LLM access control in multi-provider environments Learn how LLM access control works across multi-provider AI setups, including roles, permissions, budgets, rate limits, and guardrails for safe, predictable usage.
How to implement budget limits and alerts in LLM applications Learn how to implement budget limits and alerts in LLM applications to control costs, enforce usage boundaries, and build a scalable LLMOps strategy.
Using metadata for better LLM observability and debugging Learn how metadata can improve LLM observability, speed up debugging, and help you track, filter, and analyze every AI request with precision.
What is AI interoperability, and why does it matter in the age of LLMs Learn what AI interoperability means, why it's critical in the age of LLMs, and how to build a flexible, multi-model AI stack that avoids lock-in and scales with change.
Bringing GenAI to the classroom Discover how top universities like Harvard and Princeton are scaling GenAI access responsibly across campus and how Portkey is helping them manage cost, privacy, and model access through Internet2’s service evaluation program.
What is LLM Orchestration? Learn how LLM orchestration manages model interactions, cuts costs, and boosts reliability in AI applications. A practical guide to managing language models with Portkey
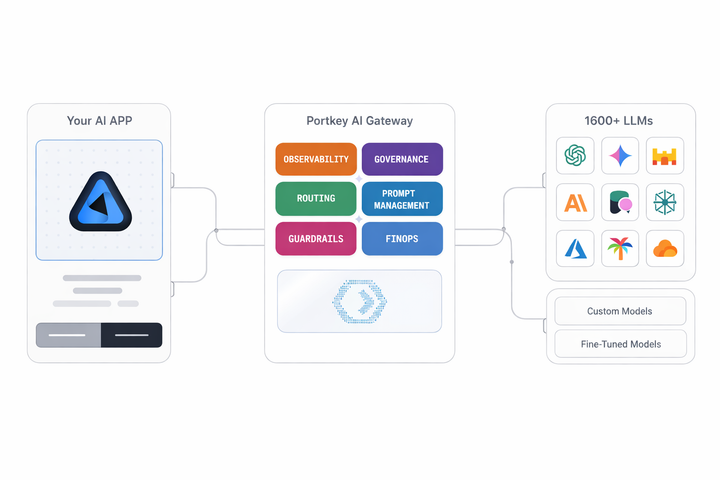
What is an LLM Gateway? Understand how LLM Gateways help organizations run LLMs as shared infrastructure with consistent governance, security, and observability.