The Harness Tax: The Dead Weight Inside Your Coding Agent
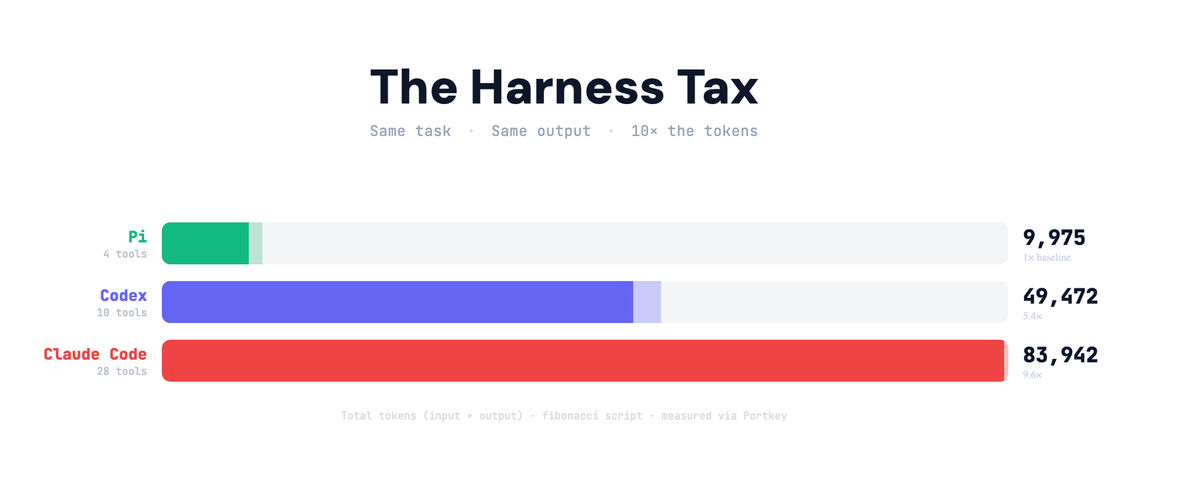
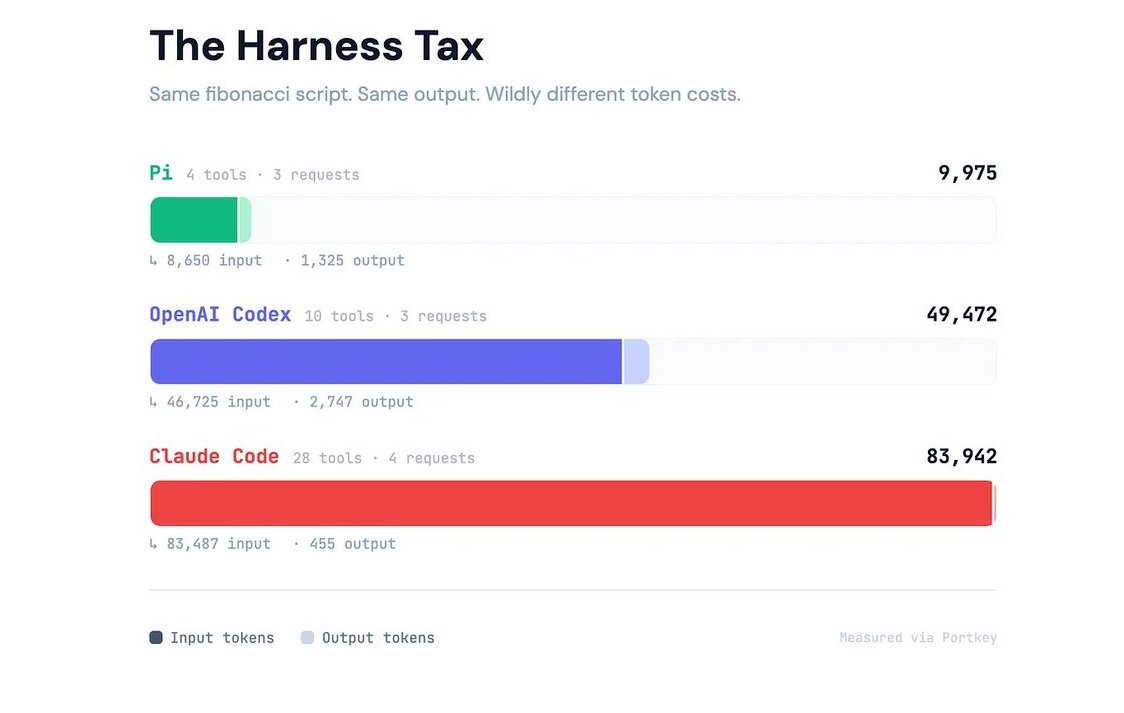
Claude Code used 83k tokens to write a Fibonacci script. Pi (OpenClaw) used 8k. Same task. Same output. Where did the rest of tokens go? Here's the tax no one's talking about.
Harnesses are not going away. Even the best models rely on them. Claude Code alone has ~512k lines of harness code. But nobody talks about what that harness actually costs you at inference time.
I wanted to know: when using coding agents, how much of the payload that hits the model is actually my message? And how much is the harness overhead added?
So I pointed three agents at Portkey's gateway and captured every request. Pi (the harness behind OpenClaw), OpenAI Codex, and Claude Code. Same request and complete token visibility. Then I gave each one the same two messages
Message 1: hey
Message 2: write a simple python script to check
fibonacci series and save on desktop as agent.py
Pi sent ~2,600 input tokens. Claude Code sent ~27,000. A 10x spread. Same task. Same model capability. The difference was pure harness overhead.
The Harness Tax
💡 The Harness Tax is every token your agent spends on itself before it spends a single token on your task.
You pay this tax before the model does a single unit of useful work.Every agent has one. You never see it unless you look at raw request logs. I routed all three agents through a gateway to get that visibility.
What Goes Into the Harness Tax?
Every request a coding agent makes to the model carries the full harness payload: tool definitions, system prompt, memory instructions, behavioral routing, and conversation history. All of it. On every turn.
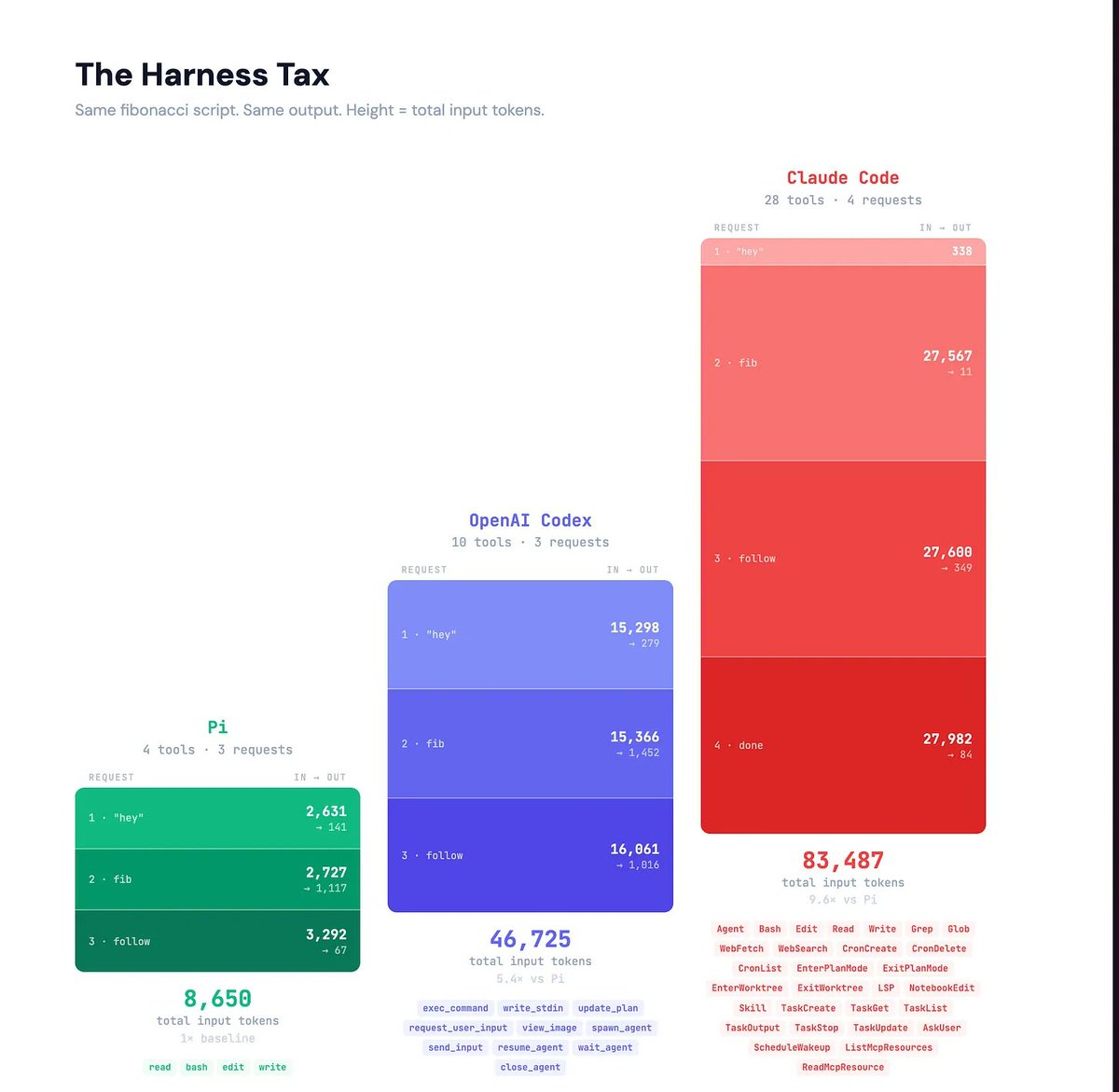
Claude Code's harness costs roughly 27,000 input tokens per request. Codex costs about 15,000. Pi costs about 2,600.
And because the conversation history includes the model's previous responses, which were themselves inflated by verbose tool-call formatting, the payload grows faster than your actual conversation does.
A real coding session runs 30 to 50 turns. At Claude Code's rate, a 40-turn session burns through 1.12 million input tokens. Roughly half of those are harness overhead.
💡 You pay the harness tax whether you use the tools or not. The 24 extra tools in Claude Code were defined but never called. Their definitions shipped on every request anyway.
Context Rot
The harness tax isn’t just a cost problem. It’s an attention problem. Every extra token competes with your actual task: your code, your files, your intent.
As the context window fills, the model gets worse at reasoning over the tokens that matter. Every token the harness adds competes for attention against your code, your files, and your actual task. On a complex refactor where the model needs to hold three source files, a test suite, and twenty turns of conversation, 28,000 tokens of framework plumbing aren't sitting idle. They're noise.
💡 A 200k context window carrying 28k tokens of harness overhead isn't a 200k window. It's a 172k window with worse attention distribution.
The harness rots in a second way: staleness. Every component encodes an assumption about what the model can't do on its own. Those assumptions go stale fast. More on that below.
Thin Harness, Fat skills
Pi gives the model four capabilities: read. write, edit a file and run a shell command. That's the entire tool surface.
The bet is that a model trained on millions of shell sessions, the internet, and GitHub repos already knows how to compose those primitives into anything else. You don't need a dedicated list_directory tool when ls -la exists. You don't need search_files when the model can write grep -r on its own.
"All frontier models have been RL-trained up the wazoo. They inherently understand what a coding agent is."— Mario Zechner, Pi's creator
Anthropic's harness engineering team demonstrated this concretely over three model generations. Their coding agent harness for Sonnet 4.5 required context resets because the model would start wrapping up work prematurely as the window filled. Opus 4.5 shipped, resets became unnecessary. Opus 4.6 shipped; they stripped out sprint decomposition entirely, and it still worked better.
Three model generations. Three layers of harness removed. Load-bearing in January, dead weight by March.
Harnesses encode assumptions that go stale as models improve - Anthropic Blog
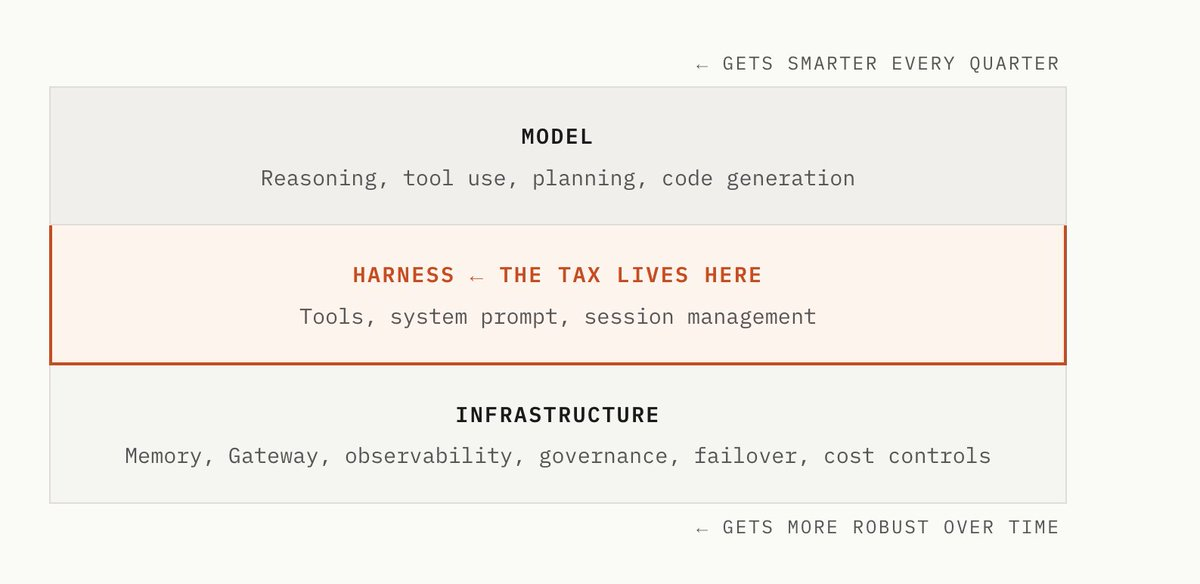
An agent has three layers. Complexity should push up into the model, which gets better at reasoning, planning, and self-correction with every release. It should push down into infrastructure, where routing, governance, observability, and cost controls don't ride along in the context window. The harness in the middle should carry as little as possible.
What This Means
This was a narrow benchmark. Two messages, one trivial task. Claude Code's deep tooling may earn back its overhead on complex work that genuinely exercises those 28 tools.
What this benchmark does show: the overhead exists, it's measurable, and almost nobody is looking at it. For most tasks, the model is carrying 15,000 tokens of framework plumbing it doesn't need. And that overhead is growing slower than models are improving, which means the tax gets harder to justify.
Route your agent through Portkey to measure your own harness tax.
Further Reading:
- Mario Zechner's blog post on building Pi — the design rationale
- Armin Ronacher: "Pi: The Minimal Agent Within OpenClaw"Pi on GitHub · OpenClaw on GitHub
This article was first published on X.