

⭐️ Getting Started with Llama 2
Llama 2 is an open-source large language model (LLM) developed by Meta. See Llama 2's capabilities, comparisons, and how to run LLAMA 2 locally using Python.

It's been some time since Llama 2's celebrated launch and we've seen the dust settle a bit and real use cases come to life.
In this blog post, we answer frequently asked questions on Llama 2's capabilities and when should you be using it. Let's dive in!

What is Llama 2?
Llama 2 is an open-source large language model (LLM) developed by Meta. It is freely available for research and commercial purposes. Llama 2 is a family of LLMs, similar to OpenAI's GPT models and Google's PaLM models.
It can generate incredibly human-like responses by predicting the most plausible follow-on text using its neural network, which consists of billions of parameters.
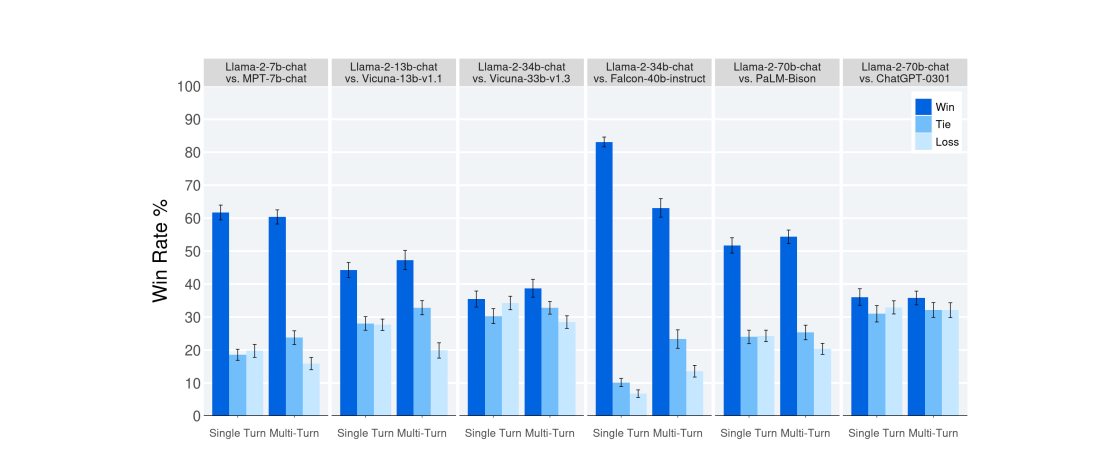
It's gaining popularity as benchmarks and human tests both show it to be performing as well as the OpenAI models, with the added advantage of it being completely open source.
That means players like Perplexity can tweak and deploy a version of Llama 2 for you to try out with no restrictions! Neat.
Can I use Llama 2 instead of OpenAI's model?
Yes, you can use Llama 2 instead of OpenAI's model. Llama 2 is an open-source large language model (LLM) developed by Meta AI, and it is freely available for research and commercial use. Llama 2 has been shown to have higher performance than OpenAI's ChatGPT, but lower performance than OpenAI's GPT-4.
Is LLaMA 2 Open Source?
LLaMA 2, developed by Meta, is often touted as an open-source alternative to proprietary large language models. However, while it is more accessible than many of its competitors, calling it fully open-source requires some nuance.
LLaMA 2 is freely available for research and commercial use but with certain conditions. Meta has released the model weights and code under a custom license rather than a standard open-source license like Apache or MIT. This license includes restrictions, such as prohibiting usage by organizations exceeding a specified number of active monthly users or those directly competing with Meta.
Despite these restrictions, LLaMA 2 represents a significant step toward democratizing access to advanced AI. By providing model weights, fine-tuning capabilities, and inference resources, Meta has enabled developers and enterprises to experiment, innovate, and deploy state-of-the-art LLMs without needing to rely on black-box APIs. This makes LLaMA 2 an attractive option for organizations seeking transparency, cost control, and customization.
In essence, LLaMA 2 exists in a hybrid space—more open than proprietary models like GPT-4 but not as unrestricted as truly open-source projects. For enterprises and researchers, it strikes a balance between accessibility and control while maintaining a layer of safeguards for ethical and competitive use.
What are the differences between Llama 2 and OpenAI's models?
- Size: Llama 2 is a much smaller model than OpenAI's flagship models.
- Performance: Llama 2 has been shown to have slightly higher performance than OpenAI's ChatGPT, but lower performance than OpenAI's GPT-4.
- Data: Llama 2 offers more up-to-date data than its OpenAI counterpart.
- Availability: Llama 2 is open-source and freely available for research and commercial use, while OpenAI's models are not.
| Reasons to prefer Llama2 | Reasons to prefer OpenAI |
|---|---|
| Accessibility: Llama 2 is open-source and available for free, while OpenAI's models are proprietary and require payment. | Size and power: OpenAI's models are much larger and more powerful than Llama 2. |
| Safer outputs: Llama 2 has been shown to generate safer outputs than OpenAI's ChatGPT. | Performance: OpenAI's models have been shown to have higher performance than Llama 2. |
| Up-to-date data: Llama 2 offers more up-to-date data than its OpenAI counterpart. | Availability: OpenAI's models are widely used in the industry and have a larger community of developers and users. They're also accessible via an API without the need to deploy your own models. |
| Customizability: Llama 2 can be fine-tuned for specific tasks and domains, making it more customizable than OpenAI's models. | Simpler Fine-tuning: While Llama2 provides more flexibility, OpenAI has launched a very simple way of continuously fine-tuning GPT-3.5. GPT-4 fine-tuning is on the way. |
| Ethical considerations: Llama 2 is developed by Meta AI, a company that emphasizes ethical considerations in AI development. |
Overall, Llama 2 is a viable alternative to OpenAI's models, especially for those who require up-to-date data, prefer an open-source solution, and prioritize ethical considerations. However, OpenAI's models are still more powerful and widely used in the industry.
How do I use Llama 2?
You can try Llama 2's models on llama2.ai (hosted by Replicate), ChatNBX, or via Perplexity.
Is there an API for Llama 2?
Yes, you can access Llama 2 models through various platforms that provide a Llama 2 API, or by creating an inference endpoint for Llama 2’s models by deploying it to your hardware
Azure provides Llama2 support in its model catalog
- If you prefer AWS, they have also announced support through SageMaker Jumpstart.
- The easiest way to get started would be through Anyscale's hosted endpoints which host the model for you in a fast & extremely cost-efficient environment.
curl "$OPENAI_API_BASE/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "meta-llama/Llama-2-70b-chat-hf",
"messages": [{"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Say 'test'."}],
"temperature": 0.7
}'Are there multiple versions of Llama 2?
Yes, Llama 2 has pre-trained models, fine-tuned chat models, and code models made available by Meta.
Pre-trained Models: These models are not fine-tuned for chat or Q&A. They should be prompted so that the expected answer is the natural continuation of the prompt. There are 3 models in this class - llama-2-7b, llama-2-13b and the most capable llama-2-70b.
Fine-tuned Chat Models: The fine-tuned models were trained for dialogue applications. These also come in 3 variants - llama-2-7b-chat, llama-2-13b-chat and llama-2-70b-chat
Code Models: Code Llama is a code-specialized version of Llama 2 that was created by further training Llama 2 on its code-specific datasets. Meta released three sizes of Code Llama with 7B, 13B, and 34B parameters respectively.
The community has also made many more models available on top of Llama 2:
Uncensored models: If you want to turn off safe mode on Llamas, you can try these
-
llama2-uncensored(Uncensored Llama2 model by George Sung and Jarrad Hope), Nous-Hermes-Llama2-13b(state-of-the-art language model fine-tuned on over 300,000 instructions),Wizard-Vicuna-13B-Uncensored(trained with a subset of the dataset - responses that contained alignment/moralizing were removed.)
Many more specialized models can be seen on the Ollama website.
Limitations of LLaMA 2
While LLaMA 2 is a powerful language model with numerous capabilities, it has several limitations that developers and enterprises should consider:
1. Restricted Licensing
- Llama 2’s license imposes restrictions on its use, particularly for organizations with over 700 million active monthly users or those competing directly with Meta. This limits its adoption in large-scale, commercial settings or industries where Meta is a competitor.
2. Computational Requirements
- Running LLaMA 2, especially the larger variants, requires significant computational resources, including high-end GPUs and substantial memory. This can make it costly to deploy for smaller organizations or on-premise setups.
3. Lack of Extensive Fine-Tuning Tools
- While fine-tuning LLaMA 2 is possible, the ecosystem around it is not as mature as some other models. Developers may find fewer out-of-the-box tools or frameworks optimized for LLaMA 2 compared to alternatives like GPT-4.
4. Knowledge Cutoff
- Similar to other large language models, LLaMA 2 is trained on data up to a certain point in time. It may lack awareness of recent events, updates, or domain-specific knowledge introduced after its training period.
5. Potential for Hallucinations
- LLaMA 2 can generate plausible-sounding but incorrect or misleading information. This is a common issue with LLMs and requires robust guardrails or human oversight to mitigate.
6. Ethical Concerns and Misuse
- Despite efforts to align the model with ethical guidelines, there is a risk of misuse, such as generating harmful content or propagating biases present in the training data.
7. Limited Out-of-the-Box Integrations
- Compared to proprietary solutions like OpenAI’s GPT models, LLaMA 2 may lack seamless integrations with popular APIs or platforms, requiring additional development effort.
8. Support and Updates
- Being an open-access model, LLaMA 2 does not come with dedicated support services. Enterprises relying on it need to depend on community resources or invest in their own troubleshooting and maintenance.
Advanced Topics
Can I run Llama2 on my local machine?
Yes, you can run Llama 2 on your local machine. To do this, you need to follow these steps:
- Install the required software: Make sure you have Python 3.8 or higher and Git installed on your system. You may also need a C++ compiler depending on your operating system.
- Clone the Llama 2 repository: Clone the Llama 2 repository from Hugging Face and install the required Python dependencies.
- Download the Llama 2 model: Download the Llama 2 model of your choice from the Meta AI website or Hugging Face, and place it in the appropriate directory.
- Create a Python script: Create a Python script to interact with the Llama 2 model using the Hugging Face Transformers library or other available libraries like llama-cpp-python.
- Run the script: Execute the Python script to interact with the Llama 2 model and generate text, translations, or answers to your questions.
For more detailed instructions and examples, you can refer to various guides available online, such as the ones on Replicate or Medium.
Can I fine-tune Llama2 on my own data?
Yes, you can fine-tune Llama 2 on your own dataset. Here's a quick guide to help you get started with the fine-tuning process:
Prerequisites:
- Machine Specifications: Ensure you have a machine equipped with a reasonably recent version of Python and CUDA. For a smooth experience, it's advisable to use Python 3.10 and CUDA 11.7 as utilized in the example.
- GPU Requirements: A GPU with at least 24GB of VRAM is recommended, such as A100, A10, or A10G. For fine-tuning the larger Llama 2 models, like the 13b and 70b, opting for the A100 is a smart choice to handle the substantial computational load.
Fine-Tuning Process:
The fine-tuning process is quite straightforward. Follow these essential steps to fine-tune Llama 2 on your data:
- Preparation: Gather and preprocess your dataset for the fine-tuning task.
- Configuration: Set up your machine and environment, ensuring all necessary software and hardware requirements are met.
- Fine-Tuning: Launch the fine-tuning process using the appropriate commands and settings.
- Evaluation: After fine-tuning, evaluate the model's performance on your tasks to ensure it meets your expectations.
For a comprehensive and detailed step-by-step guide on how to fine-tune Llama 2 on your own data, check out this helpful tutorial.

