
LLM pricing is 100x harder than you think
LLM pricing is surprisingly difficult. We've tracked $180M in LLM spend across 3,500+ models. Here are the 6 hidden patterns that break cost attribution, the architecture we built to solve them, and we're open-sourcing all of it.
Earlier this month, we open-sourced Portkey's model pricing database - 3,500+ models across 50+ providers. The same data we use to attribute cost for enterprises processing trillion of tokens through Portkey's gateway every day.
Turns out, a lot of teams needed this.
The entire industry is focused on harness design, managed agents, model benchmark scores. Meanwhile, there's no common ground on something more fundamental: How do you actually attribute cost to model usage?
Think about it. Most projects maintain an in-house pricing database. A JSON file somewhere in your repo with model names and prices. OpenCode has one of these. So does OpenClaw, LibreChat, Pi, Theo's T3 code. I keep finding new ones.
The pattern is clear: everyone builds their own thing, it's accurate for a few weeks, then it drifts. There's no canonical source. No API you can just call. No dataset comprehensive enough to handle the weird edge cases.
Three years post-ChatGPT, there's still no standard way to calculate what a single request costs across providers.
At Portkey we've spent three years building the infrastructure for this. Here's everything we've learned, and we're releasing the full stack so you don't have to rebuild it yourself:
- Model Data + Free API: Updated daily, check it out on portkey.ai/models
- Portkey's Gateway: Open-source AI gateway with built-in pricing engine
Now let's talk about why this is still not solved.
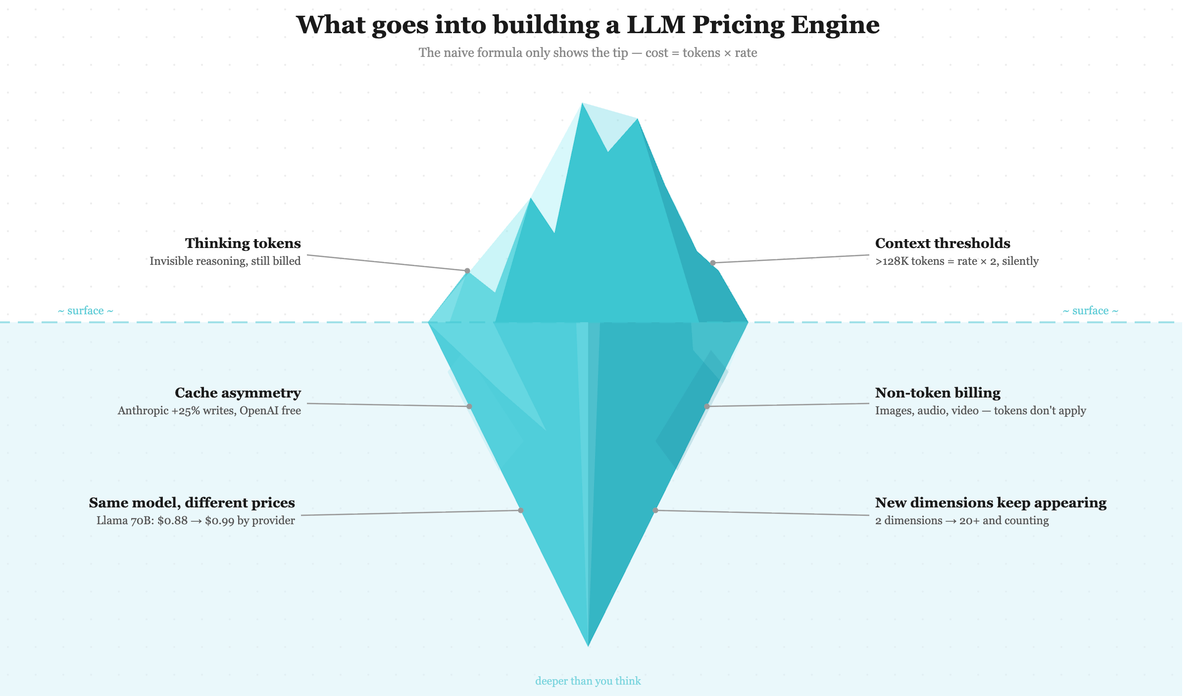
The 6 patterns that break pricing
These aren't edge cases. Every one of them has caused real cost discrepancies for teams using the models.
1. Thinking tokens
Reasoning models like o3 and Claude with extended thinking consume tokens for internal reasoning that never appear in the response. You still get charged for them.
OpenAI's o1-preview has a 4× output-to-input price ratio ($15/M input, $60/M output). Most of that gap is reasoning overhead. If your system only counts visible output tokens, you'll undercount agentic workloads by 30–40%.
2. Cache asymmetry
Prompt caching economics are different per provider in ways that matter.
Anthropic charges 25% more for cache writes ($3.75/M vs $3.00/M regular input), with reads at $0.30/M. OpenAI charges nothing for writes. Reads get discounted. If you apply a single "cache discount" multiplier across both, your numbers are wrong for at least one of them.
3. Context thresholds
OpenAI, Anthropic, and Google all have tiered pricing based on context length. Cross 128K tokens and per-token cost can double. $0.075/M becomes $0.15/M. Nothing in the API response tells you which tier you hit. The request just works. Your cost estimate is silently wrong.
4. Same model, different prices
Kimi K2.5 costs $0.5 input / 2.8$ output on Together AI, $0.6 input / 3$ output on Fireworks. You can't just track "Kimi K 2.5." You need "Kimi K 2.5 on Together AI."
And it gets worse: Bedrock prepends regional prefixes (us.meta.llama, eu.anthropic.claude-...) that need stripping before you can even look up the price. Azure returns deployment names instead of model identifiers. You need an extra API call to figure out what model you're running.
5. Non-token billing
DALL·E 3 bills by image quality and resolution. Video generation charges per second. Realtime audio has separate input/output rates. Embeddings are input-only. Fine-tuning is per-token on some models, per-hour on others. Each needs different fields from the request and maps to a completely different pricing structure.
6. New dimensions keep appearing
We started with two billing dimensions: input tokens and output tokens. Now there are over twenty. Web search has per-search pricing. Google's Grounding with Search has its own rate structure. Tool use, code execution - each ships with its own cost model, and new ones appear faster than providers update their documentation.
Why It Matters
Every enterprise wants to adopt AI. Making it actually work is another story. The moment you move past prototypes, cost attribution becomes a dealbreaker. It's impossible for a 1000+ person organization to adopt AI without knowing what their LLMs are costing them:
- FinOps goes blind. Teams running hundreds of model variants across departments need per-team, per-user cost breakdowns. When pricing is wrong, the AI budget becomes a single line item nobody can decompose or optimize.
- Margins become guesswork. If you're reselling LLM access, and increasingly everyone is, inaccurate cost data means you're either leaking money or overcharging customers. Both are bad.
- Budgets can't be enforced. You can set per-team and per-user spending limits, but limits only work if cost data is accurate. A model reporting $0 per request will never trip an alert, no matter how many tokens it consumes.
- Shipping slows down. Teams get blocked on AI features because nobody can answer "what will this cost at scale?" Model evaluations become finance negotiations instead of engineering decisions.
LLM cost attribution is not just a gateway-layer problem. Whether you're using AI tools or building them for the masses, accurate usage tracking isn't optional. It's a necessity.
How Portkey's Gateway handles this
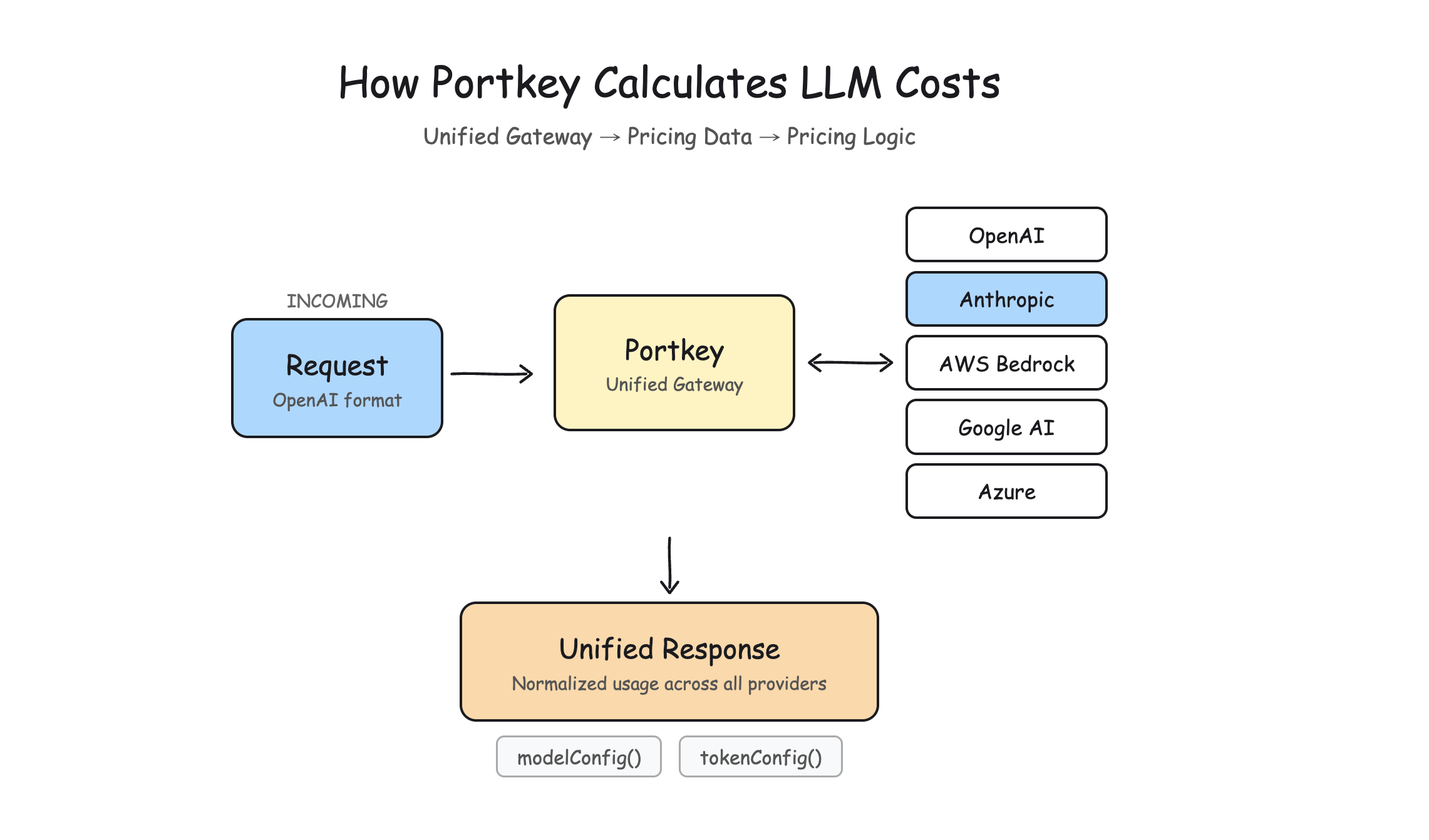
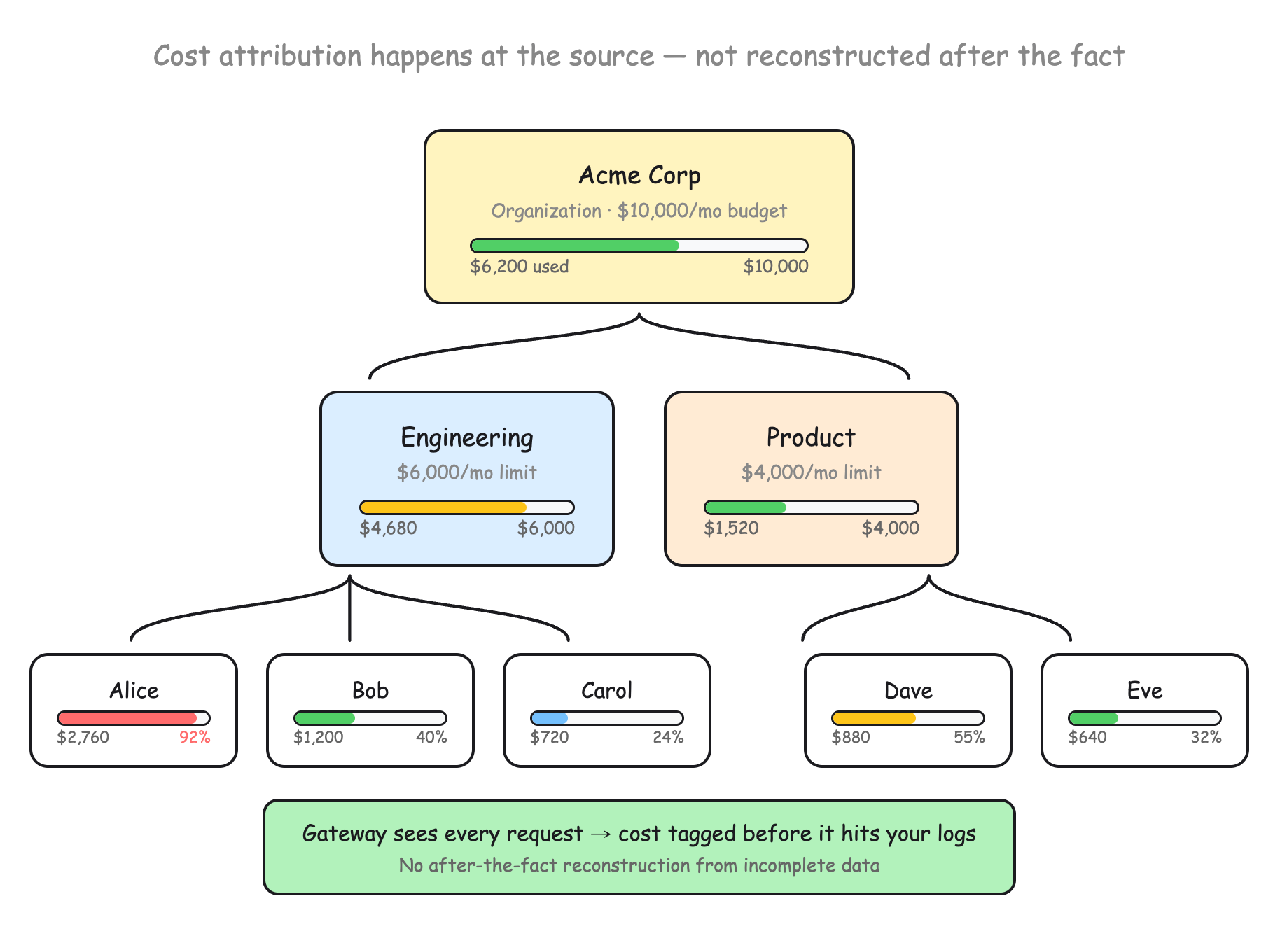
The gateway normalizes every provider response into a single cost structure. Model identifiers get resolved, usage gets normalized, and cost gets tagged per-team and per-user at the routing layer, before it hits your logs. That's what makes real-time budget enforcement possible.
Under the hood, the architecture separates three things that change at different rates:
Provider Response → Unified Gateway → Pricing Data → Pricing Logic → Cost
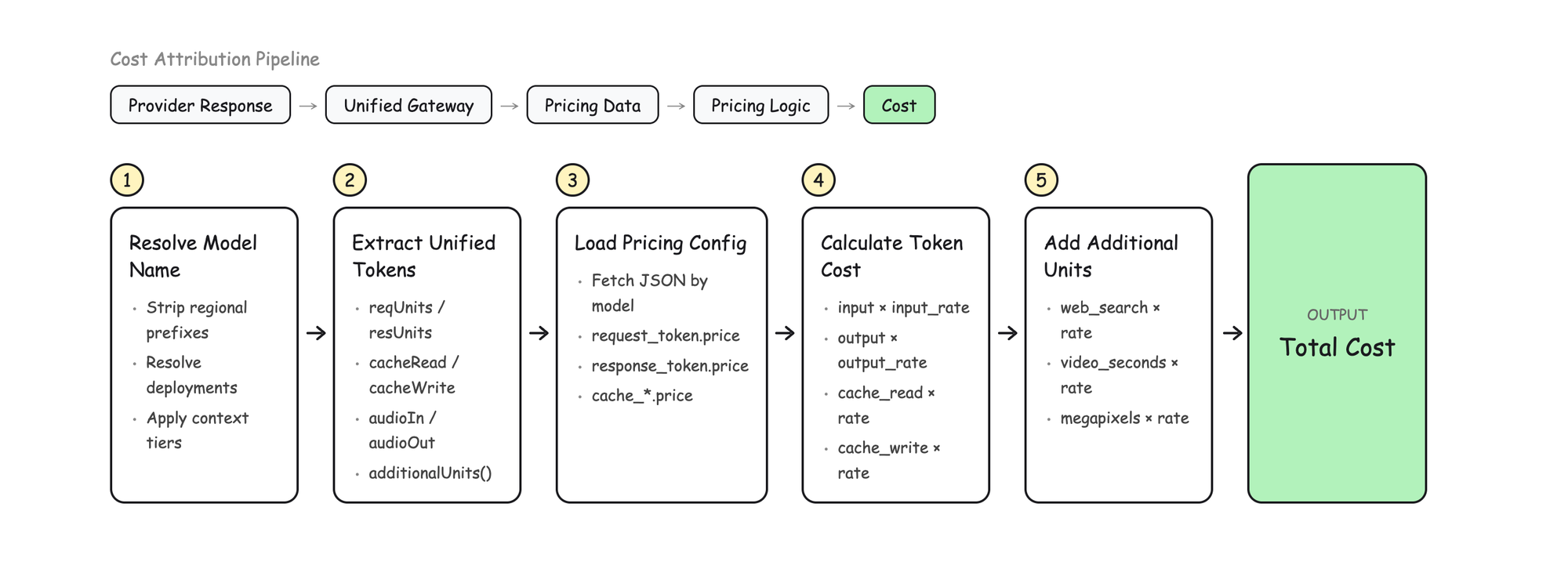
When a provider changes their response format, we update the extraction. When rates change, we update config. When new dimensions appear, we extend the schema. Each layer changes independently.
The normalization is where most of the interesting complexity lives. Every provider returns usage data differently. OpenAI gives you prompt_tokens and completion_tokens. Anthropic gives you input_tokens and output_tokens. Google nests promptTokenCount inside usageMetadata. Bedrock prepends regional prefixes that need stripping.
We normalize everything into one structure:
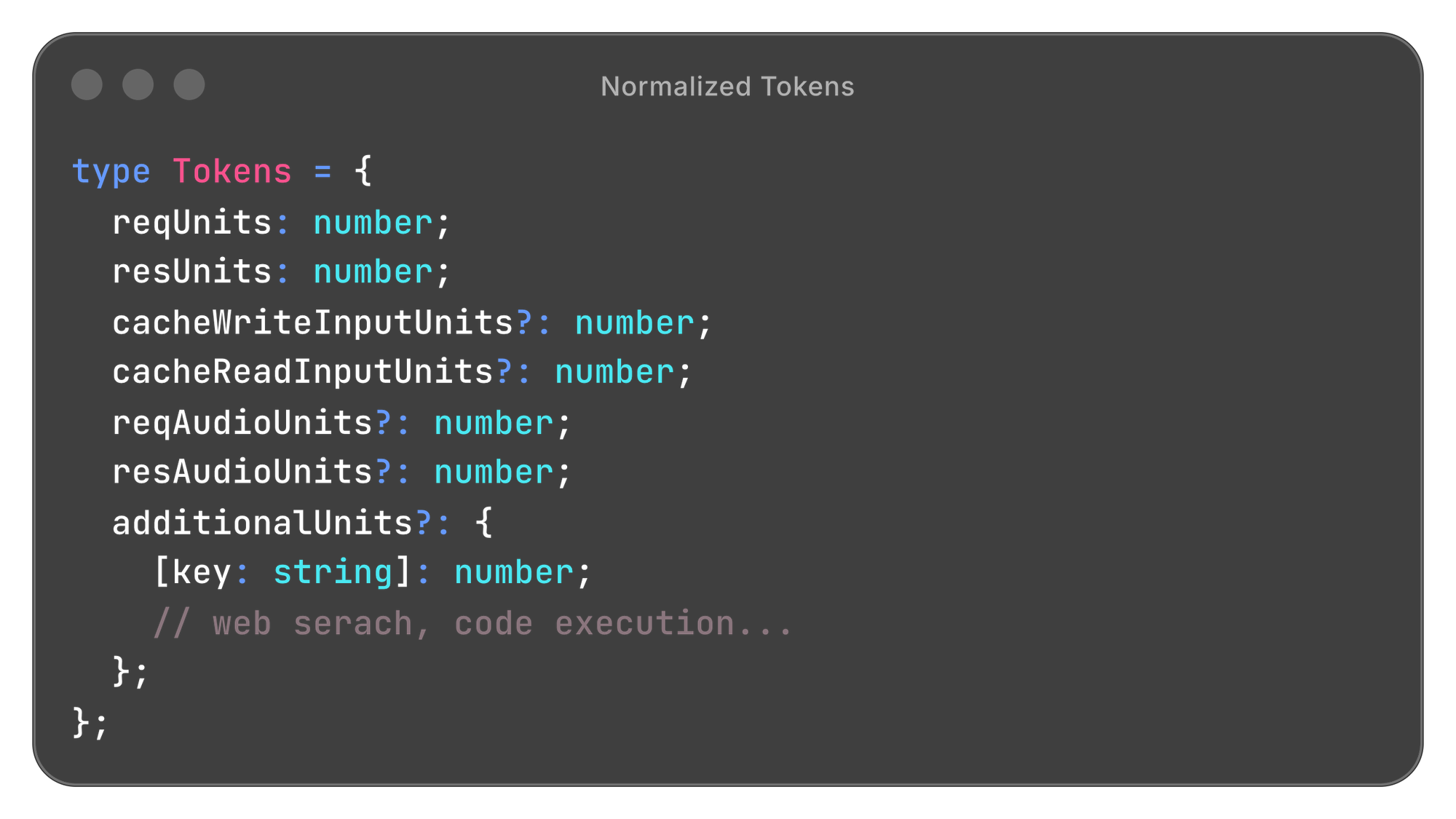
This flows through the system for every request, regardless of provider. The additionalUnits map is what lets us handle new billing dimensions (web search, grounding, tool use) without schema changes. They just become new keys.
Because the AI Gateway sits at the routing layer, it sees every request before it hits your logs. Model identifiers get resolved, usage gets normalized, cost gets tagged. That's what makes per-team and per-user budget limits possible. The gateway has the full context of every request, so cost attribution happens at the source rather than being reconstructed after the fact from incomplete data.
It's worth noting that Stripe recently launched their own AI Gateway specifically for LLM token billing, routing requests through a layer that meters usage per customer, per model, per token type. Same core insight: the centralized proxy is the natural place to solve cost attribution.
How we keep 3,500+ models accurate
Building the system was the easier part. Keeping it updated across 3,500+ models is the real challenge. Models launch weekly. Pricing changes without changelog entries. Context thresholds get buried in documentation footnotes. No human team can keep up with this manually.
We built an agent for this using the Claude Agent SDK, with tools for fetching model lists from provider APIs, web scraping, and GitHub integration.
The interesting design decision: provider-specific logic lives in skill files, not code. A skill file is a markdown describing how to handle a specific provider. Where to find model lists, how to scrape pricing, what quirks to watch for. When Anthropic changes something, we update the skill file. Not the agent. Not the codebase.
The agent loads skill files, fetches model lists, scrapes pricing sources, formats everything to schema, and opens PRs with citations. It costs about $2–3 per provider run. Novel pricing structures still confuse it. Humans handle judgment calls. But it covers the tedious work that was eating up our time.
We're working on open-sourcing the pricing agent itself. Subscribe to stay udpated
Pricing complexity isn't slowing down
New models, new billing dimensions, new provider quirks. If your cost dashboards don't match your invoices, this is probably why. We're releasing everything so you don't have to rebuild it from scratch:
- Model Data + Free API: Updated daily, check it out on portkey.ai/models
- Portkey's Gateway: Open-source AI gateway with built-in pricing engine
Get started at portkey.ai/models. If you're looking to bring this into your stack, book a call with us and we'll walk you through it.