
How to Optimize Token Efficiency When Prompting
Tokens are the building blocks of text that language models process, and they have a direct impact on both your costs and how quickly you get responses. Making your prompts token-efficient is more than cost-saving - it can lead to better results from the AI models you're working with.
Let's look at some practical ways to make your prompts more efficient without sacrificing quality.
Check this out!
Understanding tokens and their impact
Sometimes a token is a full word, but often it's just part of a word or even a single character. Each language model breaks text down differently based on its tokenization approach.
When you send a prompt to a model like Claude or GPT, you're essentially paying for each token it processes. More tokens mean higher costs and slower responses—something that matters a lot in production environments.
Getting your token usage right helps keep your applications responsive and your bills manageable without compromising on the quality of answers you receive.
Techniques for optimizing token efficiency
1. Concise Prompt Engineering
Concise prompting is the practice of crafting clear, succinct instructions to guide AI models effectively. By eliminating unnecessary words and focusing on essential information, concise prompts enhance the quality of AI-generated responses. This approach not only saves time but also ensures that the AI comprehends and addresses the user's intent accurately. For instance, instead of a verbose prompt like, "Could you possibly provide me with a detailed explanation of how to improve writing skills?", a concise alternative would be, "Explain how to improve writing skills." Adopting concise prompting techniques leads to more efficient and relevant interactions with AI systems.
2. Dynamic In-Context Learning
Dynamic In-Context Learning refers to an AI model's ability to adapt its responses based on real-time context provided within a prompt. Unlike traditional fine-tuning, where models require retraining on new data, dynamic in-context learning allows LLMs to adjust their behavior on the fly using just a few examples or guiding instructions within a single interaction.
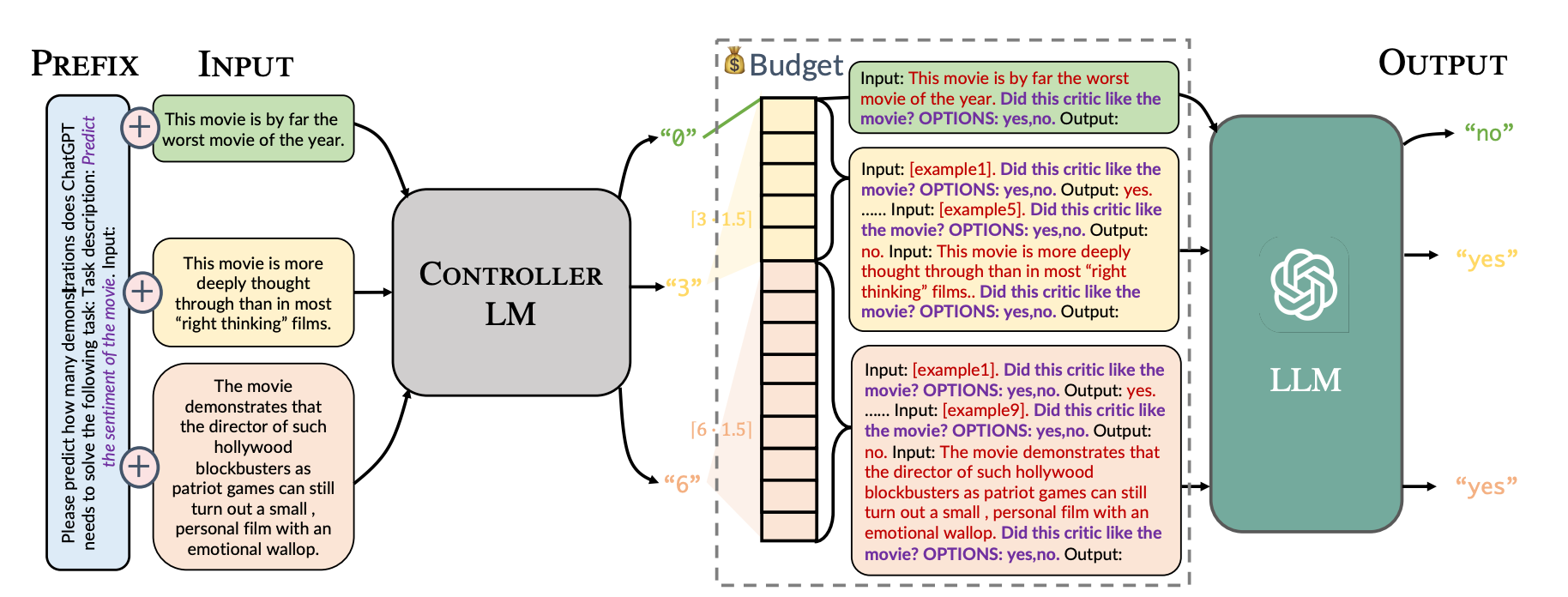
For example, if a user asks an AI to summarize news articles in a casual tone, the model can adapt based on the provided prompt:
Prompt: "Summarize this article in a light, conversational style: [Article Text]."
If the user later specifies a more formal style—"Now summarize in a professional tone."—the model dynamically shifts its response without needing additional training.
This prompt engineering technique is particularly useful in applications like customer support, AI-driven content creation, and personalized assistants, where flexibility and contextual adaptation are key.
3. BatchPrompt Technique
The BatchPrompt technique optimizes token usage and improves efficiency in large language models by processing multiple data points within a single prompt instead of handling them individually. Traditional single-data prompting (SinglePrompt) includes task instructions, examples, and one inference request, leading to inefficient token utilization when data inputs are small.
To solve this, BatchPrompt introduces batching multiple data points per prompt. However, naive batching can degrade accuracy due to positional biases in LLM outputs. To counter this, the paper proposes:
- Batch Permutation and Ensembling (BPE) – Multiple permutations of the batched data are processed, and predictions are aggregated via majority voting to improve reliability.
- Self-reflection-guided Early Stopping (SEAS) – If the LLM provides consecutive "confident" responses for certain data points, voting stops early to reduce token usage.
This prompt engineering method demonstrates a scalable way to reduce cost and performance efficiency for LLM applications.
4. Skeleton-of-Thought Prompting
Skeleton-of-thought (SoT) Prompting is a technique designed to reduce the inference latency of large language models (LLMs) by enabling parallelized text generation instead of the standard sequential token-by-token approach.
The LLM is first prompted to generate a structured outline (skeleton) of the response. Each part of the skeleton is then expanded in parallel using batched decoding (for open-source models) or parallel API calls (for closed models). The expanded sections are then merged to form the final answer.
This prompt engineering method achieves up to 2.39x faster generation compared to traditional sequential decoding.
Practical Tips for Implementing Token-Efficient Prompts
- Use Clear and Specific Instructions: Ambiguity can lead to verbose responses. Ensure that prompts are direct and unambiguous to guide the model effectively.
- Limit the Number of Examples: Provide only essential examples to illustrate the task. Overloading the prompt with examples can increase the token count without significant benefits.
- Utilize Output Formatting: Guide the model's response structure to avoid unnecessary elaboration. For instance, requesting bullet points or specific formats can help control the length of the output.
Testing Token Efficiency with Portkey's Prompt Engineering Studio
Portkey's Prompt Engineering Studio offers a comprehensive platform to test and optimize prompts for token efficiency. Users can experiment with different prompt structures, measure token usage, and assess response times across various AI models. The studio provides real-time analytics, enabling prompt engineers to refine their prompts iteratively for optimal performance.
Next Steps
Token efficiency matters when working with language models. It affects both your costs and how well your AI applications perform. The techniques we've discussed—keeping prompts concise, using dynamic in-context learning, batching similar requests, and applying skeleton-of-thought prompting—can make a real difference in your day-to-day work with these models.
Tools like Portkey's Prompt Engineering Studio can help you test and refine your approaches. By making token efficiency a priority in your prompt design, you'll not only save money but also build faster, more reliable AI systems. Start small by reviewing your current prompts and looking for opportunities to trim unnecessary text—you might be surprised by how much you can improve with just a few adjustments.

