
Evaluating Prompt Effectiveness: Key Metrics and Tools
Learn how to evaluate prompt effectiveness for AI models. Discover essential metrics and tools that help refine prompts, enhance accuracy, and improve user experience in your AI applications.`
Prompts act as the primary communication channel between the user and the model. Crafting effective and precise prompts is crucial for achieving accurate and relevant outputs and optimizing the model’s overall performance and resource usage.
Evaluating prompt effectiveness means assessing how well prompts are aligned with the desired outcome, how consistently they perform across different contexts, and whether they meet the accuracy and quality standards for production use. This evaluation is vital because ineffective prompts can lead to misinterpretations, inconsistent responses, and wasted computational resources, all of which add up over time.
In this blog, we’ll cover key metrics and essential tools for evaluating prompt effectiveness, helping teams systematically improve prompt quality and optimize the model’s output for their specific needs.
Key Metrics for Evaluating Prompt Effectiveness
Evaluating prompt effectiveness requires a clear set of criteria to judge how well a prompt performs and whether it meets the needs of both the model and the end user. These metrics provide insight into different aspects of prompt quality, from output accuracy to overall user satisfaction.
- Relevance measures how closely the model’s output aligns with the user’s original intent in the query. This is particularly important when dealing with complex or nuanced prompts where slight deviations can lead to misunderstood outputs. Relevance can be measured by comparing the output with a predefined desired outcome, often using similarity scores (e.g., cosine similarity for embeddings) or manual evaluations.
- Accuracy is the degree to which the output is factually correct or aligns with known information, especially critical in domains requiring precision, such as medical information, legal guidance, or technical support. Accuracy can be evaluated by comparing the output against trusted reference data or external knowledge bases. Metrics like BLEU, ROUGE, or F1 scores are commonly used for automated scoring.
- Consistency assesses whether the model provides reproducible and similar responses when the same prompt is input multiple times or across different instances. Consistency can be measured by running the same prompt multiple times and comparing results for similarity. A high degree of similarity indicates consistency, whereas large variations may suggest issues with the prompt or the model’s tuning.
- Efficiency evaluates the speed and resource usage of the model when generating outputs, which becomes increasingly important in real-time applications where latency and computational load are factors. Efficiency can be tracked using response time (latency) and by monitoring computational metrics like CPU/GPU usage and memory load during prompt processing.
- Readability & Coherence
Readability and coherence measure the clarity, logical flow, and overall intelligibility of the output. This is particularly relevant in applications where user interaction or content consumption is involved. Readability can be measured using readability formulas (like Flesch-Kincaid) or manually evaluating sentence structure, grammar, and flow. Coherence might require subjective evaluation, often by comparing the response with known coherent texts or gathering user feedback.
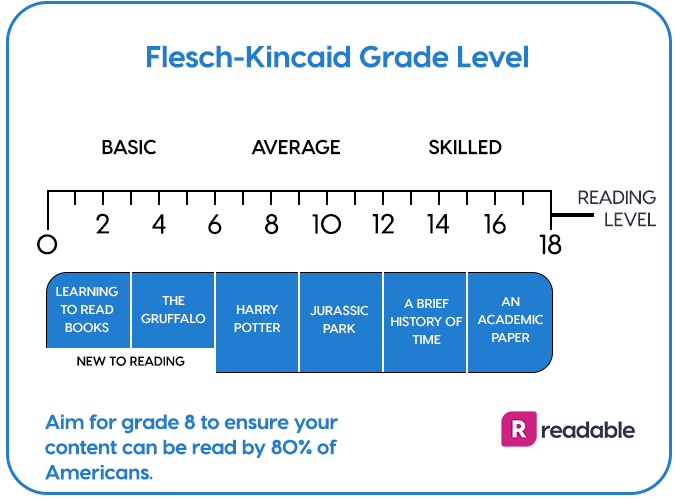
6. User Satisfaction Score
User Satisfaction Score reflects how satisfied users are with the output, usually gathered through feedback mechanisms like surveys or scoring systems embedded in the application. You can use tools like Portkey to get weighted feedback from customers on any request you serve, at any stage in your app.
Popular Tools for Measuring Prompt Effectiveness
LLM-Specific Tools
- OpenAI’s Embeddings for Semantic Similarity: OpenAI’s embedding models provide a way to analyze the similarity between prompts and responses at a deep, semantic level. This can be particularly useful in measuring relevance and consistency, as embedding vectors allow the comparison of different outputs or responses against a target result. Embeddings can help in applications where relevance is key, such as customer support or knowledge retrieval, by scoring responses against predefined correct answers to ensure outputs align closely with intended answers.
- Portkey's Prompt Engineering Studio: With Portkey's Prompt Engineering Studio, you can fine-tune your prompts in real time while seeing immediate output changes. Switch between models, adjust parameters through an intuitive interface, and let Playground handle all the versioning automatically.
You can compare different prompt versions side by side, track performance across various test cases, and identify which variations consistently produce the best outputs. Whether you're tweaking temperature settings, adjusting system prompts, or testing entirely new approaches, you'll see the impact instantly.
Every change is automatically versioned, making it easy to:
- Roll back to previous versions that worked better
- Compare performance across different iterations
- Deploy optimized versions to production
Teams using Playground have cut their prompt testing cycles by up to 75%, freeing up more time for core development work. - Debugging and Testing: Users can use tools like Portkey to monitor and log prompt interactions, track response trends, and flag inconsistencies to improve prompt effectiveness over time. Portkey's AI Gateway also provides analytics that help identify patterns and fine-tune prompts, making the debugging process more efficient.
Evaluation Libraries
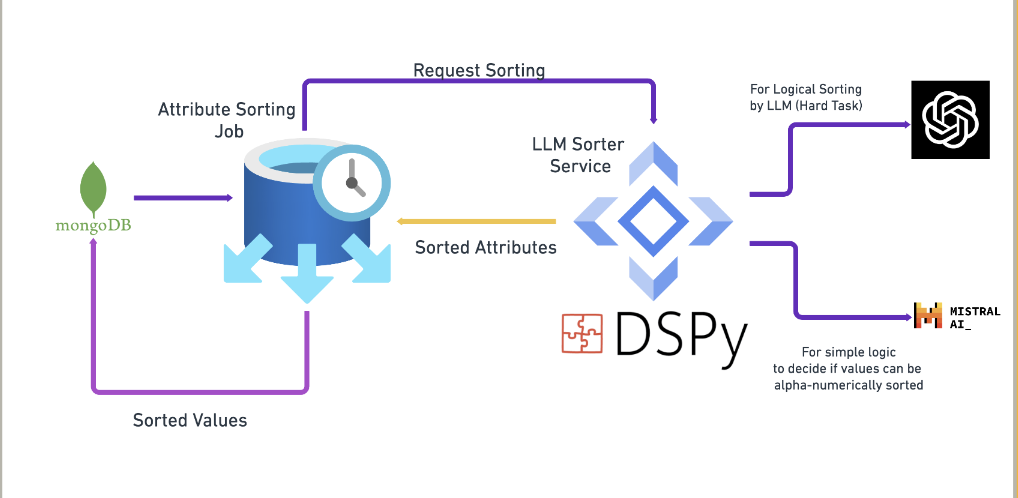
- DSPy: DSPy is a library designed for data-centric AI development, offering tools to evaluate and refine prompt outputs using metrics like accuracy, relevance, and coherence. DSPy automates these checks and helps tune prompts based on data quality rather than merely model parameters.
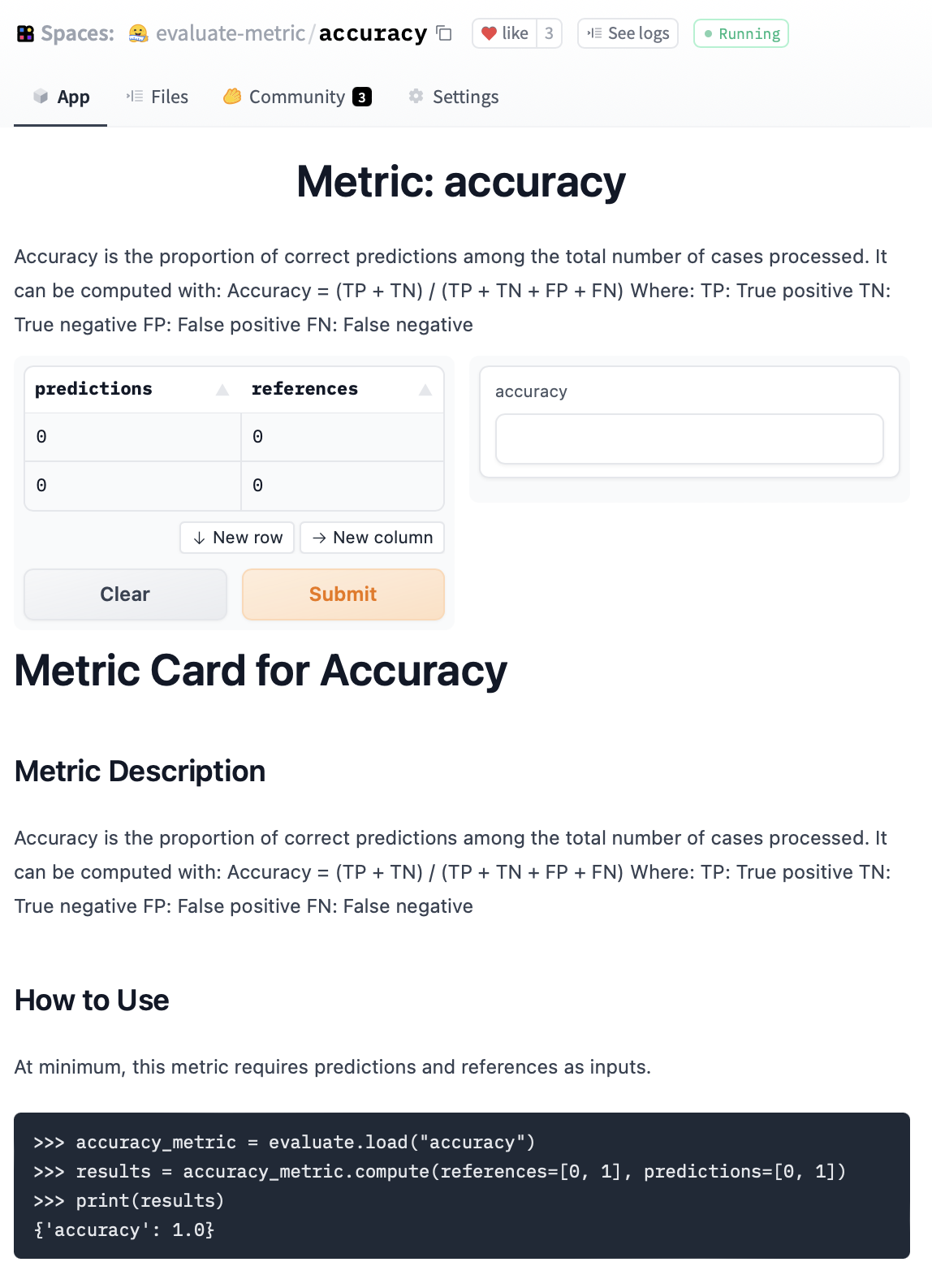
- Hugging Face's Evaluate Library: Hugging Face’s evaluate library provides a wide range of metrics for assessing NLP outputs, such as BLEU, ROUGE, and METEOR scores for relevance, readability, and coherence. It is flexible, allowing developers to implement multiple metrics in one place and quickly assess performance across different dimensions.
A/B Testing Platforms
Comparative Testing for Prompt Variations: A/B testing platforms provide a structured environment to compare different prompt versions, helping teams experiment with minor prompt adjustments to determine which versions yield the best responses. Portkey can help you set up an effective A/B test for prompts to measure the performance of different models in production.
Analytics Dashboards: Many AI platforms allow teams to track prompt data over time. These analytics offer insights into prompt frequency, response trends, and potential issues with prompt performance, helping identify prompts that may need refinement.
Real-World Example of a Prompt Evaluation Workflow
Let’s walk through a sample workflow where a team is tasked with refining prompts for a customer support chatbot. The chatbot needs to deliver accurate, relevant, and efficient responses to customer inquiries across various topics. By following a structured evaluation process, the team can systematically assess and improve prompt quality, ensuring the chatbot consistently meets performance standards.
1. Define the Initial Prompt and Objective
The team’s goal is to create a prompt that allows the chatbot to accurately answer questions about product returns. The prompt must produce clear, concise, and accurate responses that guide users effectively through the return process.
Initial Prompt: “Provide instructions on how a customer can initiate a return for a purchased product, including eligibility criteria, required documentation, and time frames.”
2. Set Target Metrics for Evaluation
Based on the prompt’s goal, the team identifies the key metrics to evaluate prompt effectiveness:
- Relevance: The output must stay focused on return instructions without introducing unrelated information.
- Accuracy: Responses should accurately represent company policies and procedures for returns.
- Consistency: The chatbot must give similar responses for identical or very similar prompts, reducing user confusion.
- Readability & Coherence: Instructions should be clear and logically ordered, with easy-to-follow steps.
- Efficiency: The response time should remain low, especially as customers may be waiting for live responses.
3. Use Tools to Generate Initial Evaluation Data
- Relevance Check with OpenAI’s Embeddings: The team uses OpenAI’s embedding model to calculate the similarity between the prompt response and a predefined ideal response. If the similarity score is low, it indicates the need to refine the prompt to make it more focused.
- Accuracy Validation with evaluate Library: Leveraging Hugging Face's evaluate library, the team measures the response’s accuracy against the company’s return policy information. They compare response content with a reference dataset that includes standard return policies, checking for factual correctness.
- Consistency Testing: Portkey helps monitor the prompt’s output consistency by logging multiple runs of the same prompt over time. If outputs show significant variation, the team will further refine the prompt to enhance reproducibility.
- Readability Assessment with DSPy: Using DSPy’s readability functions, the team assesses whether the response meets a specific readability threshold. This includes checking sentence length, grammar, and logical flow to ensure the response is user-friendly.
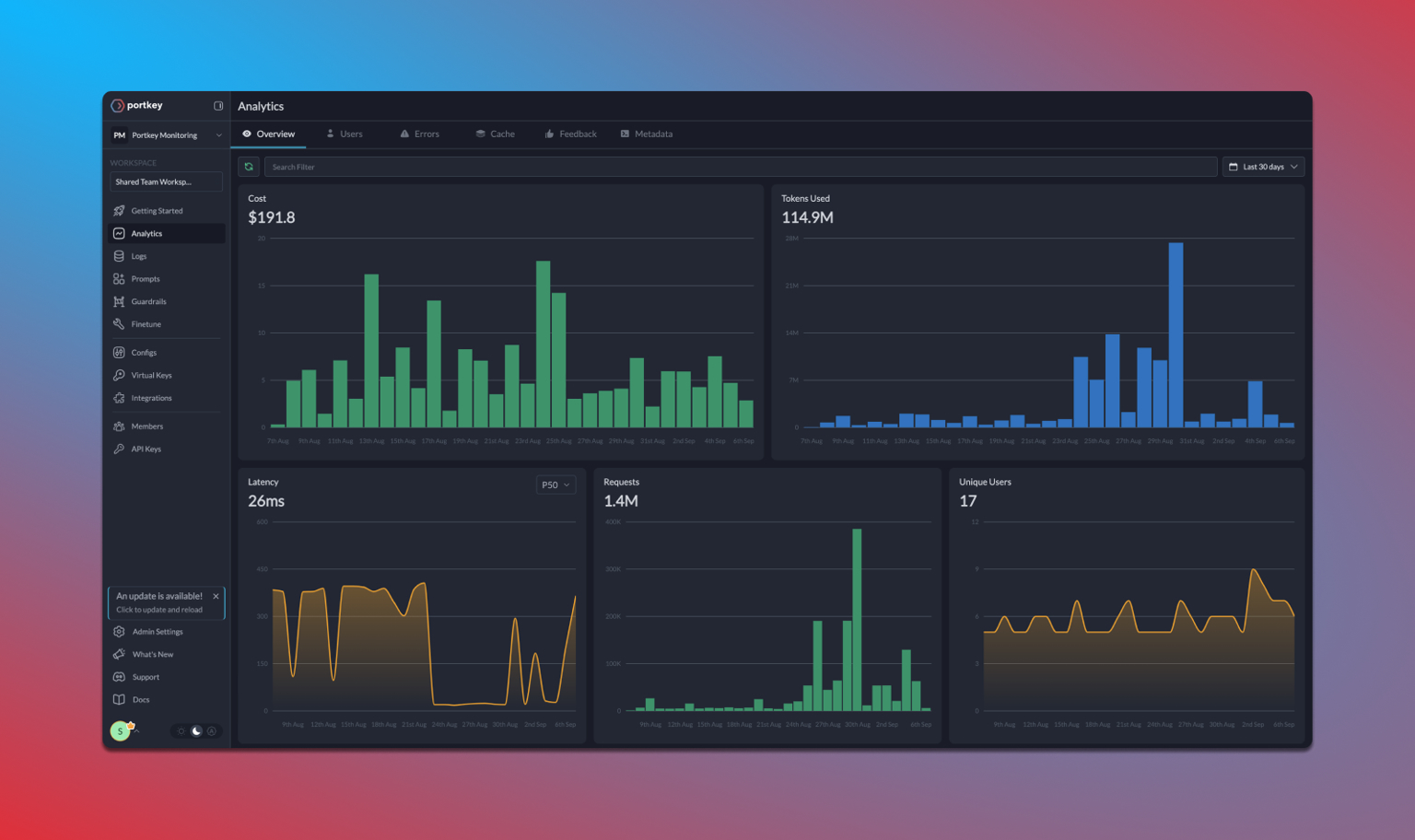
- Efficiency Testing via Analytics Dashboard: The team uses a dashboard to monitor response latency, ensuring that response times remain low. They set a threshold for acceptable response time, noting any delays that exceed this limit.
4. Analyze Results and Identify Areas for Improvement
The initial evaluation reveals areas for enhancement:
- Relevance: The embedding model indicates a low similarity score, suggesting the prompt sometimes includes irrelevant details about other services, such as exchanges.
- Accuracy: The evaluation library flags minor discrepancies between the response and the exact wording of the return policy, particularly in eligibility requirements.
- Consistency: Logs show occasional differences in responses, where the chatbot alternates between including and omitting certain return conditions.
- Readability: DSPy’s readability metrics highlight a high reading level, meaning that some customers might find it challenging to follow the instructions.
- Efficiency: Response time is within the threshold, but the team notes that minor optimizations could improve latency.
5. Refine the Prompt Based on Findings
The team refines the prompt to better align with the evaluation findings:
- Improving Relevance: The prompt is adjusted to include specific instructions: “Only provide instructions related to product returns (not exchanges), covering eligibility, documentation, and timelines.”
- Enhancing Accuracy: The prompt is updated to directly reference return conditions, reducing ambiguity: “State the eligibility criteria for product returns as per the policy, and outline required documentation.”
- Increasing Consistency: By tweaking the prompt to specify exact terms and conditions language, the team aims to reduce response variability.
- Boosting Readability: The team simplifies the language and adds explicit step-by-step instructions to ensure clarity.
- Improving Efficiency: Small optimizations in response handling are implemented, such as shorter sentences and reduced token usage, which can cut down response latency.
6. Re-evaluate and Iterate
Following prompt refinements, the team conducts a second evaluation to confirm improvements across each key metric.
7. Deploy and Monitor in Production
The team deploys it in production with a refined prompt that meets target metrics. An analytics dashboard tracks ongoing performance, checking for any drift or performance drops in relevance, accuracy, or consistency. Regular A/B testing is conducted with minor prompt variations to explore potential improvements and respond to user feedback.
Evaluating prompt effectiveness is a crucial, ongoing process that directly impacts the performance and reliability of AI applications. By carefully monitoring key metrics, teams can continuously refine their prompts to produce high-quality outputs that align with user expectations and operational goals. Whether you’re managing a chatbot, generating content, or handling complex queries, effective prompt evaluation ensures that your AI remains aligned with both technical standards and business objectives.
As prompt engineering keeps improving, investing in a robust evaluation framework will be essential for maintaining competitive, dependable, and user-centric AI solutions.

