
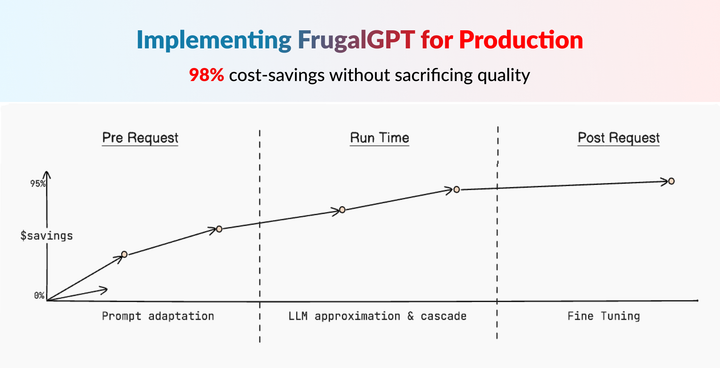
⭐️ Implementing FrugalGPT: Reducing LLM Costs & Improving Performance
FrugalGPT is a framework proposed by Lingjiao Chen, Matei Zaharia, and James Zou from Stanford University in their 2023 paper "FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance". The paper outlines strategies for more cost-effective and performant usage of large language model
