

Tackling rate limiting for LLM apps
Learn how rate limits affect LLM applications, what challenges they pose, and practical strategies to maintain performance.
Running into API rate limits with your LLM app? You're not alone. As these AI models become more central to our applications, we're all trying to figure out how to scale them without breaking the bank - or the infrastructure.
Maybe you're building a real-time chat application, or you need to process thousands of documents in a batch. Either way, hitting these limits can throw a wrench in your plans, leading to latency, denied requests, or increased operational complexity.
Why do providers impose rate limits?
Each time someone hits your API for completion or embedding, it takes serious computational power. Without rate limits, a spike in traffic could bring your infrastructure to its knees.
Also, if you’re running a shared LLM service, one power user can start hammering your API with requests. Without rate limiting, they could hog all the resources, leaving other users waiting in line. Rate limits help you split up these resources fairly, making sure everyone gets their share of processing time.
Then there's the security angle. LLM APIs are prime targets for abuse. Rate limiting acts as your first line of defense, making it harder for bad actors to misuse your service at scale.
Lastly, if you're running a business-critical service, you need to meet your service level agreements (SLAs). Rate limiting helps you guarantee response times and availability for your paying customers by preventing any single user or workload from monopolizing your resources.
Types of rate limits
- Per-second limits: Restrict the number of requests allowed per second. Ideal for consistent throughput.
- Per-minute/hour limits: Broader caps over slightly longer intervals.
- Daily limits: Ceiling on the total number of requests over 24 hours, usually for subscription-based tiers.
Rate limits imposed by various providers:
Challenges posed by rate limits
Rate limits can introduce several hurdles when developing and scaling LLM applications.
When rate limits are reached, the application experiences delayed or blocked requests, which directly slows down response times. In real-time applications like customer support chatbots or live content generation, this can lead to significant latency. The throughput of the system is also throttled, meaning fewer requests can be processed in the same time frame, reducing overall system efficiency.
As usage increases, scaling an application that depends on LLMs becomes tricky. Without efficient rate-limiting management, you may run into ceilings where the infrastructure can no longer handle peak loads. During peak times, some users might not be able to use your service at all.
Cost is another factor. The costs of running LLM-based applications can escalate quickly, especially when rate limits are factored in. To handle high volumes of requests, businesses may need to subscribe to higher-tier plans, increasing operational expenses. Also, inefficient API usage, like excessive requests that don’t contribute to meaningful outputs, can further inflate costs.
For applications that rely on processing large amounts of data or performing batch operations, rate limits can be a huge problem. Batch processing tasks, which are often used for analyzing large datasets or generating substantial outputs, can get delayed or disrupted when the rate limit is hit.
And all these challenges add up to UX issues, potentially frustrating the users who just want your app to work smoothly.
Common Rate Limiting Methods (And Their Breaking Points)
Here are the standard ways teams tackle rate limiting in LLM apps:
Caching is great for cutting down API calls for FAQs or repetitive prompts. But cache management gets messy fast - you need logic for cache invalidation, storage limits, and deciding what's worth caching.
Queue systems help smooth out traffic spikes by creating an orderly line of requests. Works well until queues get too long and users start timing out. Plus, managing queue priority for different user tiers adds complexity.
Request batching lets you pack multiple prompts into one API call. Smart for bulk operations, but you need careful request routing and error handling. One failed request in a batch can impact all users.
But when you stack these approaches together, you're looking at a complex system that needs its own maintenance team. As your user base grows, you'll face new edge cases and scaling challenges. Each optimization adds another layer to debug when things go wrong.
How to tackle rate limits
Let's talk about how Portkey makes rate limits less of a headache. The AI Gateway has some smart features that keep your app running smoothly even when you're pushing the limits.
- Fallback to Alternative LLMs
Rate limit errors are common than you think -
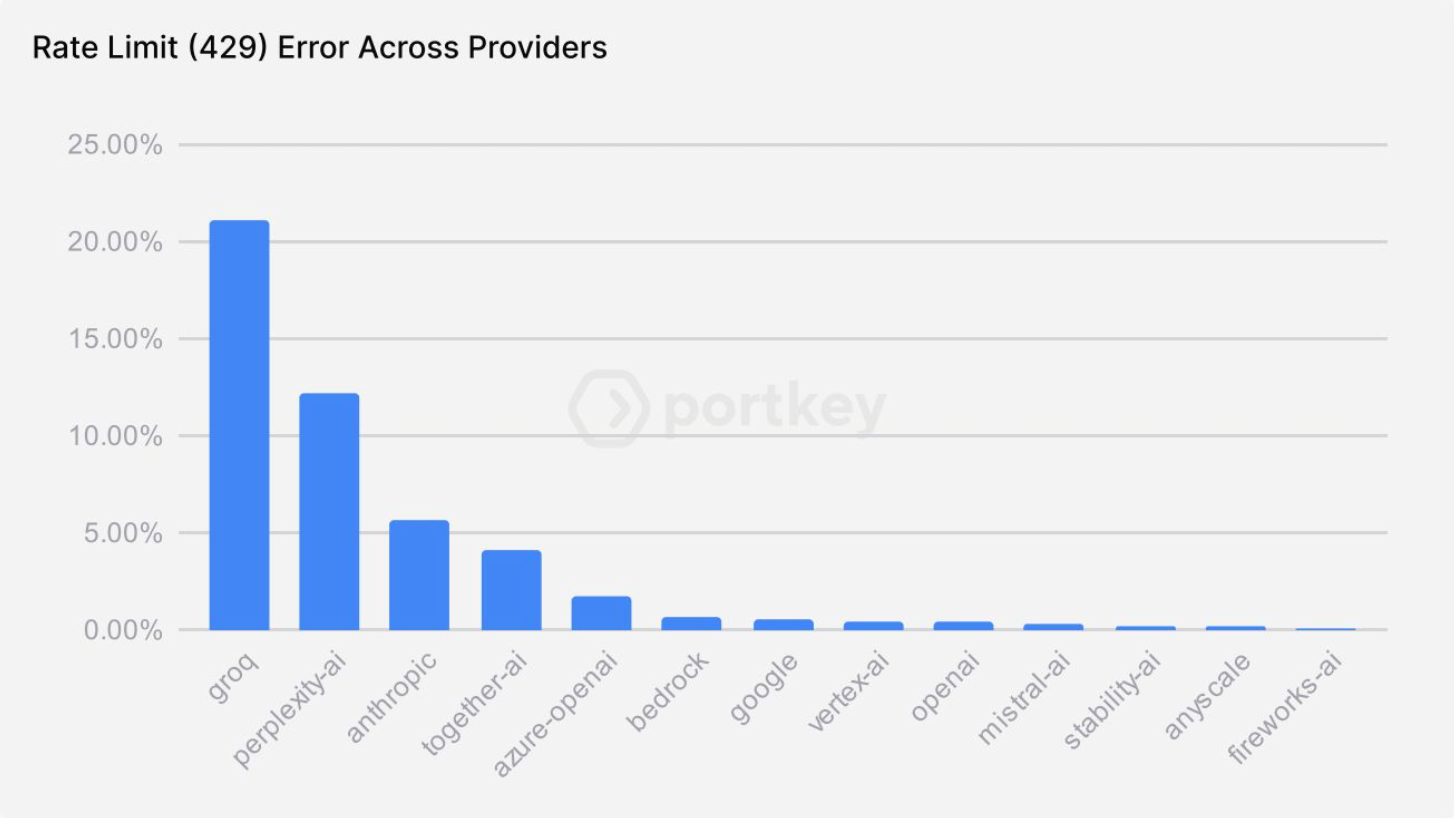
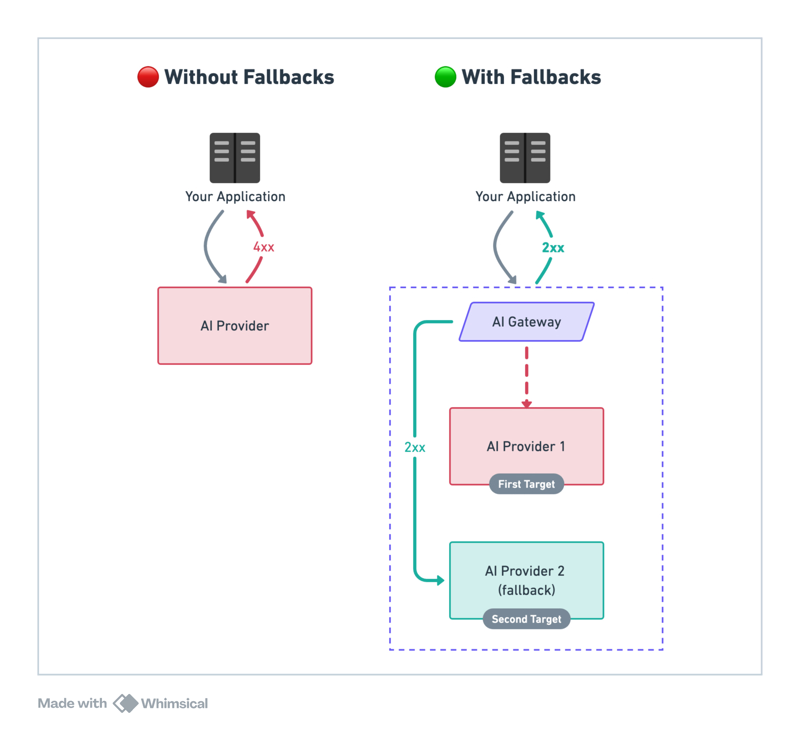
When an LLM provider’s rate limit is reached, Portkey can seamlessly switch to another provider, ensuring uninterrupted service without manual intervention. This automated fallback mechanism ensures that your application continues to function even if one provider is at capacity.
This also solves the scaling issues we talked about earlier - your app keeps running during peak times, and users don't face service disruptions - helpful for real-time applications where response time is critical.
2. Load Balancing and Retries
To avoid overburdening any single account, Portkey distributes API requests across multiple accounts. This effectively increases your total available request quota, enabling your system to scale efficiently without exceeding rate limits.
In case of failure, Portkey can automatically retry requests that failed due to rate limits, reducing the chance of disruptions. With retries, the system maintains operational continuity and ensures that requests are processed smoothly, even during high-traffic periods.
This directly addresses the speed and throughput issues - you can process more requests simultaneously. It's especially useful for batch processing since you can handle larger workloads without scheduling complex workarounds.
3. Caching
Portkey enhances rate-limiting management with both simple and semantic caching. Simple caching stores basic query responses for reuse, and semantic caching handles more complex interactions by reusing context-sensitive data. This reduces API calls and allows for faster response times, reducing strain on the system and keeping your app within rate limits.
This tackles both cost concerns and user experience - you're not wasting quota on repeated requests, responses are faster, and users get smoother interactions.
Portkey's observability layer provides real-time monitoring of API usage, offering detailed insights into request patterns, response times, and potential bottlenecks. This data allows teams to monitor API performance, optimize resource allocation, and adjust request throttling to stay within limits.
Portkey's observability
Handling rate limiting is essential for maintaining the performance, reliability, and scalability of LLM applications. By using Portkey’s AI Gateway, businesses can efficiently manage rate limits with features like fallback to alternative LLMs, load balancing and retries, caching, and advanced error handling. Additionally, the observability feature enables real-time monitoring, ensuring proactive adjustments before rate limits cause disruptions. These strategies work together to enhance system stability, reduce latency, and improve user experience, allowing your LLM application to scale seamlessly without hitting bottlenecks.
Ready to implement these strategies? Get started today to or talk to the experts at Portkey by booking a slot here.

