
The Complete Guide to Prompt Engineering
What is Prompt Engineering?
At its core, prompt engineering is about designing, refining, and optimizing the prompts that guide generative AI models. When working with large language models (LLMs), the way a prompt is written can significantly affect the output. Prompt engineering ensures that you create prompts that consistently generate accurate and useful responses across different scenarios and projects.
For developers, this means having a clear process for crafting, testing, and improving prompts over time. As you handle more prompts, keeping them organized and fine-tuned becomes essential. That's where prompt engineering practices come into play—helping you create effective prompts, monitor performance, and improve as needed.
Key concepts to know:
- Prompt Versioning: Like version control in software, prompt versioning helps you track changes and test different iterations of your prompts. You can go back to earlier versions if a new prompt isn’t working as expected.
- Prompt Efficiency: Some prompts will deliver better results faster. Part of prompt engineering involves figuring out which prompts are most efficient for your specific use case and tweaking them to optimize performance.
Use the latest models in LibreChat via Portkey and learn how teams are running LibreChat securely with RBAC, budgets, rate limits, and connecting to 1,600+ LLMs all without changing their setup.
To join, register here →
Basics of Prompt Engineering and Tips to Design Prompts
What Makes a Good Prompt?
Crafting effective prompts isn’t just about putting in the right words—it’s about understanding how the model interprets language and providing clear, concise instructions.
Here are some essential tips for designing effective prompts:
1. Be Clear and Specific
LLMs perform best when given clear, unambiguous instructions. If your prompt is too vague, the model might return a broad or irrelevant answer. Instead of saying “Summarize this document” be more specific, like “Summarize this document in 3 bullet points focusing on the main challenges discussed.”
Tip: Use structured instructions. Break down complex tasks into smaller, manageable parts to avoid confusing the model.
2. Set the Right Context
For models to generate the correct output, it’s important to provide the right context. This can include examples of the desired output, specific rules the model should follow, or background information relevant to the task. For instance, if you're generating customer support responses, include a description of the problem and desired tone.
Tip: When possible, include examples that illustrate the format or content you're expecting. This helps guide the model to stay on track.
3. Use Constraints Where Necessary
Sometimes, LLMs might produce overly verbose or irrelevant answers. By adding constraints to your prompts, you can guide the model to give more focused responses. For example, limit the word count (“Give a 100-word explanation”) or specify the format (“Answer in JSON format”).
Tip: Constraints are especially useful when you need concise or structured outputs for further automation or processing.
4. Test and Iterate
Prompt engineering is rarely a one-shot process. You may need to test and tweak your prompts multiple times to get the desired output. Experiment with different phrasings, instructions, and levels of detail to see what works best for your particular use case.
Tip: Always evaluate outputs from different prompt iterations, and refine them until they meet the expected quality consistently.
5. Adapt to the Model’s Strengths
Each LLM has its quirks and strengths, so it's important to adapt your prompts to the specific model you're working with. Some models may excel at creative writing, while others are better at technical tasks. Tailoring your prompts to the model’s known strengths can significantly improve results.
Tip: Familiarize yourself with the model’s documentation to understand its capabilities and limitations before designing your prompts.
Tweaking LLMs for Prompt Engineering
Why Tweak LLMs?
While designing effective prompts is crucial, sometimes the large language model (LLM) itself may need to be adjusted to better handle specific tasks. Tuning the LLM to understand and respond to your prompts more effectively can save time and improve the quality of outputs. This process of tweaking an LLM can involve adjusting how you interact with the model or even customizing parts of the model itself.
Adjusting Hyperparameters
Hyperparameters control how an LLM operates. By tweaking parameters like temperature, top-p, or max tokens, you can influence how creative, concise, or detailed the model's responses will be.
Key Hyperparameters:
- Temperature: Controls randomness in the model’s output. A higher temperature makes the responses more creative, while a lower temperature makes the output more focused and deterministic.
- Top-p (Nucleus Sampling): Instead of choosing from all possible word predictions, top-p sampling limits the model’s choices to the most probable outcomes, which helps create more coherent and relevant responses.
- Max Tokens: Limits the length of the output. If the model is generating responses that are too long or too short, adjusting this parameter helps fit the desired output length.
How It Helps:
- Allows you to control whether the model should be more creative or deterministic.
- Helps refine the level of detail or conciseness in the output based on your needs.
Prompt Engineering Techniques
Prompt engineering is not a one-size-fits-all approach. Depending on the task, different techniques can help refine and optimize the way prompts interact with large language models (LLMs). The goal is to make prompts more effective, consistent, and adaptable across various applications.
Let’s explore some common prompt engineering techniques that can be useful across a wide range of use cases:
1. Zero-Shot Prompting
Zero-shot prompting involves giving the LLM a task without any prior examples or additional context. The model must rely on its pre-trained knowledge to complete the task based solely on the prompt. This technique is ideal when the task is relatively straightforward, and the LLM’s general knowledge should be enough to generate accurate results.
Example:
“Explain the theory of relativity in simple terms for a high school student.”
2. Few-Shot Prompting
Few-shot prompting provides the LLM with a few examples within the prompt to guide it toward the desired output. By showing how you want the model to perform a task, it becomes more likely to generate the correct response. This technique works well for tasks where consistency in tone or format is important, such as customer service, writing assistance, or structured content generation.
Example:
“Here’s how to answer a customer inquiry: Example 1: ‘I understand your concern, and we’ll resolve it immediately.’ Example 2: ‘We apologize for the inconvenience. Let us assist you with a quick solution.’ Now, respond to the following inquiry: [Insert inquiry].”
3. Chain-of-Thought Prompting
Chain-of-thought prompting breaks down complex tasks into smaller steps, allowing the model to process each stage in sequence. This helps the model tackle tasks that require reasoning or step-by-step analysis. Ideal for tasks that involve multi-step reasoning, such as solving math problems, generating complex written responses, or analyzing detailed information.
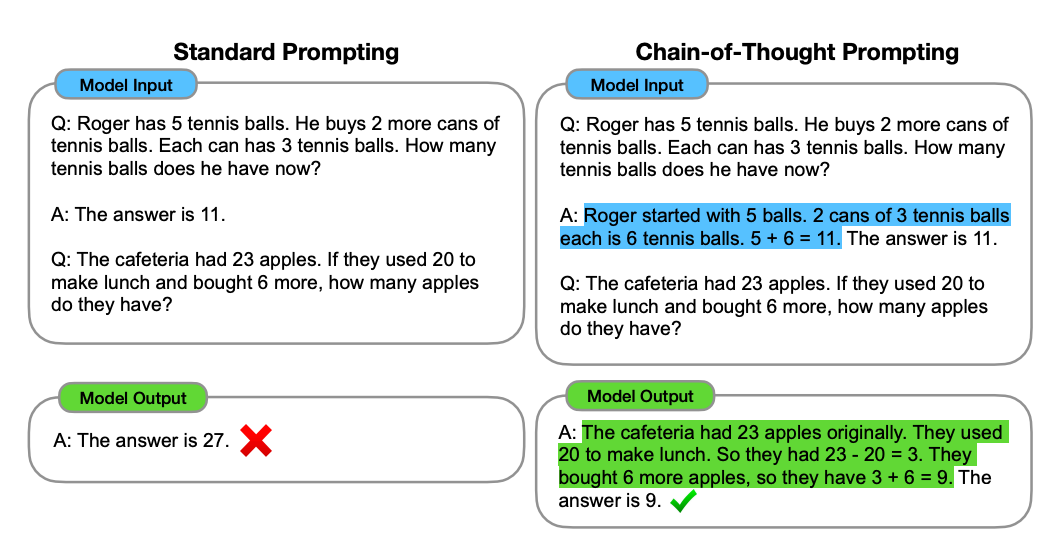
Example:
“Step 1: Identify the customer’s main concern. Step 2: Acknowledge their issue. Step 3: Provide a clear solution or next steps. Now, respond to this customer query: [Insert query].”
4. Prompt Chaining
Prompt chaining involves using multiple, smaller prompts to complete a task. Each prompt builds on the result of the previous one, allowing the LLM to handle larger, more complex tasks in stages. Useful for content generation, data analysis, or tasks that require large-scale outputs that would be too complex for a single prompt.
Example:
Prompt 1: “Generate an outline for an article about climate change.”
Prompt 2: “Write an introduction for the article based on this outline.”
Prompt 3: “Now expand on each section in the outline.”
5. Iterative Prompting
Iterative prompting involves refining a prompt based on the model’s initial output. You evaluate the response, adjust the prompt, and resubmit it to improve the results, ensuring the output meets your needs. Best for creative tasks or projects where you need to refine the result over multiple iterations to get a specific outcome.
Example:
Prompt 1: “Write a product description for a new smartwatch.”
(If the output is too vague)
Prompt 2: “Write a product description for a new smartwatch, focusing on its health tracking features and sleek design.”
6. Contextual Prompting
In contextual prompting, you provide the LLM with detailed background information or constraints so it can generate a response that aligns with your specific requirements. Useful when the model needs to adhere to a specific domain or context, such as technical writing, specialized reports, or industry-focused content.

Example:
“You are an expert in cybersecurity. Based on the latest developments in ransomware attacks, write an analysis focusing on prevention strategies for small businesses.”
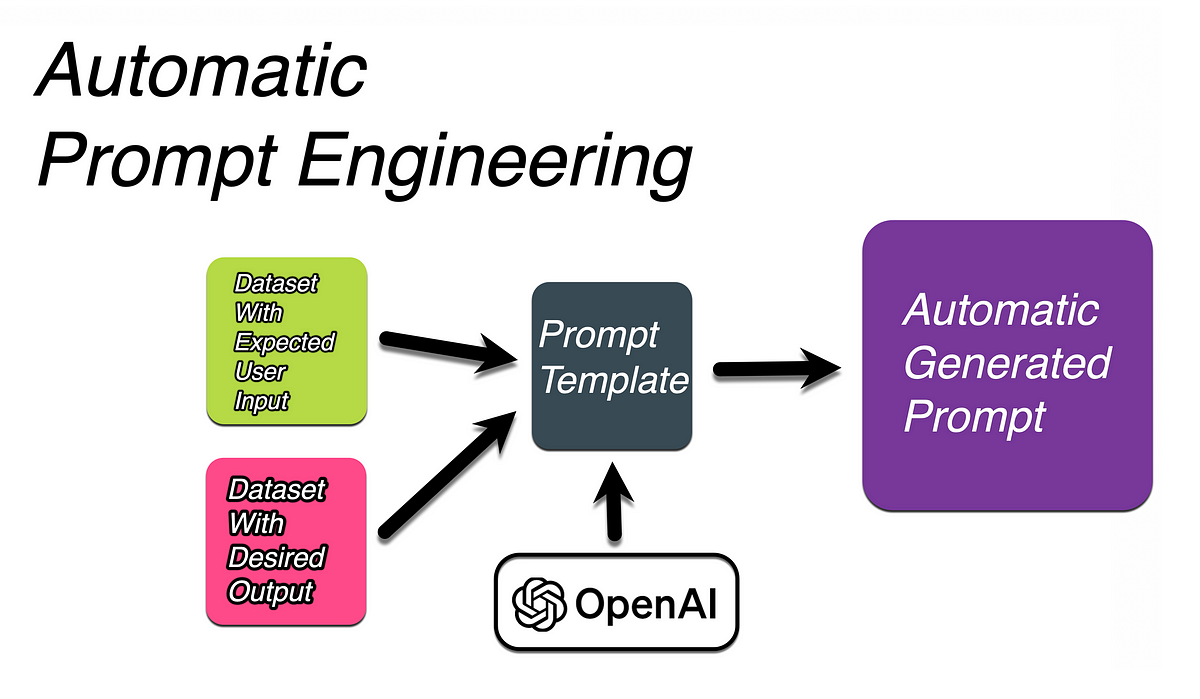
7. Automatic Prompt Engineering
Automatic prompt engineering leverages AI tools to generate, refine, or optimize prompts, reducing manual efforts and uncovering prompt variations that may produce better results. This approach is especially useful when handling complex prompts or high volumes, as it automates much of the trial-and-error process, allowing teams to focus on higher-level optimizations.
Benefits:
- Speeds Up Prompt Iteration: By automating parts of the process, you can quickly test numerous prompt variations without manually designing each one.
- Improves Prompt Quality: With a constant cycle of feedback and adjustments, automatic prompt engineering refines prompts faster, leading to higher-quality outputs.
- Reduces Manual Effort: Automating the generation and testing of prompts allows developers to focus on fine-tuning and implementing high-impact prompts rather than on repetitive iterations.
8. Prompt Engineering with DSPy
DSPy (Declarative Standard Prompting) simplifies prompt engineering by automating and standardizing prompt creation, especially in complex workflows. This tool helps developers define prompts declaratively, so they don’t have to craft each prompt manually. Instead, DSPy generates optimized prompts according to predefined rules and templates, making it a great fit for automatic prompt engineering.
Using DSPy standardizes prompt creation by enforcing consistency through predefined templates and rules, which allows teams to scale prompt generation efficiently without extensive manual crafting. Its automation capabilities speed up iteration, letting developers test and refine prompts faster, while also reducing the need for prompt-writing expertise.
How to Manage Prompts Without Making Changes to Production
Managing prompts effectively is essential for ensuring the quality and reliability of outputs from large language models (LLMs) in production settings. Changes to prompts can impact performance, so it’s crucial to implement strategies that allow you to manage and optimize prompts without directly altering live production environments.
Below are some best practices for effective prompt management:
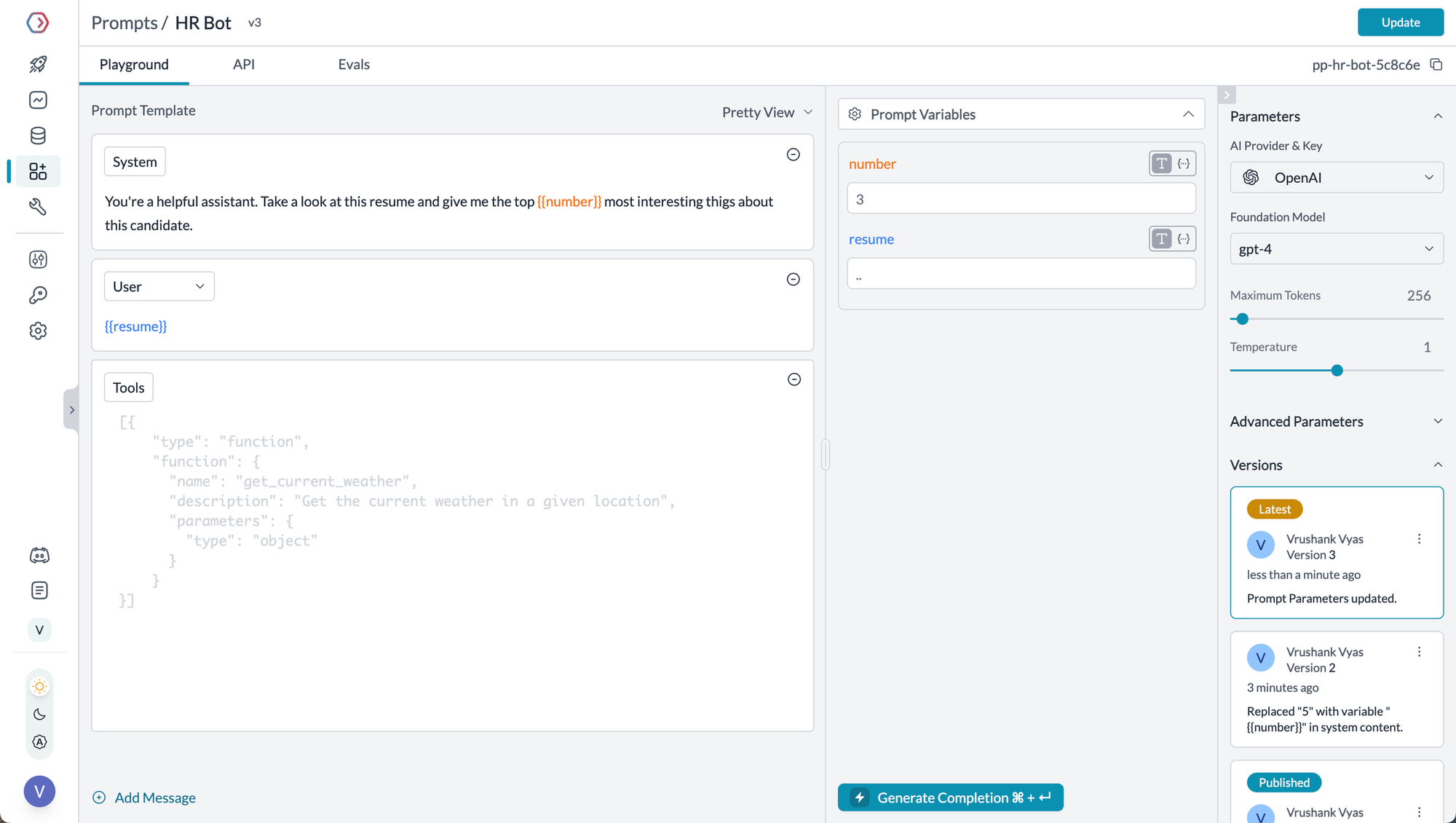
1. Centralized Prompt Library
A centralized prompt library serves as a repository for well-crafted prompts, allowing teams to standardize and share effective prompts across different projects.
How to Implement:
- Create a prompt library within Portkey where all approved prompts are categorized and easily searchable.
- Include metadata such as use cases, success rates, and associated tasks to provide context for each prompt.
Benefits:
- Promotes consistency in prompt usage across projects.
- Facilitates knowledge sharing and best practices among team members.
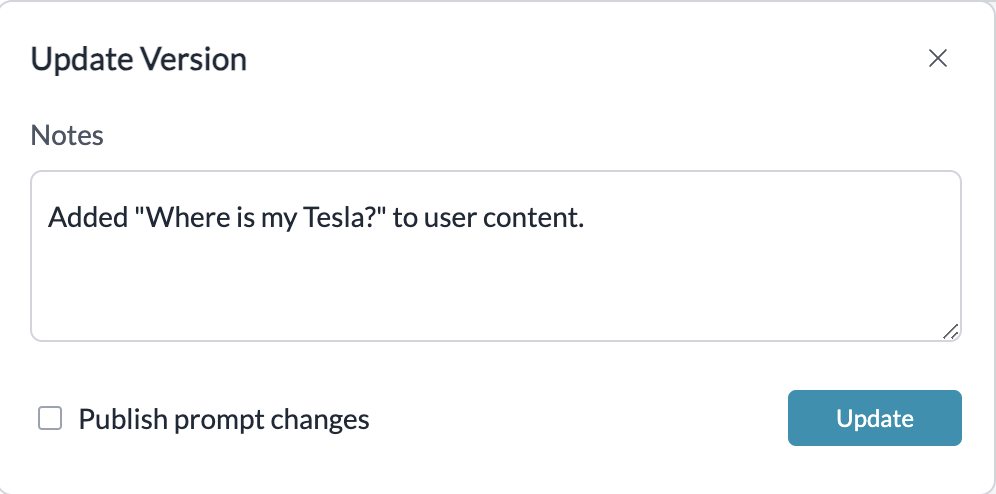
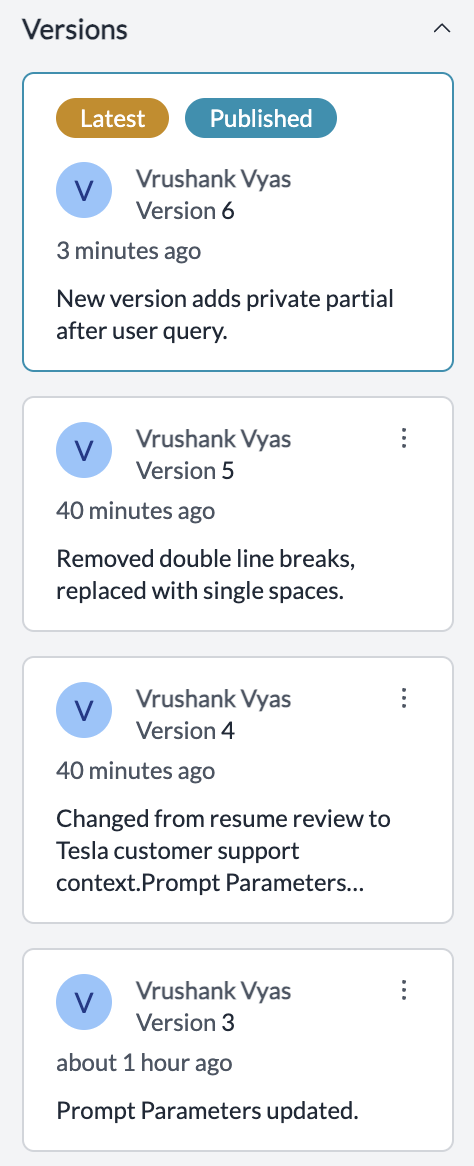
2. Version Control for Prompts
Version control allows teams to track changes made to prompts over time, enabling them to roll back to previous versions if new prompts do not yield the desired results.
How to Implement:
- Utilize Portkey's built-in prompt versioning features to document each prompt's history, including the rationale for changes.
- Maintain a change log that captures when prompts were updated and by whom.
Benefits:
- Provides a clear history of prompt evolution.
- Ensures easy rollback to earlier versions if needed.
3. Monitor Performance Metrics
Regularly assessing prompt performance helps identify which prompts are effective and which require refinement.
How to Implement:
- Leverage analytics tools within Portkey's LLM Gateway to set up performance metrics such as response accuracy and user satisfaction for prompts in production.
- Use dashboards to visualize prompt performance and track changes over time.
Benefits:
- Allows for data-driven decisions regarding prompt management.
- Helps identify trends or patterns that may require adjustments.
As organizations increasingly rely on AI to drive decision-making and enhance user experiences, mastering prompt engineering will become more critical than ever. Portkey can play a vital role in simplifying this process.
Portkey's Prompt Engineering Studio offers a practical solution for testing prompts in real-time. You can switch between models, adjust settings through a simple interface, and see immediate changes in outputs. The platform handles all versioning automatically.
With its centralized prompt library, built-in version control, and robust performance monitoring tools, Portkey makes prompt engineering seamless. Teams can benefit from collaborative features that encourage knowledge sharing, enabling them to develop best practices and refine their approaches over time.
By adopting the practices discussed in this blog and leveraging Portkey’s capabilities, developers can harness the full potential of LLMs, ensuring that their applications remain effective and relevant.
To get started on Portkey, sign up here

