LLM proxy vs AI gateway: what’s the difference and which one do you need?
Understand the difference between an LLM proxy and an AI gateway, and learn which one your team needs to scale LLM usage effectively.
As more teams build with large language models (LLMs), managing how these models are accessed, used, and scaled has become a core part of the stack. This has given rise to two infrastructure patterns: the LLM proxy and the AI gateway.
They might sound similar, and they do share some overlapping features. But they’re designed for different levels of complexity and scale.
If you're evaluating what your team needs, this guide breaks down the differences between the two and when to use each.
What is an LLM proxy?
An LLM proxy is a lightweight middleware layer that sits between your application and the underlying LLM provider (like OpenAI, Anthropic, or Cohere). It’s designed to give developers more flexibility and control over how requests are routed, without locking into a specific provider or writing custom logic everywhere.
An LLM proxy does one job well: forward and shape LLM requests. It often comes with a few useful extras, like caching, logging, or token counting, but it’s fundamentally built for simple, fast routing.
Common features of an LLM proxy:
- Request forwarding and routing: Easily switch between model endpoints.
- Token tracking: Estimate or log tokens used per request.
- Basic logging: Capture inputs, outputs, and metadata for debugging.
- Response caching: Reduce cost and latency for repeated prompts.
LLM proxies are best suited for early-stage projects or internal tools, where speed of iteration matters more than governance or enterprise-level control. But as usage scales, their limitations begin to show.
What is an AI gateway?
An AI gateway is a production-grade infrastructure layer designed to manage, govern, and optimize all LLM traffic across an organization. While it includes basic proxying and routing, it goes far beyond that, offering centralized control, security, observability, and team-level governance.
It is like a control plane for LLM usage. Every request, regardless of model provider, team, or use case, flows through the gateway, which applies rules, logs activity, and ensures safe, cost-efficient usage.
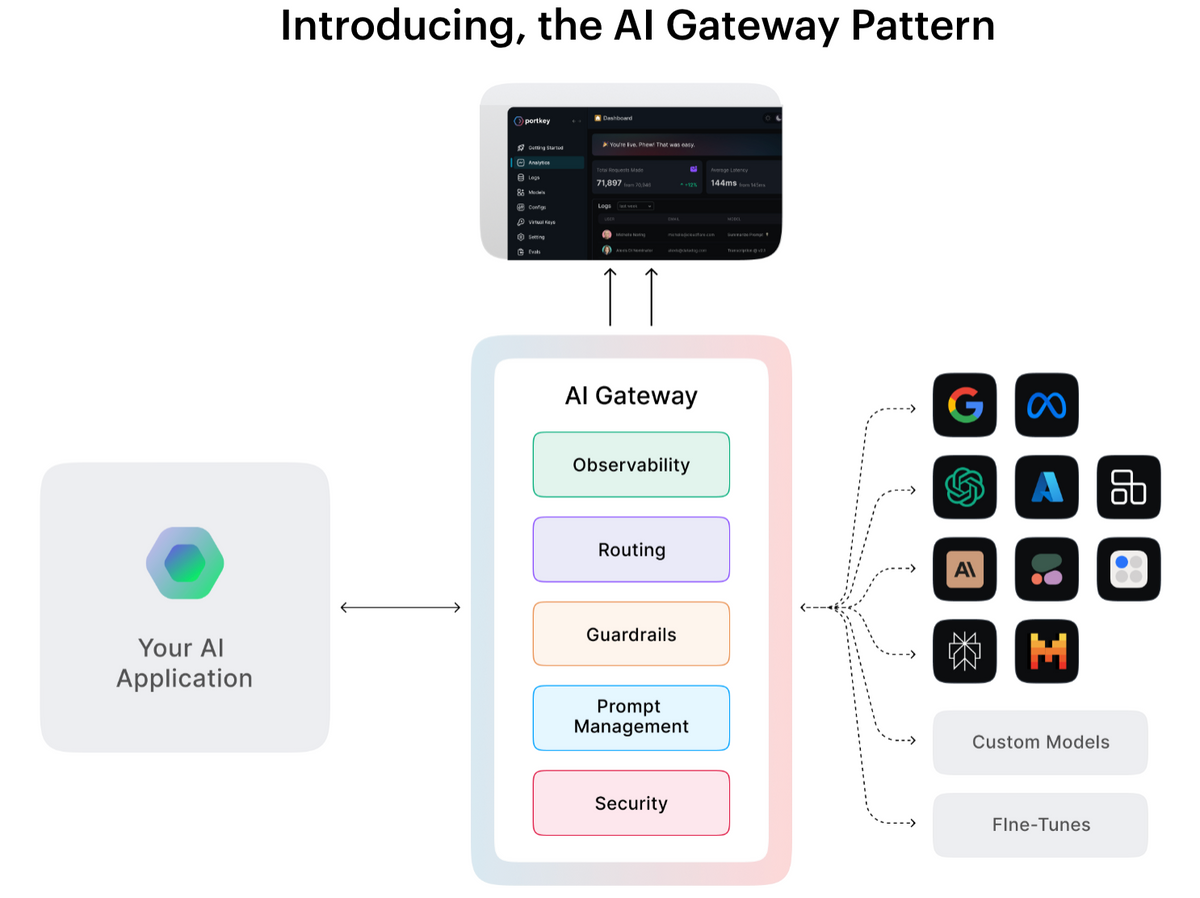
Additional Capabilities of an AI gateway:
- Access controls: Define who can use which models, and under what conditions.
- Guardrails: Enforce content policies, block jailbreaks, prevent PII leakage, and filter toxic responses.
- Audit logs: Maintain a structured, queryable history of every request with timestamps, user metadata, and outcomes.
- LLM Observability: Track latency, error rates, token usage, and model performance across providers.
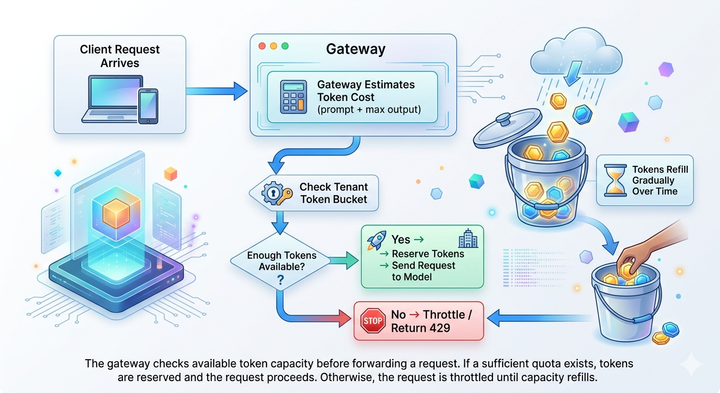
- Rate limits and budget enforcement: Apply spending caps per app, team, or use case.
- Multi-provider abstraction: Easily route across OpenAI, Claude, Mistral, Azure, and more.
- Prompt management: Store, version, and test prompts centrally with visibility into usage and effectiveness.
AI gateways are purpose-built for teams working across multiple LLMs, products, and departments. They help organizations treat LLMs as critical infrastructure that needs to be governed, monitored, and scaled responsibly.
LLM proxy vs AI gateway: feature comparison
While both LLM proxies and AI gateways sit between your application and model providers, the problems they solve and the depth of control they offer are very different.
An LLM proxy is built for flexibility and ease of use during development. An AI gateway is designed for production environments where security, scalability, and observability are critical.
| Feature | LLM Proxy | AI Gateway |
|---|---|---|
| Request routing | ✔︎ | ✔︎ |
| Basic caching | ✔︎ | ✔︎ (advanced, configurable) |
| Token tracking | ✔︎ | ✔︎ |
| Logging | ✔︎ (limited) | ✔︎ (structured, queryable) |
| Access control | ✘ | ✔︎ (role-based, multi-tenant) |
| Guardrails & moderation | ✘ | ✔︎ (jailbreak detection, filtering) |
| Audit logs | ✘ | ✔︎ |
| Budget controls | ✘ | ✔︎ (per team/app/model) |
| Rate limiting | ✘ | ✔︎ (configurable and enforceable) |
| Multi-provider support | ✔︎ | ✔︎ |
| Prompt management | ✘ | ✔︎ (centralized + version control) |
| Observability | ✘ | ✔︎ (latency, error, usage analytics) |
When should you use an LLM proxy?
An LLM proxy is ideal for fast-moving teams working on early-stage AI projects. It gives developers the flexibility to test different models, switch providers, and add light abstraction without heavy operational overhead.
You should consider using an LLM proxy when:
- You’re building a prototype or internal tool: You just need something that routes requests and maybe logs them for debugging.
- You’re only using one model provider: There’s no need for multi-provider abstraction or complex orchestration.
- You’re not worried (yet) about governance or compliance: There’s no immediate need for rate limits, role-based access, or audit trails.
LLM proxies are great developer tools, especially during the build phase. But as usage grows across users, teams, or regions, their simplicity becomes a bottleneck.
When should you use an AI gateway?
If you’re moving beyond prototyping and starting to treat LLMs as part of your production infrastructure, an AI gateway becomes a necessity. It’s the layer that brings security, standardization, and control to how models are used across your organization.
You should use an AI gateway when:
- You’re deploying to production: You need predictable behavior, safety checks, and visibility into usage.
- Multiple teams or apps use LLMs: Without a shared control plane, it's hard to manage permissions, costs, and model access at scale.
- You need observability and auditability: Track every generation, log inputs/outputs with metadata, and analyze performance issues or spikes.
- You care about cost and rate limits: Enforce budgets per app, restrict usage during peak load, and prevent cost overruns.
- You're using multiple providers: Seamlessly route across OpenAI, Anthropic, Azure, and more, without hardcoding APIs or credentials in your app.
- You need to enforce guardrails: Block jailbreaks, prevent hallucinations, or redact sensitive content before it reaches end users.
- You’re in a regulated environment: Ensure that all LLM traffic is compliant with internal and external requirements.
An AI gateway is designed for scale. It brings the kind of rigor you expect from your API gateway or identity provider, now applied to how LLMs are consumed inside your org.
Common myths about AI gateways
Despite growing adoption, there are still several misconceptions about what AI gateways do and how difficult they are to implement. Here are some of the most common myths debunked.
Myth: AI gateways are hard to set up
Many teams assume an AI gateway will take weeks of infrastructure planning and integration work. In reality, most AI gateways like Portkey can be deployed with minimal setup via SDKs, APIs, or a simple proxy configuration. You can often start routing traffic and enforcing basic guardrails in less than an hour.
Myth: Building your own gateway is easier
At first glance, routing requests to an LLM provider and logging them might seem straightforward. But maintaining a secure, scalable, and feature-complete internal gateway quickly becomes a full-time job. Handling things like provider abstraction, prompt versioning, guardrails, and observability is complex and typically not worth reinventing. Also read: Build vs Buy AI Gateway
Myth: It’s only for enterprises or regulated industries
While AI gateways are essential for enterprises with compliance needs, they’re just as valuable for startups. Features like cost limits, prompt management, and API key governance help even small teams move faster without losing control.
Myth: AI gateways are expensive
Another common belief is that gateways add unnecessary cost. In practice, they often reduce costs by enabling caching, preventing wasteful generations, and enforcing usage caps. The visibility they offer also helps teams optimize which models they use and how.
What should you choose?
If you're experimenting with LLMs in a single app, an LLM proxy might be all you need. But as usage scales across teams, products, or model providers, so does complexity. That’s when an AI gateway becomes essential, bringing observability, governance, and control to your entire LLM stack
If you're looking to implement an AI gateway that’s fast to deploy, easy to integrate, and built for scale, Portkey offers a fully managed control layer for all your LLM traffic. Route across providers, enforce guardrails, monitor usage, and manage costs without writing custom infrastructure.
Start with Portkey and bring governance and flexibility to every LLM call. Get started yourself or book a demo with us today