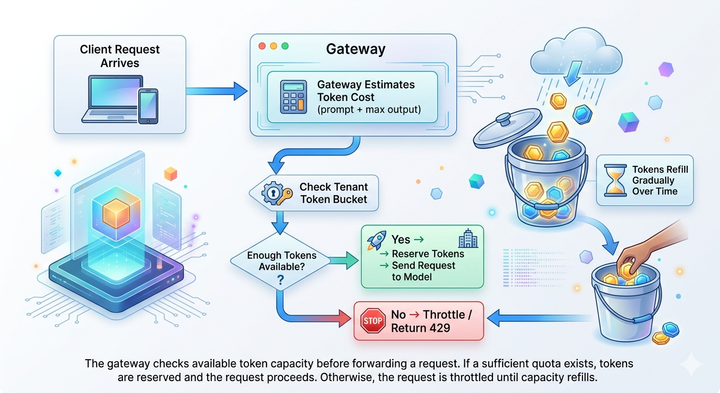
The most reliable AI gateway for production systems
Portkey’s AI Gateway delivers enterprise-grade reliability at scalw. Learn how configurable routing, governance, and observability makes Portkey the most reliable AI gateway for production.
The conversation around AI infrastructure has evolved. For teams building AI-powered products, the question is no longer “can we connect to a model?” , it’s “can we rely on it?”
As applications move from prototypes to production, reliability becomes the real differentiator. Latency, uptime, observability, and failover aren’t optional features. They define whether an AI system delivers consistent value or fails under scale.
An AI gateway sits at the center of this equation. It’s the layer that connects your AI apps to models, manages routing and governance, and ensures that requests perform predictably even when providers don’t.
What reliability means for an AI gateway
Reliability is about ensuring that every request from your AI application performs consistently, securely, and transparently, regardless of provider or workload. For an AI gateway, that means operating across five key dimensions:
1. Consistency
Every millisecond counts when you’re serving real-time AI experiences. Reliable gateways deliver predictable latency and maintain performance stability even as traffic scales to billions of requests.
2. Resilience
Provider outages, API errors, and network delays are inevitable. A reliable gateway absorbs this complexity, rerouting traffic intelligently, managing failover, and ensuring continuity without human intervention.
3. Control
Reliability extends beyond performance into governance. Unified authentication, access control, and policy enforcement prevent unauthorized usage and help teams stay compliant while scaling.
4. Visibility
You can’t fix what you can’t see. A reliable gateway offers full observability into every request, provider, and token spent, making debugging, cost management, and optimization effortless.
5. Security
Finally, reliability depends on trust. A secure gateway protects API keys, enforces encryption in transit and at rest, and integrates with enterprise identity systems to ensure compliance with standards like SOC 2, ISO 27001, GDPR, and HIPAA.
Together, these pillars define reliability not as a metric but as an architecture.
Built for scale: reliability at 10B+ requests/month
Reliability is earned at scale. Portkey’s AI Gateway now handles over 10 billion LLM requests every month, sustaining 99.9999 percent uptime with sub-10 millisecond latency across production workloads.
This consistency comes from architectural simplicity with deliberate fault-tolerance:
- Multi-provider routing distributes traffic across 1 ,600 + models and multiple providers, balancing load while keeping requests performant.
- Intelligent failover routing on provider errors, timeouts, or latency thresholds ensures continuity even when upstream APIs fail.
- Regional data planes keep data within defined jurisdictions, helping enterprises meet residency and compliance requirements without sacrificing speed.
- Built-in caching reduces redundant calls and stabilizes latency under load.
- Unified governance and monitoring give teams end-to-end visibility auth, usage, and spend, so issues are detected and resolved before they impact production.
Every layer of Portkey’s infrastructure is designed around one principle: predictable performance under unpredictable conditions. An AI application runing on a few thousand requests or scaling to millions per minute, the Gateway delivers consistent, observable reliability.
Reliability engineered through smart configs
Portkey’s routing layer is designed for real-world conditions, where model responses fluctuate, APIs rate-limit, and new models are continuously introduced into production.
Portkey’s AI Gateway has a multi-strategy routing system that ensures every request finds the most optimal, healthy, and performant path in real time:
- Fallbacks and retries: When a primary provider or model fails, Portkey automatically retries or redirects the request to a defined fallback target, maintaining continuity without manual intervention.
- Request timeouts: Every call has configurable timeouts, allowing teams to terminate slow responses gracefully and trigger alternate routes instantly.
- Conditional routing: Requests can be dynamically routed based on parameters, metadata, or contextual rules, such as user tier, region, model version, or even outcomes from guardrails. This gives teams precise, real-time control over how traffic flows across models and environments.
- Canary testing: New models or providers can be introduced gradually to a small percentage of traffic before full rollout. This allows teams to benchmark reliability and performance under production conditions without disrupting live systems.
- Unified batch inference: Portkey supports parallel, multi-provider batch inference, letting teams process high-volume workloads without affecting real-time requests.
- Circuit breaker system: At each routing stage, Portkey continuously evaluates the health of all targets. Unhealthy targets are marked as “open” and removed from selection; if all targets fail, the circuit breaker bypasses to reattempt routing, ensuring graceful degradation rather than complete failure.

Together, these capabilities form a self-healing routing layer, one that is adaptable, and sustains reliability even under unpredictable model or provider behavior. It’s how enterprises keep their AI systems available, fast, and verifiably dependable.
Governance and control at enterprise scale
A truly reliable AI gateway ensures that every request is authorized, auditable, and compliant with enterprise policies.
Portkey’s governance layer is built around that principle. It unifies authentication, permissions, usage policies, and compliance controls into one secure gateway, giving organizations the confidence to scale safely.
- Unified authentication: Manage and authenticate access to all providers through a single gateway. Portkey standardizes token and keys and error handling across APIs, removing the sprawl of credentials that typically accompany multi-model deployments.
- Role-based access control (RBAC): Define RBAC permissions at the workspace, model, or environment level ensuring only authorized users and services can trigger requests.
- Usage and cost limits: Configure per-user or per-team usage thresholds to manage quota, cost, and capacity, preventing runaway usage or budget overruns.
- Audit trails: Every request through the gateway is logged and traceable, providing full accountability and compliance visibility.
- Regional data residency: With dedicated regional data planes, enterprises can ensure data stays within the required geographic boundaries — a critical requirement for GDPR, HIPAA, and other compliance frameworks.
- Enterprise-grade certifications: Portkey’s infrastructure and processes align with SOC 2, ISO 27001, GDPR, and HIPAA, meeting the highest standards for data security and governance.
Observability and transparency
Reliability depends on visibility. Without clear insight into how requests behave, where failures occur, or how costs evolve, teams can’t maintain trust in their AI systems.
Portkey makes observability a first-class feature of the AI Gateway, giving engineering and operations teams the data they need to run AI in production with confidence.
Every request that flows through Portkey can be traced, analyzed, and acted upon in real time.
- Detailed request logs: Track every API call, response, latency metric, and provider used, enabling granular debugging and pattern detection.
- Cost and usage visibility: Portkey aggregates spend and usage data across providers, so teams can monitor consumption, attribute costs, and optimize budgets from a single dashboard.
- Transformed logs for debugging: Log data is automatically enriched with contextual metadata, model name, provider, status code making it easy to pinpoint and resolve issues fast.
- Integration-ready: Observability can be extended to existing monitoring stacks through OpenTelemetry or any tools.
Proven reliability in production

Portkey’s AI Gateway has been battle-tested across industries where uptime, governance, and observability aren’t optional. From large utilities and financial enterprises to leading universities and research networks, teams depend on Portkey to keep their AI systems running predictably at scale.
Today, Portkey processes over 10 billion LLM requests every month with 99.9999% uptime and < 40ms latency, serving workloads that span multiple clouds, providers, and geographies.
- A Fortune 500 energy company runs internal AI agents and copilots through Portkey to manage multi-cloud routing, caching, and governance, operating without a single minute of downtime since deployment.
- A major U.S. university network uses Portkey as its AI access layer, ensuring research teams can safely connect to different models while staying compliant with FERPA and GDPR requirements.
- A financial services firm adopted Portkey’s gateway for cost tracking and observability across providers, reducing API spend by over 25% while improving response predictability.
Across these deployments, one pattern stands out, reliability scales when it’s engineered, not assumed.
Portkey provides the backbone that lets teams experiment freely, deploy responsibly, and operate with confidence even as traffic, teams, and tools grow.
The foundation for dependable AI systems
As AI moves deeper into production, reliability becomes the real measure of maturity. Enterprises no longer need another API layer, they need a system they can trust: predictable in performance, transparent in operation, and governed by design.
That’s the role Portkey’s AI Gateway plays. It brings reliability out of the abstract and into the infrastructure layer where uptime, routing, governance, and observability work together as part of one system.
By giving teams control over every aspect of request handling — from failover logic to usage limits, Portkey helps organizations run AI workloads that stay resilient, compliant, and cost-efficient at any scale.
Reliability isn’t an add-on; it’s the architecture.
Portkey makes it measurable.
Learn more about how Portkey powers reliable AI in production.