The best approach to compare LLM outputs
Once LLMs are in production, output quality stops being a subjective question and becomes an operational one. Teams are no longer asking whether they need to evaluate outputs, but how to do it reliably as systems evolve.
Production systems can change frequently. Prompts are iterated on, models are swapped, routing logic is adjusted, and traffic patterns shift. In this environment, point-in-time judgments of quality are not useful. What matters is whether output quality is stable, improving, or degrading across these changes.
A repeatable approach to measurable output quality gives teams a way to:
- Establish baselines that survive prompt and model updates
- Compare outputs across versions, providers, and configurations
- Detect regressions before they reach users
- Reason about trade-offs between quality, latency, and cost
Is manual review and one-off prompting enough to compare LLM outputs?
Manual review and ad-hoc prompting still play a role in mature LLM systems, but they stop being sufficient once scale and change are introduced.
Spot-checking outputs is inherently narrow. Reviewers see a small slice of traffic, often curated or synthetic, and their judgments are shaped by context that may not exist in real usage. As prompts and models evolve, those reviews quickly become outdated. What was “approved” last week may no longer reflect what users are seeing today.
One-off prompting has similar limitations. Testing a handful of inputs against a new model or prompt can reveal obvious failures, but it does not capture variance. Non-determinism means two runs of the same prompt can produce meaningfully different outputs. Without repetition and aggregation, it’s impossible to tell whether a change actually improved quality or simply produced a better-looking example.
At scale, manual review also introduces inconsistency. Different reviewers apply different standards, and those standards shift over time. There is no durable baseline, no reliable way to compare runs across days or deployments, and no systematic way to surface regressions early.
Manual review remains useful for:
- Calibrating evaluation criteria
- Investigating edge cases
- Providing high-quality labels for difficult tasks
But as the primary mechanism for comparing LLM outputs, it breaks down. Production systems need methods that are repeatable, aggregatable, and resilient to change.
Metrics to consider when comparing LLM outputs
The core dimensions:
Effective LLM evaluation requires metrics that map to the actual risks and goals of your application. Most production systems care about three primary dimensions:
1. whether the output is factually grounded (hallucination detection),
2. whether it addresses what the user actually asked (relevance and correctness), and
3. whether it meets safety and quality standards (toxicity, coherence, formatting).
These dimensions are not interchangeable. A response can be highly relevant but factually wrong, or factually correct but unhelpful. Choosing which metrics to track depends on what failure modes matter most for your use case.
Deterministic vs. LLM-based metrics:
Metrics fall into two categories: deterministic and model-based.
Deterministic metrics like regex matching, JSON validation, and keyword presence are fast, cheap, and predictable. They work well for structured outputs or hard constraints.
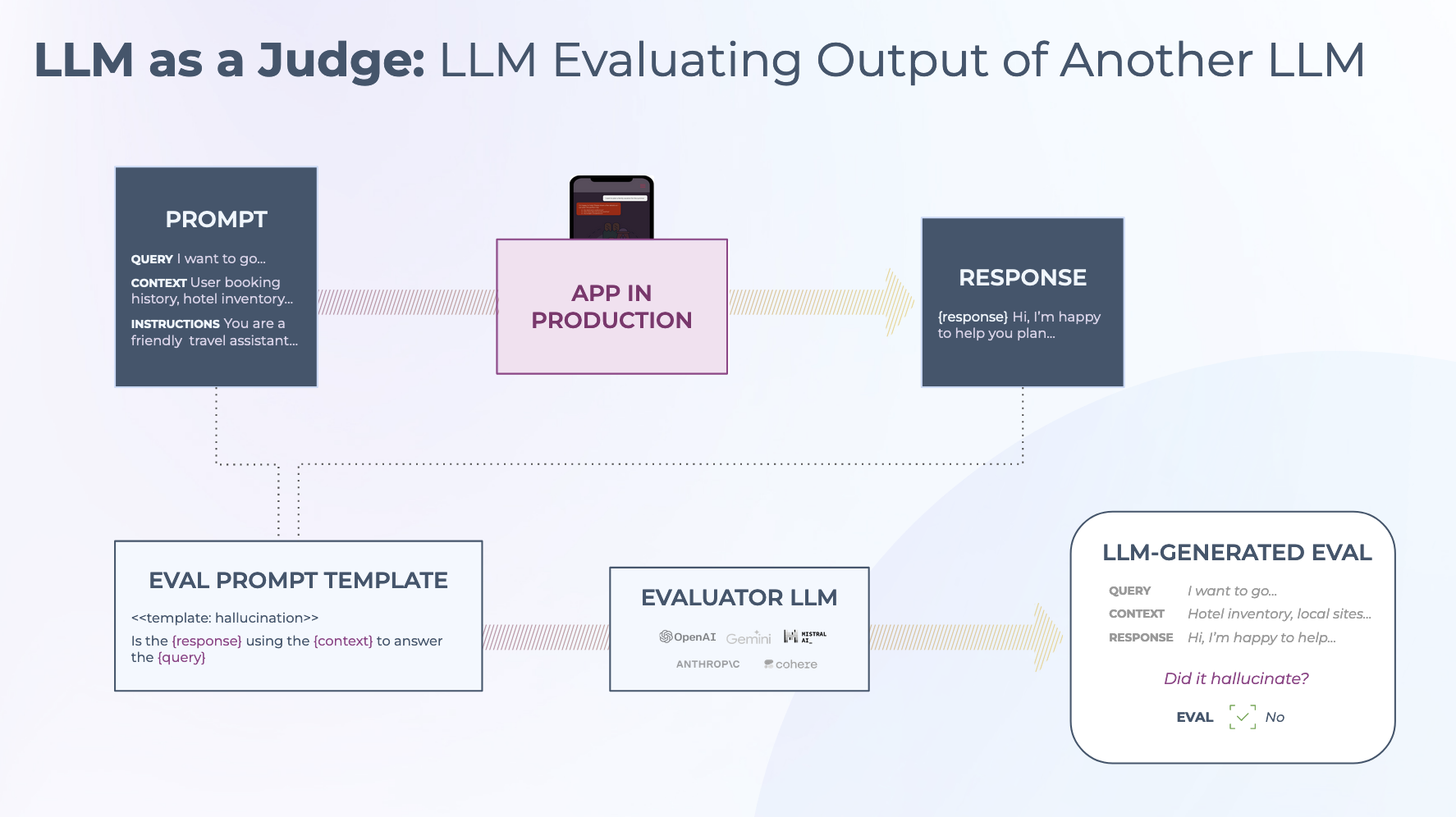
Model-based metrics use an LLM to judge another LLM's output, which is necessary for evaluating qualities like coherence, completeness, or whether an answer is actually helpful. LLM-as-a-judge approaches are more expensive and introduce their own variance, but they scale where human review cannot. In practice, most teams use both: deterministic checks for objective criteria, model-based evaluation for subjective quality.
Choosing the right granularity:
Metrics also differ in scope.
- Span-level evaluation scores individual LLM calls, useful for isolating which step in a pipeline is underperforming.
- Trace-level evaluation looks at the full chain of reasoning, which matters when correctness depends on multiple steps working together.
- Session-level evaluation captures user experience across a conversation, surfacing issues like frustration or confusion that only emerge over time.
Comparing outputs effectively means instrumenting at the right level and aggregating results in ways that surface actionable patterns, not just individual failures.
How Arize approaches evals
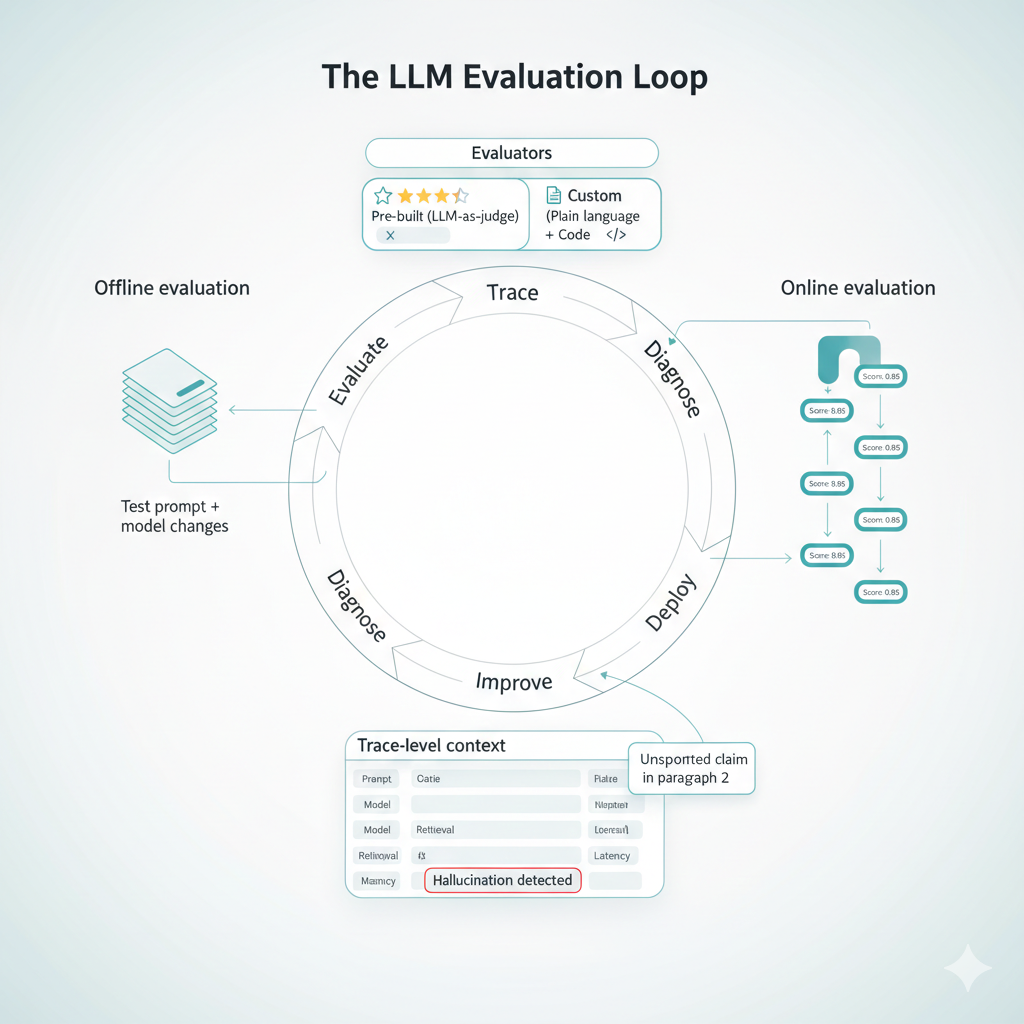
The evaluation loop:
Arize treats evaluation as an operational loop, not a one-time gate. Evaluations attach directly to traces, so every LLM call can be scored and explained in context. This means teams can run evaluations offline during development, testing prompt changes against datasets before deployment, and then transition the same evaluators to run online against production traffic. The result is a continuous feedback mechanism: evaluations surface regressions, traces provide the context to diagnose them, and experiments validate fixes before they ship.
Pre-built and custom evaluators:
The platform includes pre-built LLM-as-a-judge evaluators for common concerns: hallucination, relevance, toxicity, summarization quality, code correctness, and user frustration, among others. These templates are benchmarked against golden datasets with known precision and recall, so teams can deploy them with confidence. For domain-specific needs, custom evaluators can be defined in plain language, describing what "good" looks like in the same way you would brief a human reviewer, or implemented as deterministic code for objective criteria. Evaluators are versioned and reusable across projects, which keeps evaluation criteria consistent as systems evolve.
Explainability and action:
Every evaluation produces not just a label or score, but an explanation. This matters because knowing that an output was marked "hallucinated" is less useful than understanding why: which claim was unsupported, which context was missing. Explanations make evaluations actionable: they point teams toward specific retrieval failures, prompt gaps, or model limitations. Combined with trace-level observability, this turns evaluation from a reporting mechanism into a diagnostic tool that accelerates iteration.
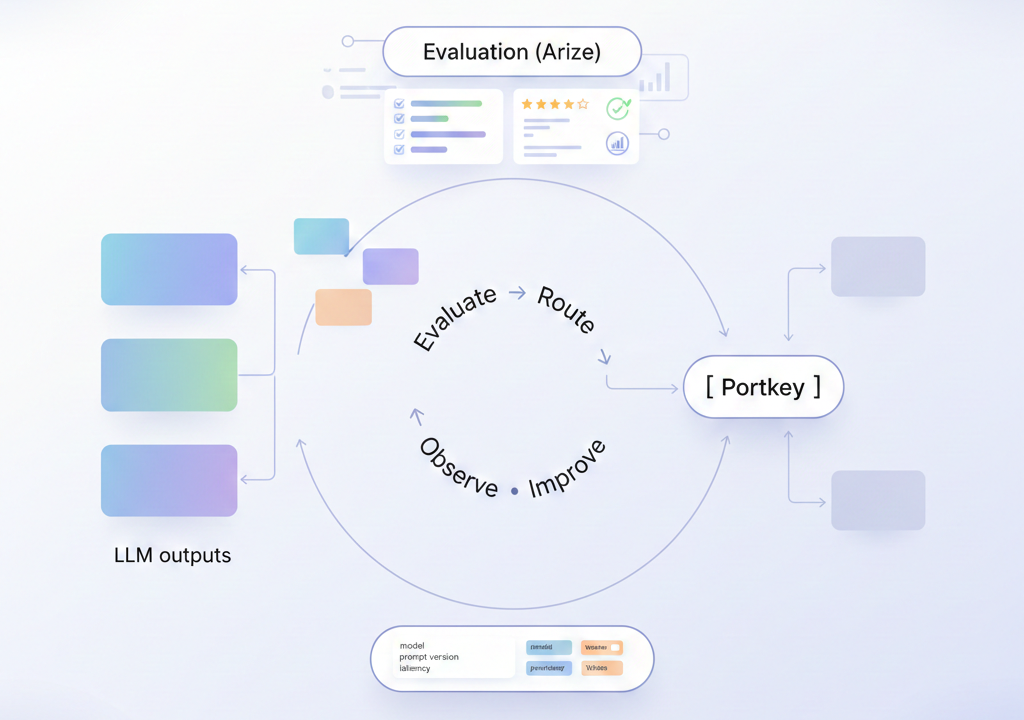
Completing the loop with Portkey: routing and orchestration for evaluations
Running meaningful LLM evaluations requires more than scoring outputs in isolation. Teams need a reliable way to orchestrate how different models, prompts, and configurations are exercised so that comparisons are intentional and repeatable.
By acting as a routing layer for LLM traffic, Portkey's AI Gateway makes this orchestration straightforward. Multiple models and providers can be invoked through a single, consistent API, allowing teams to evaluate alternatives side by side without changing application code. The same inputs can be routed to different models, prompt versions, or configurations as part of structured evaluation runs.
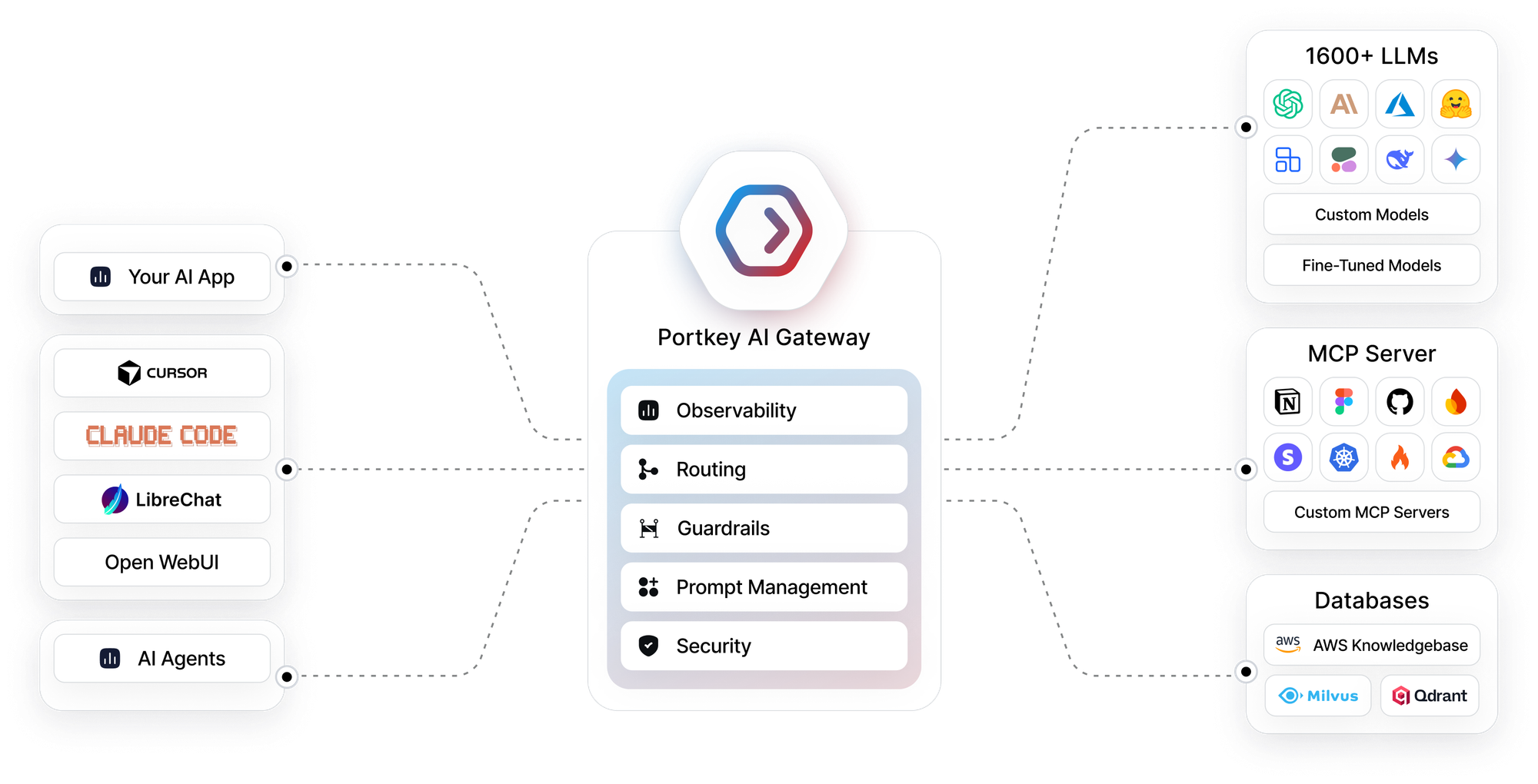
This becomes especially useful when evaluations move closer to production. Instead of maintaining separate pipelines for testing and live traffic, teams can reuse the same routing logic to:
- Compare models under identical conditions
- Test prompt changes against real inputs
- Run controlled experiments alongside production traffic
Observability ensures that these evaluations remain interpretable. Every request captures the context needed to explain outcomes: which model was used, how it was routed, which prompt version was applied, and how the system performed in terms of latency and cost.
Together, routing and observability turn evaluations into an operational loop. Results from Arize evaluations can be traced back to the exact model and routing decisions that produced them, making it easier to act on those insights and iterate with confidence.
To try it out, get started with Portkey for free (Portkey is open source!)
Book a demo with our experts if you're looking to deploy AI Agents in production!