
Load balancing in multi-LLM setups: Techniques for optimal performance
Load balancing is crucial for teams running multi-LLM setups. Learn practical strategies for routing requests efficiently, from usage-based distribution to latency monitoring. Discover how to optimize costs, maintain performance, and handle failures gracefully across your LLM infrastructure.
As businesses increasingly adopt large language models (LLMs) to power their applications, many are turning to multi-LLM setups to handle diverse workloads. Teams are combining different language models to handle their workloads - some for speed, others for specific tasks, and often a mix of both.
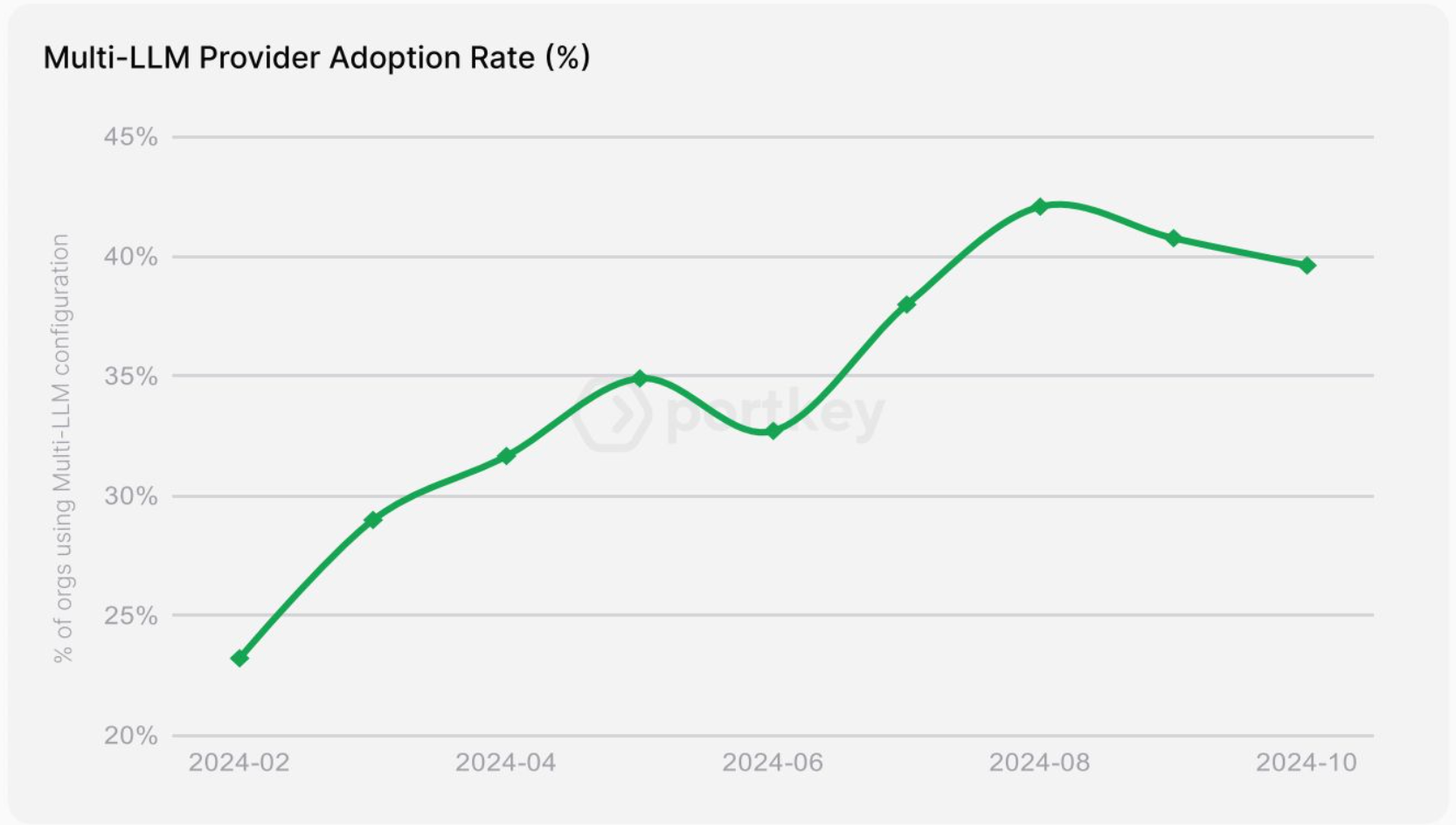
While this approach improves flexibility and performance, it also introduces challenges in efficiently distributing requests across models.
Why load balancing is critical for multi-LLM setups
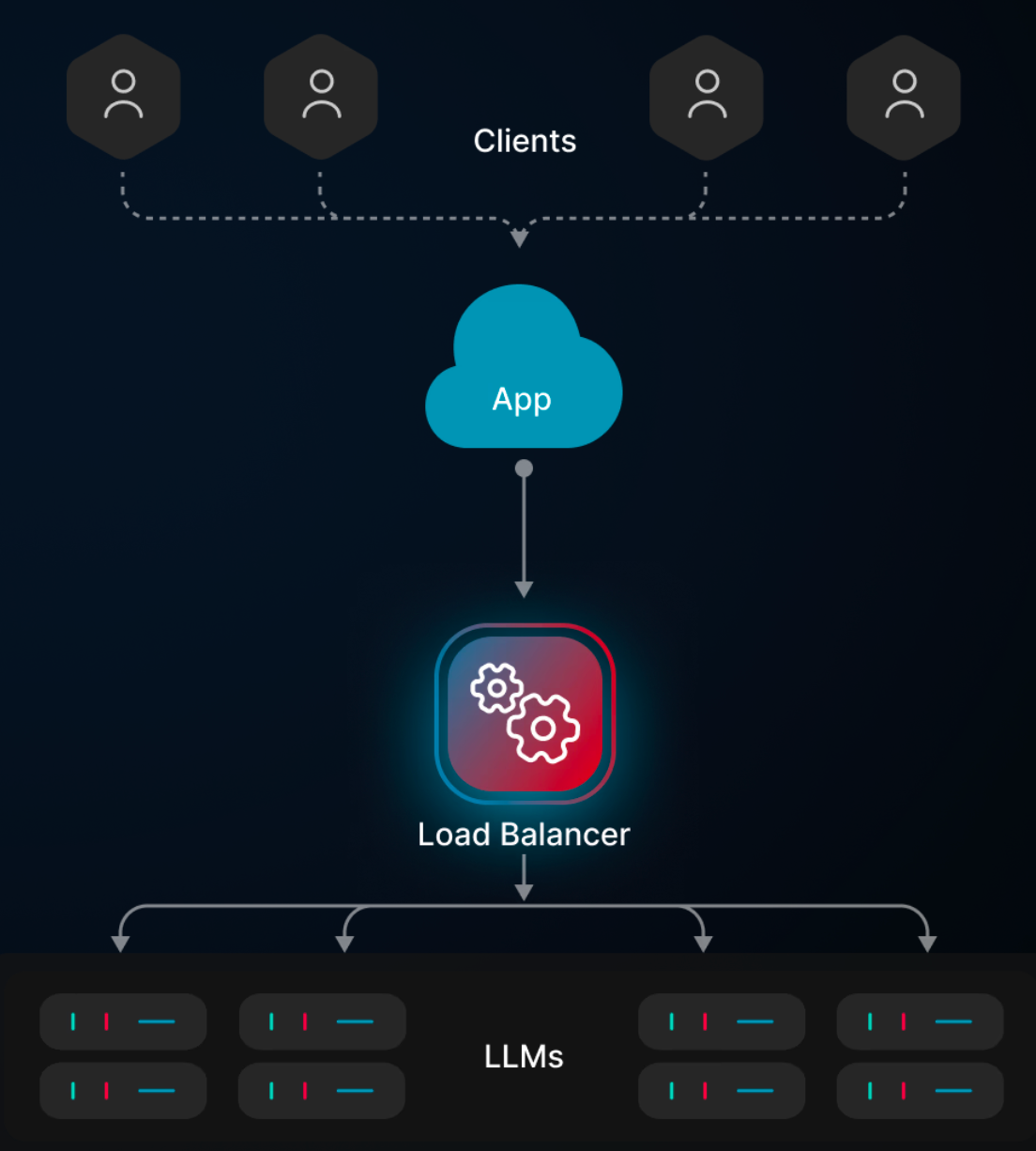
Running multiple LLMs effectively comes down to smart resource management. Requests flow in constantly, each needing different levels of processing power and specialized handling. Without proper load balancing, you'll quickly run into bottlenecks that ripple through your entire system.
The impacts show up immediately in your response times. A backlogged model means users waiting for responses, while other perfectly capable models sit idle. Beyond just the user experience hit, this creates unnecessary strain on your infrastructure and drives up costs, especially when premium models handle tasks that simpler ones could manage just as well.
Models can and do fail - they might slow down, throw errors, or need updates.
A well-balanced setup lets you handle these hiccups gracefully, routing traffic around problems while maintaining performance.
1. Usage-based routing
When you're juggling multiple LLMs, one of the most practical approaches is to route requests based on actual usage patterns.
Usage-based routing matches each request with the right model based on two key factors: the task's complexity and your defined usage limits. You might send straightforward tasks like text summarization to lighter, faster models while keeping your powerhouse models (like GPT-4) free for heavy lifting - things like complex reasoning or specialized domain tasks.
Setting this up takes some thoughtful planning. You'll need to add usage tracking to your orchestration layer so you can watch how each model is performing. The magic happens when you set up dynamic thresholds - automatic switches that kick in when a model nears its usage limits. When one model gets close to its quota, requests smoothly shift to another available model.
2. Latency-based routing
Latency-based routing directs requests to the model or endpoint with the lowest response time, ensuring minimal delay for users.
Building this system starts with setting performance baselines and watching response times in short windows, typically 5-15 minutes. Your monitoring system runs health checks every few seconds, but shouldn't overreact to brief speed changes. Using exponential moving averages helps smooth out temporary spikes while catching real slowdowns.
As one endpoint slows under heavy traffic, requests naturally flow to faster options. This keeps your system responsive and gives you breathing room to fix any issues. Even if all primary endpoints slow down, having fallback paths to simpler models means users still get responses, just from less complex models that can handle the load better.
3. Hybrid routing
Hybrid routing watches both your usage patterns and performance metrics, then makes smart calls about where to send each request. You might start with cost-saving rules, like keeping premium models under certain usage limits, but also factor in response times and current load.
The real power comes from how you tune it. Set up weighted parameters that let you lean more heavily toward cost savings or performance as needed. Build in those essential safety nets too - if one model hits issues, requests smoothly flow to others based on your predefined rules.
Key considerations for implementing load balancing in multi-LLM setups
Before writing any code, take a good look at your model lineup. Each LLM has its sweet spots and blind spots. Some excel at creative tasks, others at structured data analysis. Pick your mix based on what your app actually needs, not just what's popular. Having the right tools for each job means less strain on your system and happier users.
Watch how your traffic flows. Most apps have predictable patterns - maybe heavier loads during business hours or spikes around certain events. Understanding these patterns helps you set up routing that anticipates busy periods instead of just reacting to them. Look at your logs, spot the patterns, and adjust your routing rules accordingly.
Keep your eyes on the system once it's running. Set up monitoring that tells you exactly what's happening - how fast models are responding, how many requests they're handling, and where errors pop up. When something goes wrong (and it will), good monitoring helps you fix it before users notice.
Don't forget about Plan B (and C). Your system should handle hiccups gracefully. If one model slows down or fails, requests should automatically flow to backups. Test these failover paths regularly - they're like airbags, you hope you never need them, but they better work when you do.
Lastly, keep costs in check by being smart about caching and batching. Store common responses, group similar requests when possible, and route traffic efficiently. Small optimizations add up when you're running at scale.
How Portkey simplifies load balancing in multi-LLM setups
Managing multiple LLMs doesn't have to be a headache. Portkey's AI Gateway takes care of the heavy lifting, giving you a central place to handle all your LLM traffic.
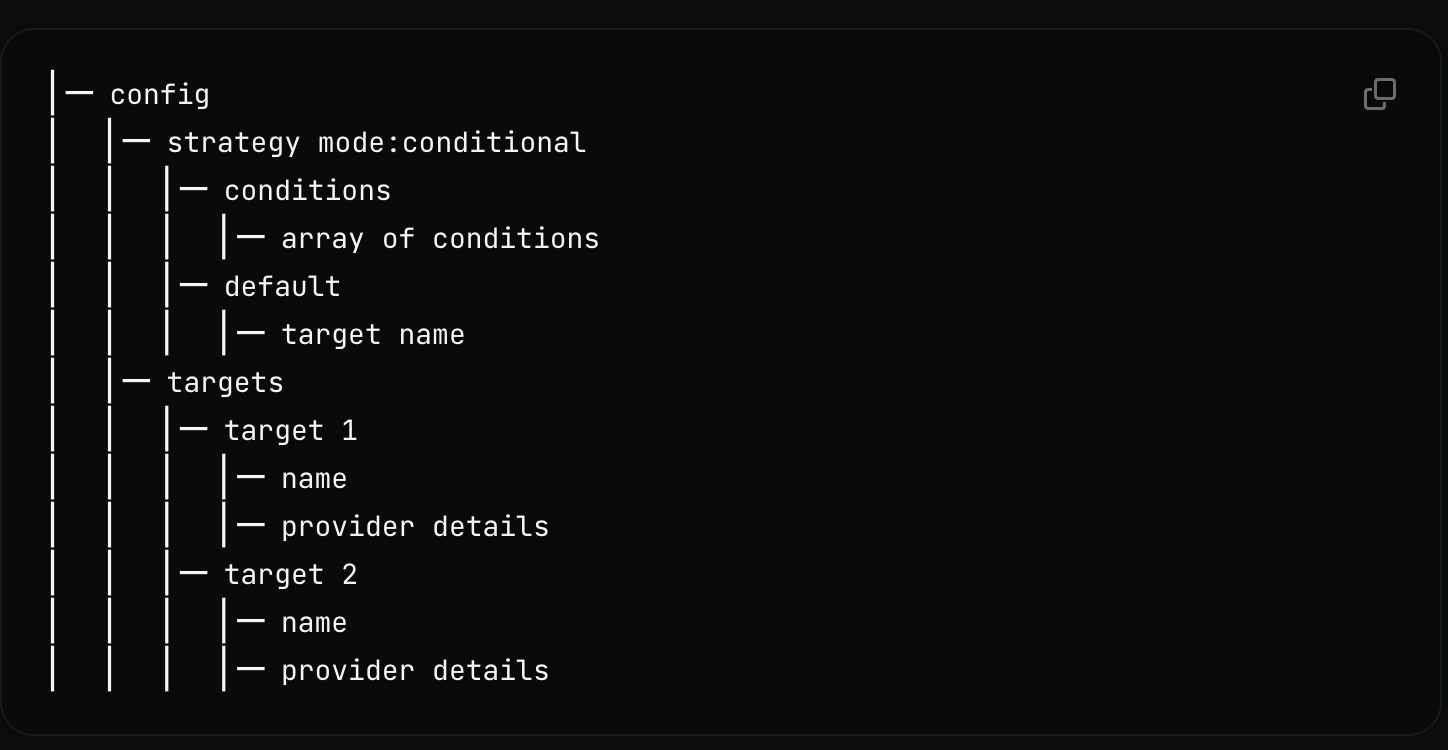
You can now smart rules for routing requests. Need to keep GPT-4 usage under a certain threshold? The system handles this automatically. You set the rules, and Portkey makes sure requests go to the right model at the right time.
Portkey's conditional routing goes beyond basic usage limits. You can tag your requests with metadata - any key-value pairs that make sense for your app - and route based on these tags.
The platform shows you exactly what's happening in your system through a real-time dashboard. You can see how each model performs, track response times, and spot potential issues before they become problems. This visibility helps you fine-tune your setup based on actual usage patterns rather than guesswork.
One standout feature is smart caching. If your app often makes similar requests, the platform stores those responses and serves them instantly when needed. This cuts down on both costs and wait times.
Setting up is straightforward - connect your LLM providers and start defining your routing preferences. Whether you're focused on keeping costs down, maximizing speed, or finding the sweet spot between the two, you can build workflows that match your needs.
Ready to optimize your multi-LLM setup? Explore how Portkey can help organize your workflows and improve performance.
