
Reducing AI hallucinations with guardrails
Your chatbot just told a user that Einstein published his Theory of Relativity in 1920. Sounds plausible, right? Except it happened in 1915. This isn't a rare glitch -
A recent study revealed 46% of users regularly catch their AI systems making up facts like these, even with massive training data. These aren't just trivial mistakes either.
When AI makes up facts or references in business settings, it can lead to bad decisions or compliance headaches. But don't worry - we've got tools called guardrails that can help keep these generative AI hallucinations in check. Let's break down how they work.
What are AI hallucinations and why do they occur?
Think of it like a student who reads half a textbook and fills in gaps with educated guesses. The AI looks at patterns in its training data and makes what seem like logical connections—but they're not always right.
Take dates in scientific history. An AI might know Marie Curie won Nobel Prizes and worked on radioactivity, but mix up the timeline. It could state she discovered uranium in 1920, when actually Henri Becquerel discovered radioactivity in uranium in 1896. The AI connected "Curie + radioactivity + uranium" and made a plausible but incorrect leap.
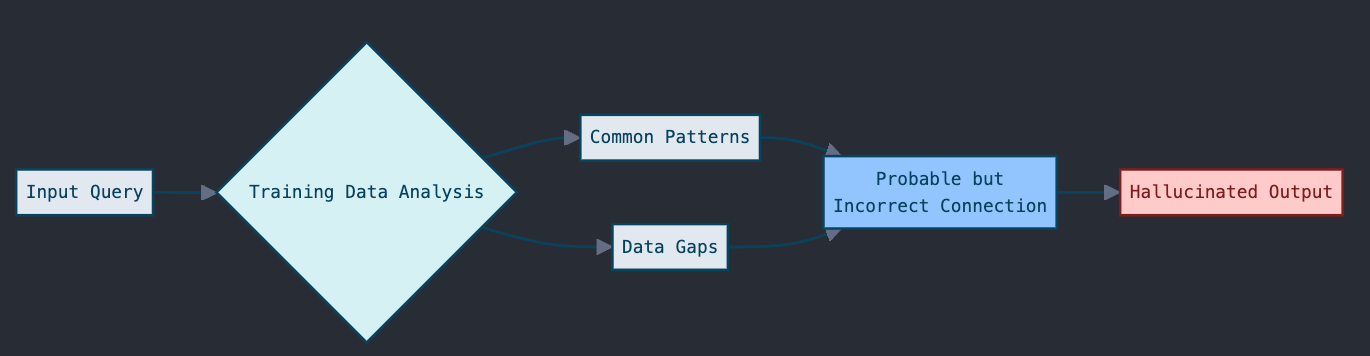
When these mistakes happen in business settings, they're more than just awkward - they can cause real problems.
Types of AI Hallucinations
AI hallucinations generally occur in the below four ways:
Factual Inaccuracies: When the model generates incorrect facts or data. For example, stating that the first iPhone launched in 2009 when it actually launched in 2007. These often appear in historical dates, statistical data, or technical specifications.
Logical Inconsistencies: When the model's output contradicts basic logic or known principles. For instance, suggesting that increasing redundant calculations would improve code performance, or claiming a programming language supports features it doesn't have.
Fabricated References: When the model invents non-existent sources to support its claims. This includes creating fake research papers, inventing company names, or attributing quotes to people who never said them.
Semantic Distortions: When the model's response veers away from the query's intent or context. If asked about Python error handling, it might drift into unrelated Python topics or completely different
What causes AI hallucinations?
Incomplete or Biased Training Data: When a model's training dataset lacks comprehensive coverage of certain topics or contains skewed information, it may generate incorrect outputs to fill knowledge gaps. This is particularly evident in specialized domains or less common scenarios where training data is limited.
Ambiguity in Prompts: Unclear, imprecise, or poorly structured input queries can lead models to make assumptions and generate speculative responses. When the context or requirements aren't clearly defined, models default to generating plausible but potentially incorrect information.
Overgeneralization: Models sometimes apply learned patterns too broadly, making incorrect connections between unrelated concepts. They may detect superficial similarities and extend rules or relationships beyond their valid contexts.
How to prevent AI hallucinations?
AI Guardrails work as verification systems that reduce AI hallucinations by comparing AI outputs against trusted sources and predefined rules. They act as filters between the model and users, validating responses before they're sent out.
Here's how they work in practice:
- Input Validation: They check if user queries match approved topics and formats
- Source Verification: They cross-reference outputs against approved databases or documents
- Rule Enforcement: They apply specific business logic and compliance requirements
- Output Filtering: They block or flag responses that don't meet validation criteria
How to implement Guardrails against AI Hallucinations
Implementing effective guardrails to prevent generative AI hallucinations starts with rigorous source validation. Your training dataset forms the foundation of your AI system's knowledge, so it's essential to build it from verified, high-quality sources. This means carefully documenting the origin of each data source, tracking versions of reference materials, and maintaining consistent data formats throughout. A thorough cleaning process helps remove inconsistencies that could lead to hallucinations later.
The next phase focuses on in-output linking during the generation process. This involves creating direct connections between generated content and its source material. Your system should track where each piece of information comes from, verify facts against trusted databases in real-time, and maintain clear links back to original documentation. Setting confidence thresholds helps determine when the model should provide an answer versus acknowledging uncertainty.
Post-generation validation serves as your final defense against hallucinations. This involves building a comprehensive validation pipeline that automatically checks generated content against source materials. The system runs fact-checking routines on outputs, comparing them with verified information from your trusted sources. Any discrepancies get flagged for review, and all validation results are logged for analysis and system improvement.
High-risk areas for generative AI Hallucinations
AI hallucinations create critical problems in domains where accuracy directly impacts user safety, trust, and compliance. In healthcare systems, generative AI hallucinations can lead to dangerous situations if the model fabricates symptoms, treatments, or drug interactions that could harm patients. For financial services, AI hallucinations pose significant risks when models generate incorrect market analysis, financial advice, or regulatory compliance information, potentially leading to costly decisions or legal issues.
In customer support, AI hallucinations can damage brand reputation and user trust when chatbots provide incorrect product information or made-up policy details. Content generation tools face similar challenges - generative AI hallucinations in educational content, technical documentation, or news articles can spread misinformation at scale. Legal applications are particularly vulnerable, as AI hallucinations in contract analysis or legal research could lead to serious professional consequences.
Building trust with guardrails to reduce AI hallucinations
Guardrails aren’t a magic bullet, but they’re a powerful step toward more reliable AI systems. By grounding outputs in verified sources or rules, you can significantly reduce generative AI hallucinations and build trust with users.
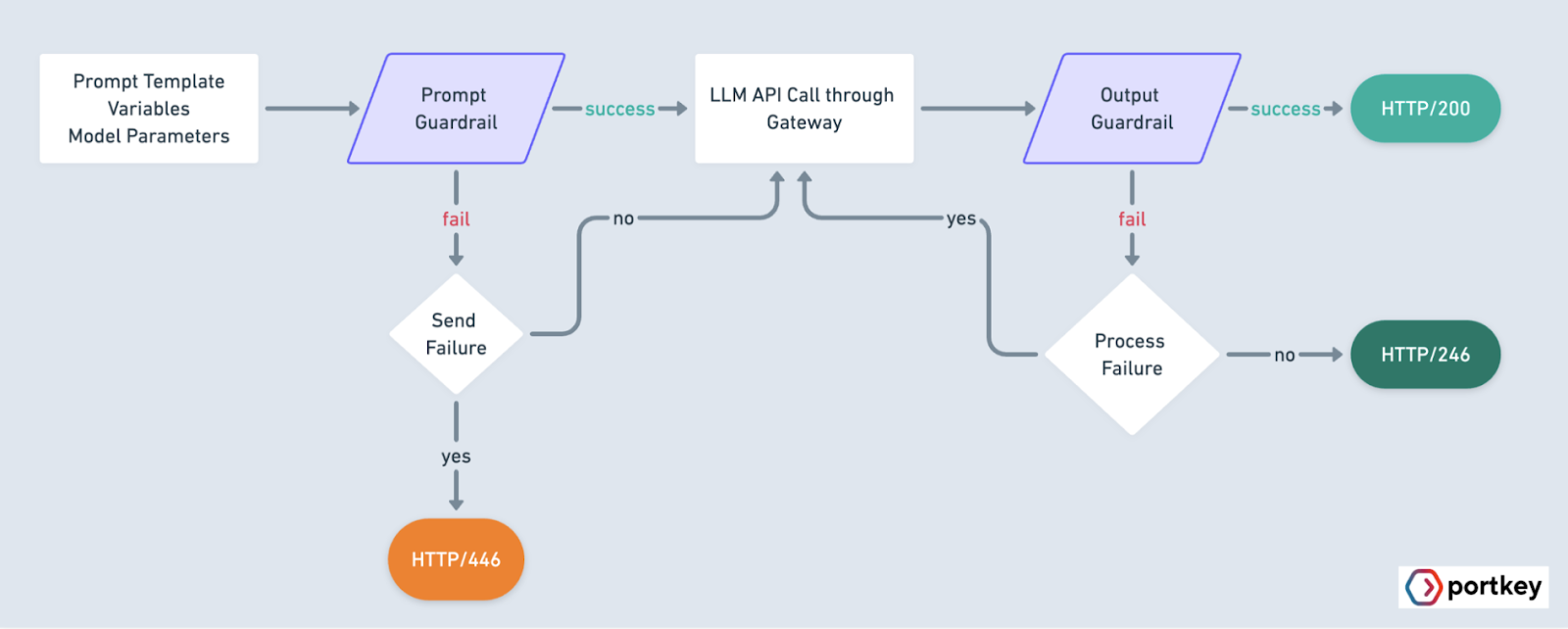
With Portkey’s guardrails and its seamless integration with leading tools, implementing these safeguards is straightforward and highly effective. If hallucinations are a recurring headache for your projects, it’s worth exploring how Portkey can elevate your AI stack. Ready to try it out?

