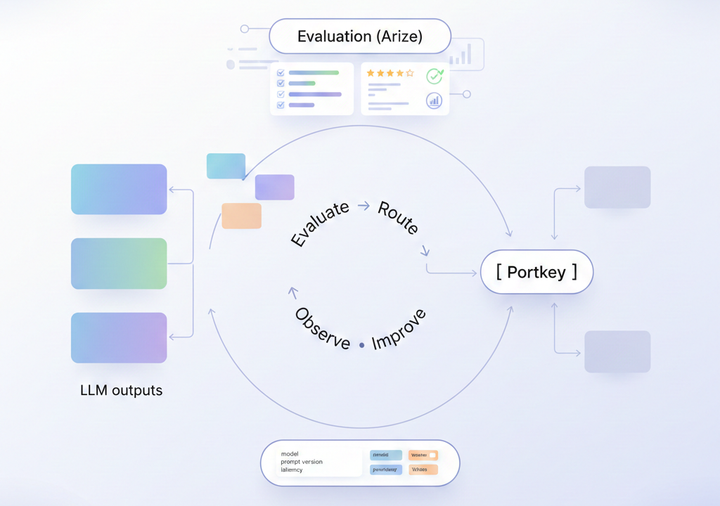
LLM Observability is now a business function for AI
As GenAI moves from experiments to production, LLM observability is becoming a business-critical function, driving reliability, governance, and trust in enterprise AI systems.
We have moved from pilot-stage generative AI experiments to now running AI in production. Large language models (LLMs) and agentic AI are now embedded into processes that directly impact customer engagement, brand reputation, regulatory compliance, and cost efficiency.
With this transition, observability is moving beyond the domain of developers and emerging as a strategic business function.
The visibility gap in LLM systems
As organizations scale their AI workloads, they’re discovering that the existing observability stack wasn’t built for the dynamics of language models. Traditional tools can measure latency, uptime, or infrastructure health, but they can’t explain how a model reasoned, why it produced a specific response, or where inefficiencies arise across prompts, tokens, and contexts.
This gap between modern application monitoring and AI system behavior is now one of the biggest barriers to operational reliability. When a model hallucinates, uses excessive tokens, or drifts from intended prompts, these issues rarely surface in classic traces or metrics, leading to silent inefficiencies that compound over time.
Without this dual-layer approach, AI teams are essentially blind to the qualitative behavior of their systems. They might know an endpoint is healthy but have no way to see whether the model behind it is producing compliant, consistent, or cost-efficient outputs.
Why observability now matters to SRE, compliance, and governance teams
The same telemetry that once helped engineers debug prompts or optimize latency is now used across multiple business functions to maintain reliability, compliance, and control.
For SRE and platform teams, LLM observability has become part of production reliability. They use traces and metrics to monitor latency spikes, track fallbacks, and ensure fail-safes trigger when a model or provider degrades.
Observability also underpins FinOps for AI, the practice of controlling and optimizing model spend through visibility. By tracing token usage, caching efficiency, and model utilization, teams can connect operational metrics directly to business outcomes. This enables cost governance, proactive budgeting, and precise forecasting of model ROI.
For governance and compliance teams, observability provides traceability. Each prompt and response forms part of an auditable trail, essential for demonstrating adherence to internal policies, privacy standards, and regulatory frameworks.
Taken together, observability has expanded into a shared operational framework that connects reliability, cost, and governance under one system of record.
Extending telemetry for LLMs
Standard telemetry captures latency, error codes, resource usage, useful for infrastructure and service stacks. But for LLM-based systems, new dimensions are required: prompt context, token counts, hallucination events, model-fallbacks, semantic routing, caching efficiency.
Why this matters for enterprise value
When observability supports LLM-specific data, organisations unlock value across multiple dimensions:
- Performance optimisation: Identify prompt-drift or token-waste patterns and optimise model or prompt architecture.
- Cost control (FinOps): Connect token usage and model versioning to spend, enabling budgeting and ROI insights.
- Governance and trust: Create traceability for prompts, responses, model changes and fallback behaviour—critical for audit, compliance and risk management.
- Vendor flexibility: With open standards paired with LLM-specific extensions, enterprises can mix and match gateways, models and observability backends without rewriting instrumentation.
What to look for when evaluating an LLM observability solution
Choosing an observability platform for AI systems now extends beyond monitoring dashboards or token counters. The right solution must bridge infrastructure telemetry, LLM-specific signals, and operational governance within one unified gateway. When evaluating options, enterprises should look for:
1. Alignment with open standards
Support for frameworks such as OpenTelemetry ensures interoperability and prevents lock-in. Open standards allow AI and SRE teams to correlate observability data across traditional applications, model endpoints, and orchestration layers—without re-instrumenting every system as models or providers evolve.
2. LLM-specific tracing and analytics
Effective observability for AI goes beyond uptime or throughput. The platform should capture:
- Prompt-level traces that show latency, token usage, and fallback behavior.
- Tool-calling visibility to monitor how LLMs interact with external APIs or actions.
- Agent traces that map multi-step reasoning or task orchestration.
- MCP Observability, to trace how models access or interact with external data sources via MCP servers and tools.
3. Building on observability through an AI gateway
Observability gives visibility, but enterprises also need mechanisms to act on what they learn. An AI gateway helps operationalize those insights with a framework to configure and govern AI systems based on observed performance and behavior. This includes:
- Setting up routing rules between models or providers based on reliability or cost data.
- Enforcing RBAC and budget limits aligned with usage patterns surfaced by observability metrics.
- Implementing guardrails to mitigate risky prompts or responses detected during monitoring.
- Managing and versioning prompts informed by evaluation and tracing results.
4. Security, auditability, and compliance
As AI adoption deepens across industries, observability must meet enterprise-grade standards. Platforms should include audit trails for every prompt, response, and model event. This level of traceability is key to ensuring responsible use and compliance with internal and regulatory policies.
Portkey was recognized in the 2025 Gartner® Cool Vendors™ in LLM Observability. Portkey extends observability into actionable governance, allowing teams to monitor, analyze, and configure LLM applications through a unified AI gateway that spans tracing, routing, guardrails, and prompt management.
Looking ahead
Observability is becoming a part of how organizations run, secure, and scale AI systems. As enterprises operationalize LLMs, ownership is shifting from isolated teams to shared accountability between platform, SRE, FinOps, and governance functions.
The next step for most teams is turning visibility into control. This means using what’s measured to set budgets, design routing rules, enforce guardrails, and evaluate model quality across environments.
If you’re building or scaling GenAI systems, start by establishing strong observability. Explore how Portkey helps teams monitor, govern, and optimize LLM applications through a unified AI gateway.
GARTNER is a registered trademark and service mark of Gartner, Inc. and/or its affiliates in the U.S. and internationally, and COOL VENDORS is a registered trademark of Gartner, Inc. and/or its affiliates and are used herein with permission. All rights reserved. Gartner does not endorse any vendor, product or service depicted in its research publications, and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.