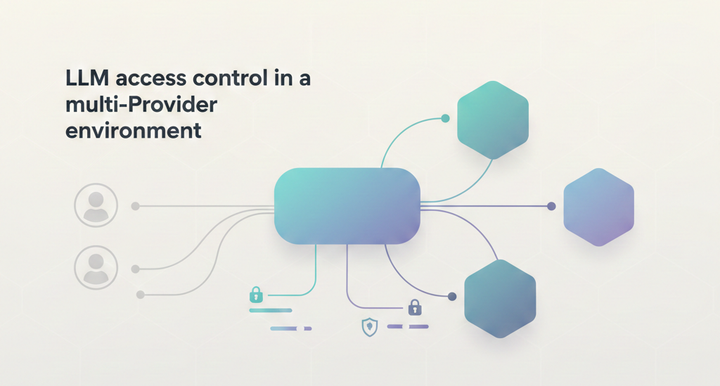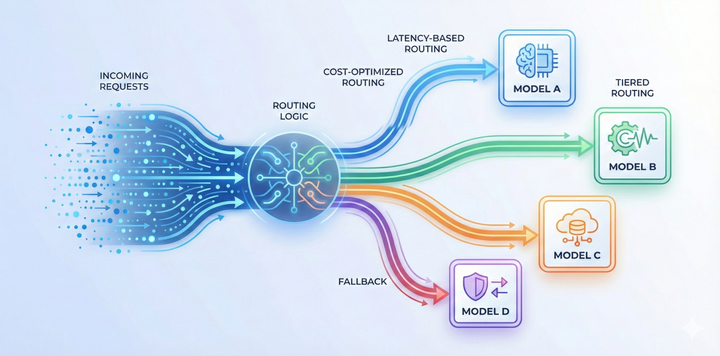
LLM routing techniques for high-volume applications
High-volume AI systems can’t rely on a single model or provider. This guide breaks down the most effective LLM routing techniques and explains how they improve latency, reliability, and cost at scale.