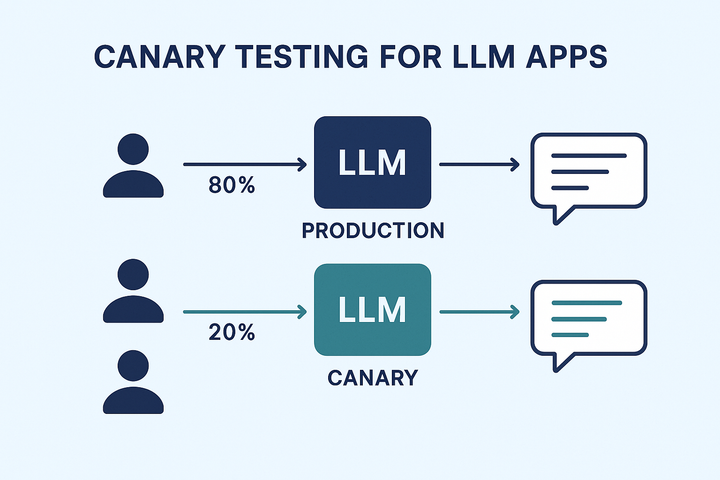
Canary Testing for LLM Apps Learn how to safely deploy LLM updates using canary testing - a phased rollout approach that lets you monitor real-world performance with a small user group before full deployment.
LLM Grounding: How to Keep AI Outputs Accurate and Reliable Learn how to build reliable AI systems through LLM grounding. This technical guide covers implementation methods, real-world challenges, and practical solutions
What is LLM Orchestration? Learn how LLM orchestration manages model interactions, cuts costs, and boosts reliability in AI applications. A practical guide to managing language models with Portkey
How to improve LLM performance Learn practical strategies to optimize your LLM performance - from smart prompting and fine-tuning to caching and load balancing. Get real-world tips to reduce costs and latency while maintaining output quality
How to scale AI apps - Lessons from building a billion-scale AI Gateway Discover the journey of Portkey.ai in building a billion-scale AI Gateway. Learn key lessons on managing costs, optimizing performance, and ensuring accuracy while scaling generative AI applications.
⭐ Building Reliable LLM Apps: 5 Things To Know In this blog post, we explore a roadmap for building reliable large language model applications. Let’s get started!
⭐ Semantic Cache for Large Language Models Learn how semantic caching for large language models reduces cost, improves latency, and stabilizes high-volume AI applications by reusing responses based on intent, not just text.