Using metadata for better LLM observability and debugging
Learn how metadata can improve LLM observability, speed up debugging, and help you track, filter, and analyze every AI request with precision.
As teams build and scale LLM apps, one of the biggest challenges they face is understanding how these systems behave in production. Why did a particular prompt return a low-quality response? Which product features are driving the most LLM traffic? How can you trace an issue reported by a user back to a specific model call?
Metadata enables traceability, performance monitoring, and debugging in ways that are impossible through raw LLM output alone. In this blog, we’ll break down what metadata means in the context of LLM apps, why it’s essential for observability, and how tools like Portkey make it easy to implement.
What is metadata in LLM applications?
In the context of LLM apps, metadata is the structured information you attach to every request. It doesn’t change the behavior of the model itself, but it gives you visibility into the who, what, where, and why behind every LLM call. It could be as simple as recording which user triggered the request, or as detailed as logging the specific product feature, app version, model provider, and session ID.
Metadata isn’t just useful for individual cases. When captured consistently, it allows you to build detailed dashboards, filter logs, track model behavior across environments, and understand how different segments of your product interact with AI.
Why metadata matters for LLM observability
First and foremost, metadata enables traceability. It allows you to connect each LLM response back to the full context that shaped it, the environment the request came from, the user who triggered it, the product feature or flow it belonged to, the version of the model and prompt that was used.
Metadata also helps teams quickly identify root causes when something breaks or goes off the rails. Imagine a spike in hallucinations or slow responses. Without metadata, you’re left guessing whether the issue is tied to a specific feature, a recent prompt change, or a particular model. With metadata, patterns emerge fast. You don't have to dig through logs blindly.
It can help with optimization, too. By tagging requests with feature identifiers, you can understand which parts of your product are consuming the most tokens or facing the highest latency. You can track usage and cost by environment, compare model performance, and spot areas for improvement.
Best practices for structuring metadata
- Use consistent keys across your organization: Standardize the metadata fields across all teams and services. Consistent, predictable keys make it easier to query and analyze metadata. Establish a clear naming convention that’s easy to follow. Using lowercase, snake_case, and avoiding spaces helps maintain readability. When naming your keys, also avoid ambiguous terms that could mean different things in different contexts.
- Track essential fields: Make sure you capture the critical data points with each LLM request. Here are some recommended fields:
- _user: Identify who initiated the request.
- environment: Record whether the request is coming from dev, staging, or prod environments.
- feature or component: Tag which part of your product made the AI call (e.g., chat_assist, search_suggestions).
- version: The version of the API or model that handled the request.
- session_id: Group related requests together under the same session. This is especially helpful for multi-turn conversations or complex workflows.
- request_id: An internal tracking ID for each request, which helps with tracing and debugging at a granular level.
- Tag early and propagate metadata through the system: Attach metadata as early as possible in the request lifecycle. The metadata should be passed through every layer of your system, from API gateways to your backend, and across any middleware or services, so you can correlate logs and troubleshoot more effectively.
How Portkey enables metadata-driven LLM observability
Capturing metadata is only the first step. To make it actionable, you need the right infrastructure to store, search, and analyze it across all your LLM traffic. That’s where Portkey comes in.
Every request sent through Portkey can be enriched with custom metadata fields — whether it’s the user ID, the environment, the product feature, or your internal request ID. This metadata is automatically indexed and made available in real-time, so you can slice and filter your logs across any dimension that matters to you.
Portkey also aggregates this data into visual dashboards, helping teams monitor usage trends, debug failures, and identify optimization opportunities without sifting through unstructured logs.
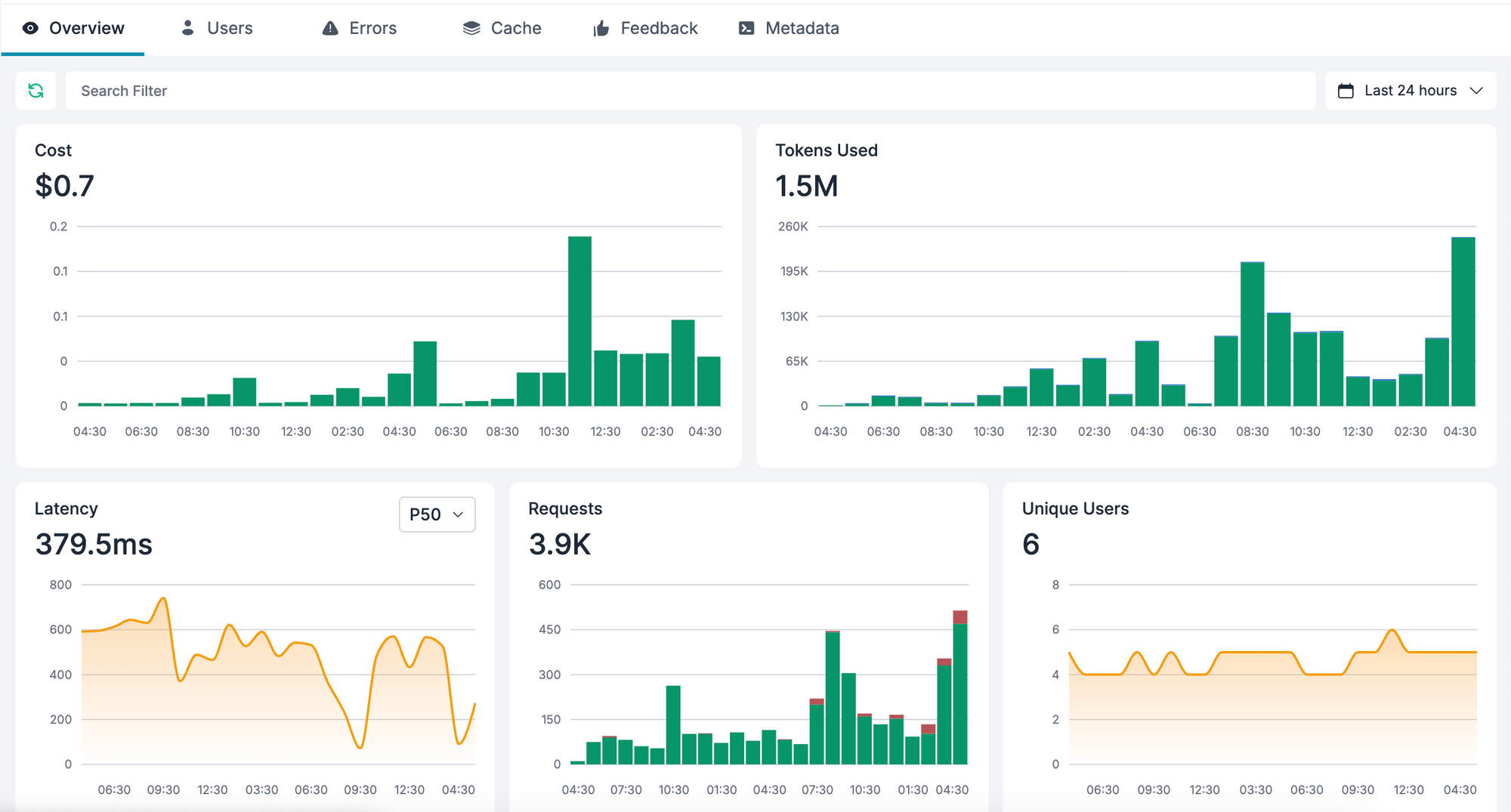
It also makes it easy to enforce consistency across your team. You can define required metadata fields like _user, feature, or environment — so every LLM call includes the context needed for observability. And if you ever need to debug a specific incident, you can trace it back to the exact request with full metadata attached, without any custom instrumentation.
Whether you’re running a single AI feature or managing a complex, multi-model application, Portkey helps you bring order and clarity to your LLM observability.
Start with better LLM observability
Metadata is the missing link between unpredictable LLM behavior and reliable, scalable AI systems. It brings structure to your logs, context to your debugging, and clarity to your performance monitoring. With Portkey, you can track, filter, and act on metadata without reinventing your stack.
Start using metadata the right way — get started with Portkey today.