
Benchmarking the new moderation model from OpenAI
OpenAI's new "omni-moderation-latest" model shows significant improvements over the legacy model, especially in multilingual performance and image moderation. We benchmark it's capabilties with it's predecessor.
Content moderation is essential to ensure that platforms remain safe and welcoming spaces for all users. Harmful content, such as hate speech, harassment, and explicit material involving minors, can have severe psychological effects on individuals and can tarnish the reputation of platforms that host such content.
As manual moderation becomes increasingly untenable due to scale, AI has emerged as a critical tool in automating the detection and management of potentially harmful content.
Recently, OpenAI introduced a new moderation model called "omni-moderation-latest" to replace their older model.

This blog post dives deep into the capabilities of this new model, comparing it with its predecessor and providing a comprehensive benchmark to help AI engineers and developers understand its potential impact.
We'll try to understand the differences in the new moderations model along with benchmarking the model on performance, accuracy and latency.
1. OpenAI's new "omni-moderation-latest" model shows significant improvements over the legacy model, especially in multilingual performance and image moderation.
2. Key enhancements include support for 13 content categories (up from 11) and improved accuracy across 40 languages tested.
3. Our benchmarks show the new model excels in recall but may have a higher false positive rate, indicating increased sensitivity to potentially problematic content.
4. While the new model shows clear advantages, developers should consider their specific use cases when deciding whether to upgrade.
Use the latest models in LibreChat via Portkey and learn how teams are running LibreChat securely with RBAC, budgets, rate limits, and connecting to 1,600+ LLMs all without changing their setup.
To join, register here →
Model Comparison: Legacy vs. Omni
Let's start by comparing the key features of the new omni-moderation-latest model with the legacy text-moderation-latest model:
| Feature | Text Moderation-Latest (Legacy) | Omni-Moderation-Latest (New) |
|---|---|---|
| Input Types Supported | Text Only | Text and Images |
| Content Categories | 11 Categories | 13 Categories (2 extra) |
| Multi-Modal Analysis | No | For 6 categories |
| Language Support | Primarily latin languages | Improvement across 40 languages tested. Biggest improvements in Telugu (6.4x), Bengali (5.6x), and Marathi (4.6x) |
| Accuracy in Content Classification | Good | Enhanced |
| Customization Options | Threshold Adjustment | Threshold Adjustment |
| Fine-Tuning Support | Not Supported | Not Supported |
| Cost to Use | Free | Free |
The new model brings significant improvements, particularly in multilingual performance.
OpenAI reports a 42% improvement on their internal multimodal evaluation across 40 languages, with 98% of tested languages showing improvement. Low-resource languages like Khmer or Swati saw a 70% improvement, while languages like Telugu, Bengali, and Marathi showed the most dramatic improvements (6.4x, 5.6x, and 4.6x respectively).
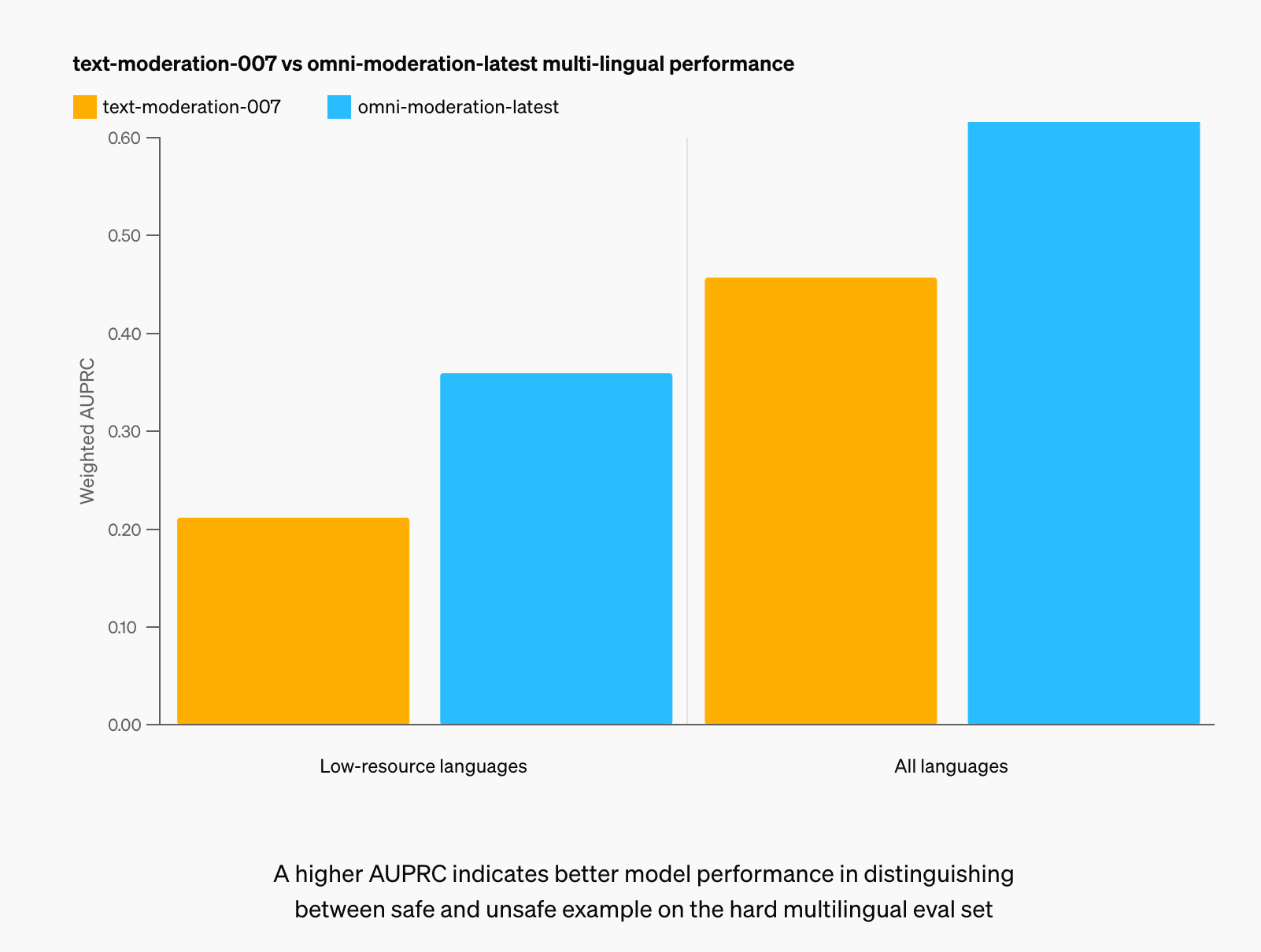
While these improvements sound impressive on paper, it's crucial to understand how they translate to real-world performance.
To provide a clear, unbiased comparison between the legacy and new models, we conducted our own comprehensive benchmarking process.
This evaluation aims to give developers and AI engineers a practical understanding of what these improvements mean for content moderation tasks across various scenarios and languages.
Benchmarking Methodology
To provide a comprehensive evaluation of both models, we developed a robust benchmarking process. Here's a quick rundown of our methodology:
- Data Preparation: We used three distinct datasets - Jigsaw, HateXplain, and a Multilingual dataset - each offering unique challenges in content moderation.
- Batch Processing: We implemented batch processing (20 texts per batch) to optimize performance and reduce API calls.
- Metrics: We calculated F1 Score, Precision, Recall, False Positive Rate, and Latency for each model across all datasets.
- API Integration: We used the Portkey AI Gateway through the SDK to interface with OpenAI's moderation APIs, testing both the "Omni" and "Legacy" models.
For transparency and to help the community build upon our work, we've made this script available on GitHub
 Portkey-AI
Portkey-AIResults and Findings
Let's dive into the results of our benchmark, focusing on what these numbers mean for developers and content moderators in real-world scenarios.
F1 Score Comparison
How to interpret: The F1 score balances precision and recall. A higher score indicates better overall performance.
Key Insight: While Legacy slightly outperforms Omni in Jigsaw and HateXplain datasets, Omni shows a significant advantage in the Multilingual dataset (0.322 vs 0.167). This suggests that Omni is particularly strong in handling non-English content, a crucial factor for global platforms.
Precision Comparison
How to interpret: Precision measures how many of the items flagged as problematic are actually problematic. Higher is better.
Key Insight: Legacy consistently shows higher precision. This means it's less likely to incorrectly flag benign content, which could be beneficial for platforms where false positives are particularly costly (e.g., social media platforms where incorrectly flagged content might lead to user frustration).
Recall Comparison
How to interpret: Recall measures how many of the actually problematic items were caught. Higher is better.
Key Insight: Omni demonstrates higher recall, especially in the Multilingual dataset where its recall (0.254) is over 2.5 times higher than Legacy's (0.098). This suggests Omni is more effective at catching potentially harmful content, particularly in diverse language contexts. This could be crucial for platforms prioritizing user safety over occasional false positives.
Average Latency Comparison
How to interpret: This measures the average time taken to process a batch of 20 texts. Lower is better for real-time applications.
Key Insight: Both models show comparable latency, with slight variations across datasets. The differences are generally within a few milliseconds, suggesting that performance rather than speed should be the primary factor in choosing between the models.
Model Disagreement Analysis
| Dataset | Total Samples | Disagreements | Disagreement Rate | Omni More Sensitive | Legacy More Sensitive |
|---|---|---|---|---|---|
| Jigsaw | 1000 | 47 | 4.70% | 36 | 11 |
| HateXplain | 1000 | 154 | 15.40% | 132 | 22 |
| Multilingual | 1000 | 80 | 8.00% | 75 | 5 |
The disagreement analysis reveals interesting patterns in how Omni and Legacy differ in their assessments.
Notably, Omni tends to be more sensitive across all datasets, particularly in the HateXplain dataset where it flagged content as problematic 132 times when Legacy did not, compared to only 22 instances where Legacy flagged content that Omni did not.
Real-world Examples
Let's look at some specific examples to illustrate the differences between the models:
Text: "Koca meclis baskanina bak salincak çeviriyor 😆😆😆 yukselen ve buyuyen turkiye. Kiskanmasinlar ama bizi. Ulan ulkende bir tane bok temizleme makinası dahi uretilmezken şu haline bak bi ya.arap zihniyetinize sicayim. Hadi onlar mal a petrol var.sende ne var be mal"
Omni Score: 0.643
Legacy Score: 0.018
Explanation: This Turkish text contains offensive language and hate speech. Omni correctly identified it with a high score of 0.643, while Legacy missed it entirely with a low score of 0.018. This example highlights Omni's superior performance in multilingual contexts, demonstrating over 35 times higher sensitivity to hate speech in non-English content.
Text: "Wow, big man here. Can't take a little criticism and is upset about his failure to become an admin. So what does he do? Looks for the closest person to run to, some admin on Wikipedia."
Omni Score: 0.144
Legacy Score: 0.600
Explanation: This example showcases a case where Legacy was overly sensitive, scoring this as harassment with 0.600, while Omni more accurately assessed it as mildly provocative but not severe harassment with a score of 0.144. This demonstrates Omni's ability to better distinguish between genuine harassment and merely argumentative or sarcastic content.
Text: "Excellent. And please don't damage your book on our account, for sure. It is an interesting question: Where was the camera? That's a fair question. To jump to the conclusion that it was 'impossible' is ludicrous. But that's typical for the moonbats."
Omni Score: 0.009
Legacy Score: 0.764
Explanation: In this case, Legacy incorrectly flagged this content as harassing with a high score of 0.764, while Omni correctly identified it as non-problematic with a low score of 0.009. This example illustrates Legacy's tendency towards false positives, especially with contentious but not inherently harmful discussions.
Key Findings
- Omni excels in multilingual content moderation, showing over 2.5 times better recall than Legacy in non-English datasets.
- Legacy demonstrates higher precision across all datasets, making it potentially more suitable for applications where minimizing false positives is crucial.
- Omni's higher recall and false positive rate indicate it's more sensitive in flagging potentially problematic content, which could be advantageous in high-stakes moderation scenarios.
- The models show the highest disagreement rate (15.40%) in the HateXplain dataset, suggesting that nuanced or contextual hate speech remains a challenging area for content moderation.
- Latency differences between the models are minimal, indicating that performance characteristics should be the primary consideration when choosing between them.
Limitations and Considerations
- Dataset labels may not perfectly align with API categories, potentially leading to discrepancies in performance metrics.
- The Multilingual dataset shows significantly lower overall performance for both models, highlighting the ongoing challenges in non-English content moderation.
- False positives and negatives often involve nuanced or context-dependent content, underscoring the complexity of content moderation tasks and the potential need for human review in ambiguous cases.
The new omni-moderation-latest model from OpenAI represents a significant step forward in AI-powered content moderation, particularly in its multilingual capabilities and support for image moderation. Its improved recall across various content categories makes it a powerful tool for catching potentially harmful content, especially in diverse language contexts.
Key takeaways for developers:
- If you're serving a global audience, the Omni model's improved multilingual performance could significantly enhance your moderation capabilities.
- For platforms where missing harmful content could have severe consequences, Omni's higher recall might be worth the trade-off of potentially more false positives.
- Consider implementing moderation through guardrails: use a mdoeration API request after AI content creation to automatically detect and stop potentially harmful content.
- Take advantage of the detailed category scores to fine-tune your moderation thresholds based on your platform's specific needs and risk tolerance.
By leveraging the power of AI-driven moderation tools like OpenAI's omni-moderation-latest, developers can create safer, more welcoming online spaces while efficiently managing the scale and complexity of modern digital platforms.
References
- OpenAI Moderation API Documentation
- Using Moderations through Portkey's AI Gateway
- Using the moderation guardrail


