates' or 'Todos'"},
{{examples}},
{"role": "user", "content": "Emails:\n - {{email_body_1}}\n - {{email_body_2}}\n - {{email_body_3}}"}
]
And similarly, modify the examples also to be in batches of 2 & 3.
This reduces the cost for 3 requests from 0.06 cents to 0.03 cents in a 50% decrease.
This approach is particularly useful when processing data in batches using a few-shot prompt.
Bonus 1.3: Better utilize a smaller model with a more optimized prompt
There may be certain tasks that can only be accomplished with bigger models. This is because prompting a bigger model is easier or also because you can write a more general-purpose prompt, do zero-shot prompting without giving any examples, and still get reliable results.
If we can convert some zero-shot prompts for bigger models into few-shot prompts for smaller models, we can get the same level of accuracy at a faster, cheaper rate.
Matt Shumer proposed an interesting way to use Claude Opus to convert a zero-shot prompt into a few-shot prompt which could then be run on a much smaller model without a significant decrease in accuracy.
This can lead to significant savings in both latency & cost. For the example Matt used, the original zero-shot prompt contained 281 tokens and was optimized for Claude-3-Opus, which cost 3.2 cents.
When converted to a few-shot prompt with enough instructions, the prompt size increased to 1600 tokens. But, since we could now run this on Claude Haiku, our overall cost for the request was reduced to 0.05 cents, representing a 98.5% percent cost reduction with a 78% percent speed up!
The approach works well across XXL and S-sized models. Check out a more general-purpose notebook here.
Bonus 1.4: Compress the prompt
The LLMLingua paper published in April 2024 talks about an interesting concept to reduce LLM costs called prompt compression. Prompt compression aims to shorten the input prompts fed into LLMs while preserving the key information, to make LLM inference more efficient and less costly.
LLMLingua is a task-agnostic prompt compression method proposed in the paper. It works by estimating the information entropy of tokens in the prompt using a smaller language model like LLaMa-7B and then removing low-entropy tokens that contribute less to the overall meaning. The authors demonstrated that LLMLingua can achieve compression ratios of 2.5x-5x on datasets like MeetingBank, LongBench, and GSM8K. Importantly, the compressed prompts still allow the target LLM (e.g. GPT-3.5-Turbo) to produce outputs comparable in quality to using the original full-length prompts.
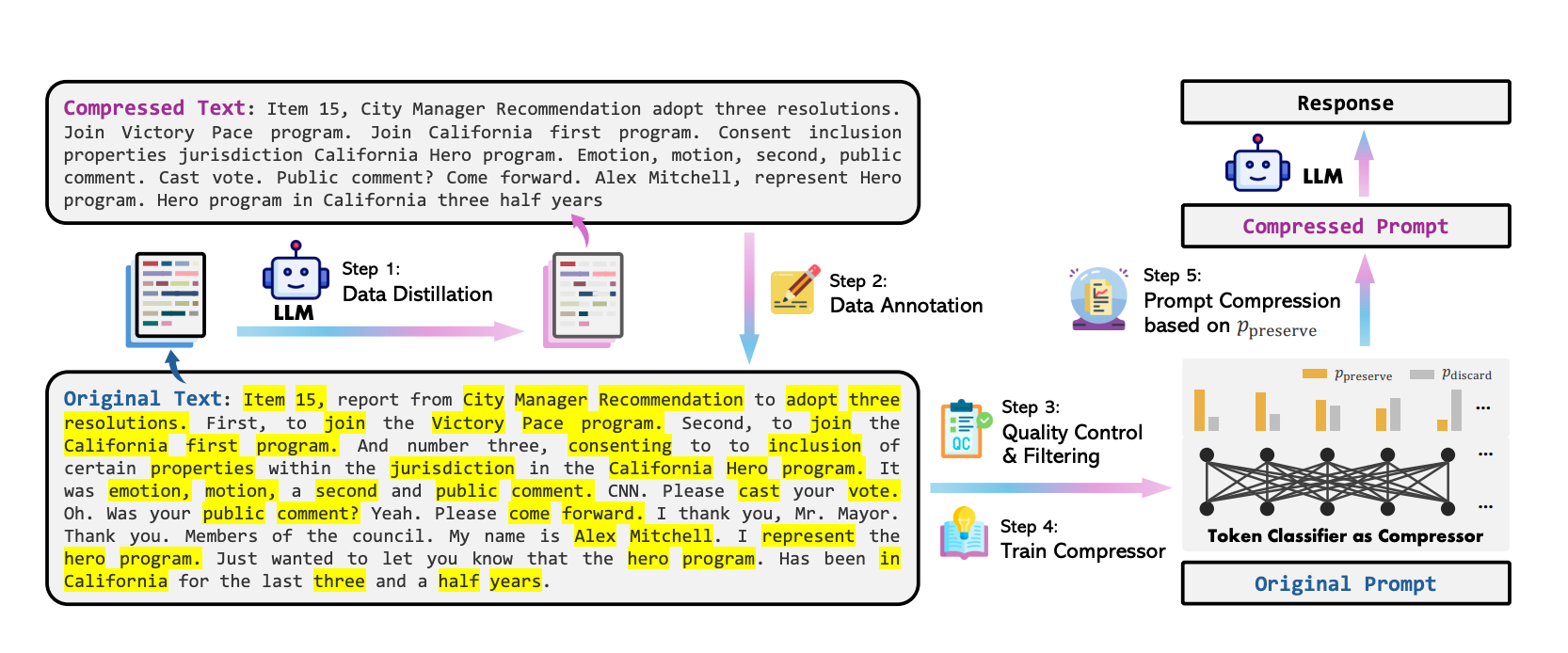
By reducing prompt length through compression techniques like LLMLingua, we can substantially cut down on the computational cost and latency of LLM inference, without sacrificing too much on the quality of the model's outputs. This is a promising approach to make LLMs more practical and accessible for various AI applications. As research on prompt compression advances, we can expect LLMs to become more cost-efficient to deploy and use at scale.
2. LLM Approximation
LLM approximation is another key strategy proposed in FrugalGPT for reducing the costs associated with querying large language models. The idea is to approximate an expensive LLM using cheaper models or infrastructure when possible, without significantly sacrificing performance.
2.1 Cache LLM Requests
The age-old technique to reduce costs applies to LLM requests as well. When the prompt is exactly the same, we can save the inference time and cost by serving the request from the cache.
At Portkey, we've seen that adding a cache to a co-pilot, on average results in 8% cache hits with 99% cost savings, along with a 95% decrease in latency.
If using the Portkey AI gateway, you can turn on the cache by adding the cache object to your gateway configuration.
"cache": {
"mode": "simple",
"max-age": "3600"
}
The generative AI twist to this is an emerging technique called Semantic Caching. It's an intelligent way to find similar prompts we've seen in the past and if the threshold is high enough, we could serve the response through a semantic cache.

At Portkey, we've seen that upgrading to semantic cache, on average results in a 21% cache hit rate with a 95% decrease in costs and latency! In some cases, we've seen semantic cache efficiencies to be as high as 60% 🤯
If using the Portkey AI gateway, you can upgrade to a semantic cache.
"cache": {
"mode": "semantic",
"max-age": "3600"
}
Caveats with caching in production
Having served over 250M cache requests, we've developed an understanding of some of the caveats to keep in mind while implementing a cache in production:
- Cache can leak data
We've built a lot of RBAC rules around databases so a user cannot access the data of another user. This falls flat in a cache since a user could try to mock the request of another user and access information from the LLM cache.
To avoid this, on Portkey, you can add metadata keys to your requests and partition the cache as per user/org/session/etc to ensure that the cache store for each metadata key is separate. - Semantic similarity threshold cannot be arbitrary
While getting started with a 0.95 similarity threshold is a good place to start, it's advisable to do a backtest with ~5k requests and test the similarity threshold at which accuracy stays above 99%. After all, we wouldn't want to supply incorrect replies in the name of cost savings! - We could be caching the wrong results
Since LLMs are probabilistic, the responses can be unsatisfactory at times. Caching these results would only lead to more frustration as the wrong response will be served again and again.
To solve this, it's recommended to create a workflow where you force refresh the cache when the user gives negative feedback (like a thumbs down) or clicks on refresh/regenerate. In Portkey, you can implement this using theforce-refreshconfig parameter.
2.2 Fine-tune a smaller model in parallel
We know that switching to smaller models decreases inference cost and latency. But, this is usually at the expense of accuracy. Fine-tuning is a very effective middle ground, where you can train a smaller model on a specific task and have it perform as well or even better than the larger model.
In a production environment, it can be massively beneficial to keep serving requests through a bigger model while continuously logging and fine-tuning a smaller model on those responses. We can then evaluate the results from the fine-tuned model and the larger model to determine when it makes sense to switch.
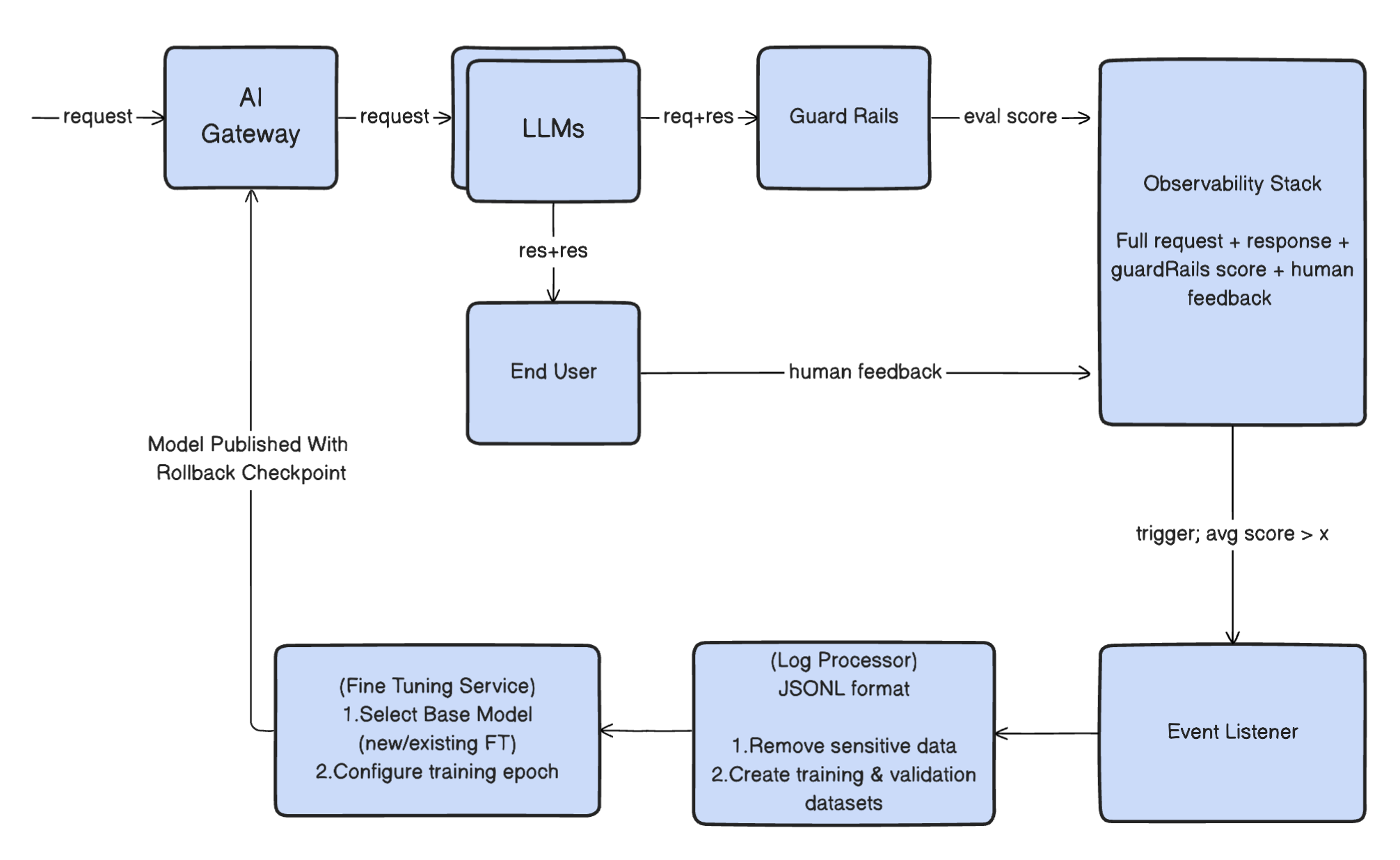
We've observed cost decreases of as much as 94% percent without a large accuracy decline. The latency also decreases significantly, thus improving user satisfaction.
Note: As with caching, its beneficial to use human feedback when picking the examples to fine-tune the smaller model.
In Portkey, you can create an autonomous fine-tune using these principles.
- Pick the model you want to fine-tune across providers.
- Select the training set for the model from the filtered Portkey logs. We add filters to only pick successful requests (Status: 200) and where the user gave positive feedback (Avg Weighted Feedback > 0)
- Pick the validation dataset (optional)
- Start the fine-tune
- Set a frequency to automatically keep improving the model - Portkey can use the filter criteria to continuously add more training examples to your fine-tuned model and create multiple checkpoints for the same.
3. LLM Cascade
The LLM cascade is a powerful technique proposed in FrugalGPT that leverages the diversity of available LLMs to optimize for both cost and performance. The key idea is to sequentially query different LLMs based on the confidence of the previous LLM's response. If a cheaper LLM can provide a satisfactory answer, there's no need to query the more expensive models, thus saving costs.
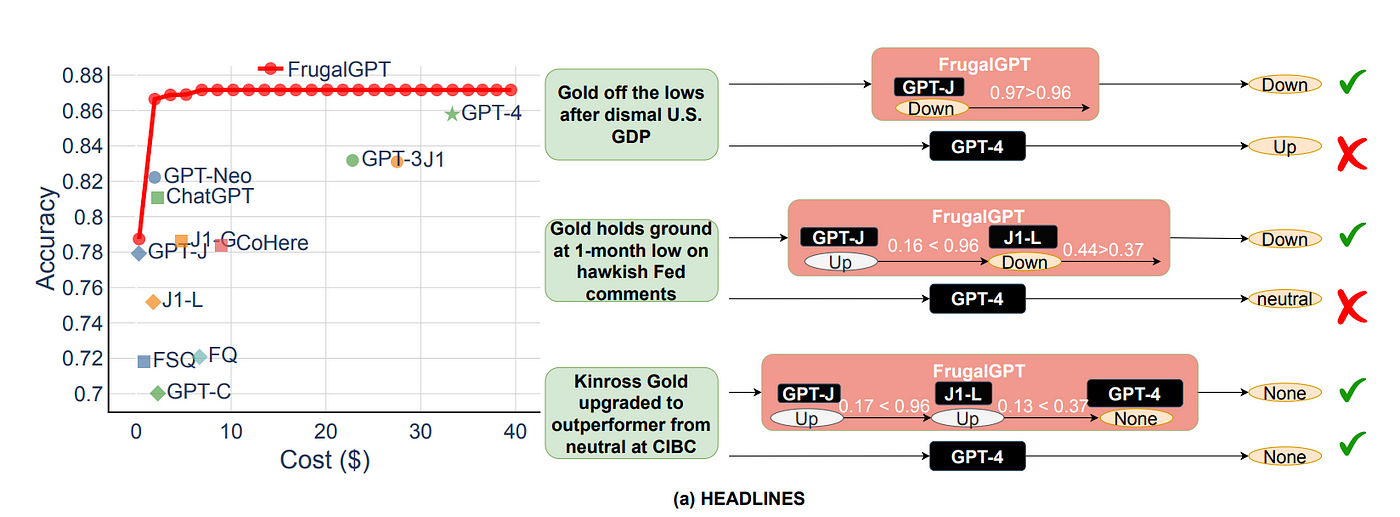
In essence, the LLM cascade makes a request to the smallest model first, evaluates the response, and returns it if it's good enough. Otherwise, it requests the next larger model and so on until a satisfactory response is obtained or the largest model is reached.
The LLM cascade consists of two main components:
- Generation Scoring Function: This function, denoted as
g(q, a), assigns a reliability score between 0 and 1 to an LLM's responseafor a given queryq. It helps determine if the response is satisfactory or if we need to query the next LLM in the cascade. - LLM Router: The router is responsible for selecting the optimal sequence of
mLLMs to query for a given task. It learns this sequence by optimizing for a combination of cost and performance on a validation set.
Let's see how we can implement an LLM cascade in practice. We'll continue with our email classification example from earlier.
Suppose we have access to three LLMs: GPT-J (lowest cost), GPT-3.5-Turbo (medium cost), and GPT-4 (highest cost). Our goal is to classify incoming emails into the categories: Personal, Work, Events, Updates, or Todos.
First, we need to train our generation scoring function. We can use a smaller model like DistilBERT for this. The input to the model will be the concatenation of the query (email body) and the generated classification. The output is a score between 0 and 1 indicating confidence in the classification.
from transformers import pipeline
scorer = pipeline("text-classification", model="distilbert-base-uncased-finetuned-sst-2-english")
def generation_score(query, generated_class):
input_text = f"Email: {query} \Generated Class:\n {generated_class}"
score = scorer(input_text)[0]['score']
return score
Next, we need to learn the optimal LLM sequence and threshold values for our cascade. This can be done by evaluating different combinations on a validation set and optimizing for a given cost budget.
def evaluate_cascade(llm_sequence, threshold_values, val_set, cost_budget):
total_cost = 0
correct_predictions = 0
for email, true_class in val_set:
for llm, threshold in zip(llm_sequence, threshold_values):
generated_class = llm(email)
score = generation_score(email, generated_class)
total_cost += llm_cost[llm]
if score > threshold:
if generated_class == true_class:
correct_predictions += 1
break
accuracy = correct_predictions / len(val_set)
return accuracy, total_cost
# Optimize for llm_sequence and threshold_values using techniques like grid search
best_llm_sequence, best_threshold_values = optimize(evaluate_cascade, cost_budget)
With the trained scoring function and optimized LLM cascade, we can now efficiently classify incoming emails:
def classify_email(email):
for llm, threshold in zip(best_llm_sequence, best_threshold_values):
generated_class = llm(email)
score = generation_score(email, generated_class)
if score > threshold:
return generated_class
return generated_class # Return the final LLM's prediction
By implementing an LLM cascade, we can dynamically adapt to each query, using more powerful LLMs only when necessary. This allows us to optimize for both cost and performance on a per-query basis.
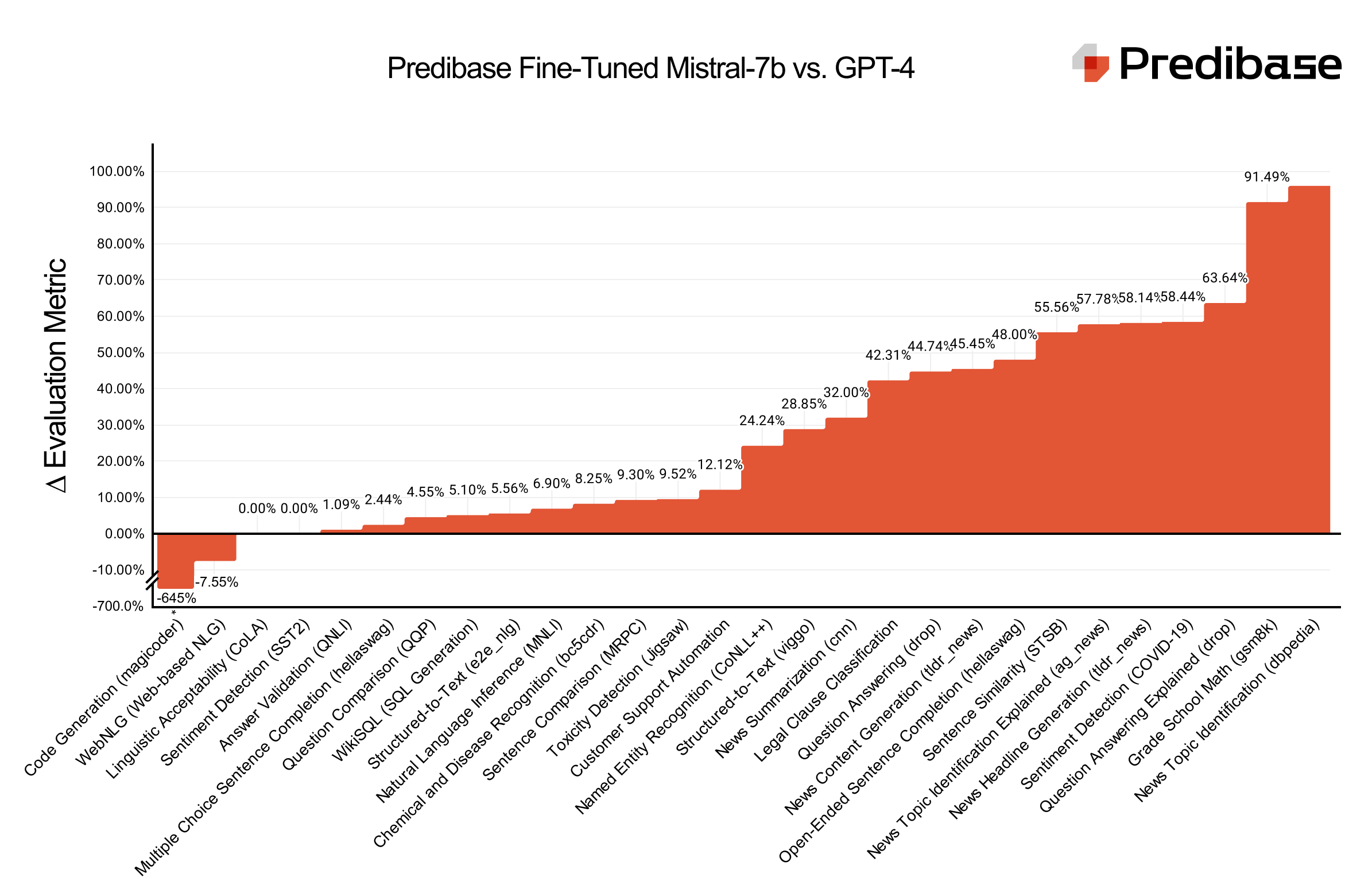
In their experiments, the FrugalGPT authors show that an LLM cascade can match GPT-4's performance while reducing costs by up to 98% on some datasets.
All Together Now
In conclusion, FrugalGPT offers a comprehensive set of strategies for optimizing LLM API usage while reducing costs and maintaining high performance. By implementing techniques such as prompt adaptation, LLM approximation, and LLM cascade, developers and businesses can significantly reduce their LLM operating expenses without compromising on the quality of their AI-powered applications.
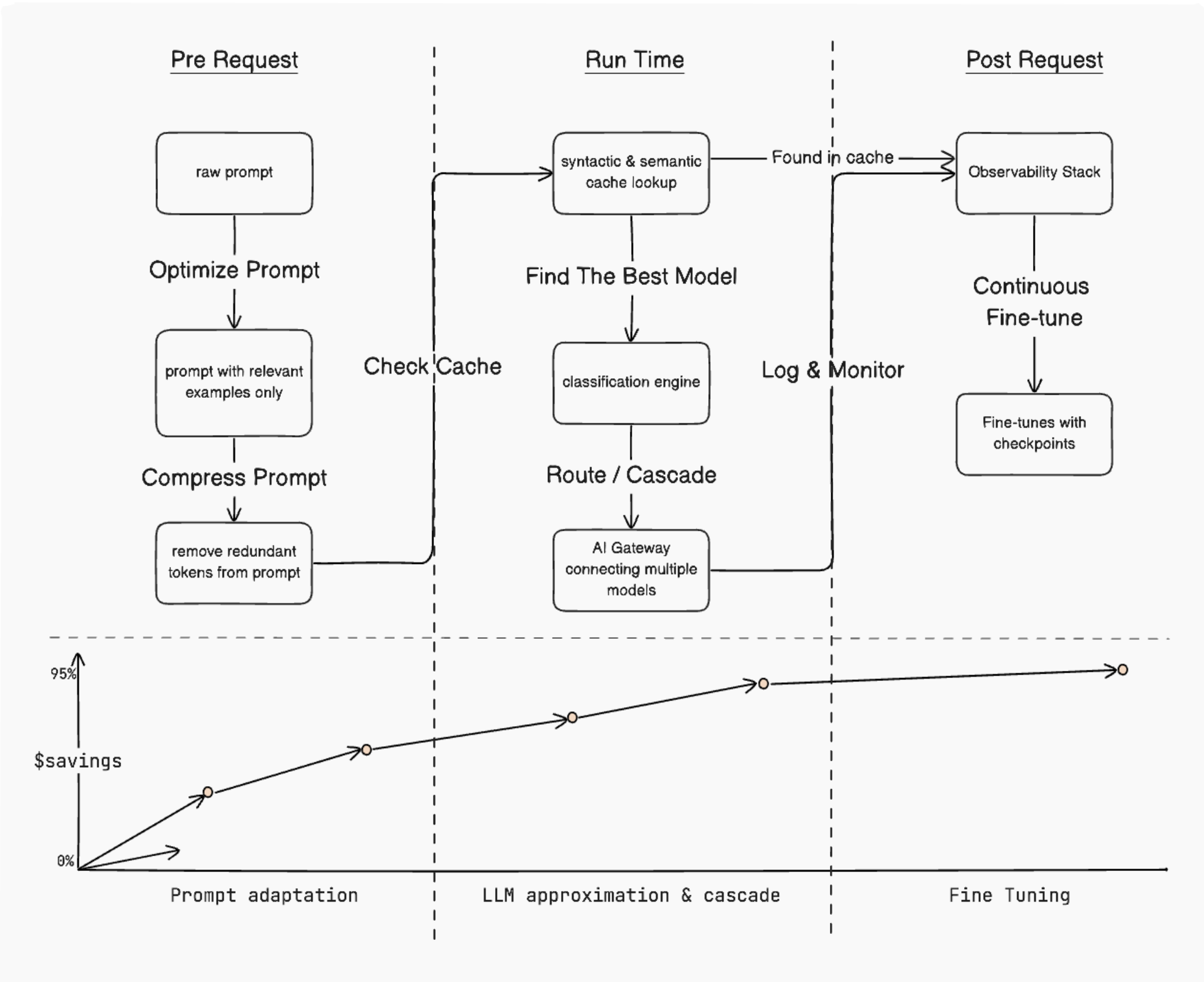
The practical examples and code snippets provided in this post demonstrate how to put FrugalGPT's theory into practice. By adopting these techniques and adapting them to your specific use case, you can create more efficient, cost-effective, and performant LLM-based solutions.
As LLMs continue to grow in size and capability, the strategies proposed in FrugalGPT will become increasingly important for ensuring the accessibility and sustainability of these powerful tools.
Get Started Today
You can put FrugalGPT's core principles into practice using Portkey's product suite for observability, gateway, and fine-tuning:

To meet other practitioners and engineers who are pushing the boundaries of what’s possible with LLMs, join our close-knit community of practitioners putting LLMs in Prod: