Prompt engineering for low-resource languages
Dive into innovative prompt engineering strategies for multilingual NLP to improve language tasks across low-resource languages, making AI more accessible worldwide
While Large Language Models have become remarkably good at understanding human language, they still stumble when it comes to many of the world's languages. This isn't just a technical hiccup - it affects real people. When AI systems struggle with these languages, it means millions of speakers can't access the same quality of machine translation, sentiment analysis, or AI chatbots that English speakers take for granted.
That's where prompt engineering comes in. By carefully crafting our prompts, we can help bridge this gap. But here's the catch: how do you write effective prompts for languages where the AI has limited training data to begin with? Teams around the world have been tackling this challenge, coming up with creative solutions that are showing real promise.
Let's dig into what makes this problem tricky, what solutions are emerging, and how they're making a difference in actual projects.
Challenges in Prompt Engineering for Low-Resource Languages
Limited Training Data - While models have seen billions of English, Chinese, and Spanish examples, they might have only encountered a tiny fraction of content in languages like Amharic or Malayalam. This data scarcity makes it tough for the model to understand the context and generate meaningful responses
Tokenization and Morphological Complexity - Languages like Tamil or Bengali aren't just different in their vocabulary - they follow completely different rules. These languages pack complex information into single words and use writing systems that don't play nice with standard tokenization. Imagine trying to break down a word that contains what would be an entire English sentence - that's what models deal with in many low-resource languages.
Code-Mixing - Many users mix languages in informal settings (e.g., Hinglish, Tamlish). This natural code-mixing (like Hinglish - a mix of Hindi and English) throws another wrench in the works. LLMs often lose track of which language rules to apply.
Bias and Hallucination Risks - With limited exposure to these languages' cultural context and linguistic patterns, models can produce responses that range from mildly inaccurate to completely nonsensical. They might miss cultural references or apply patterns from dominant languages inappropriately.
Advanced Prompt Engineering Strategies for Low-Resource Languages

1. Chain-of-Translation Prompting (CoTR)
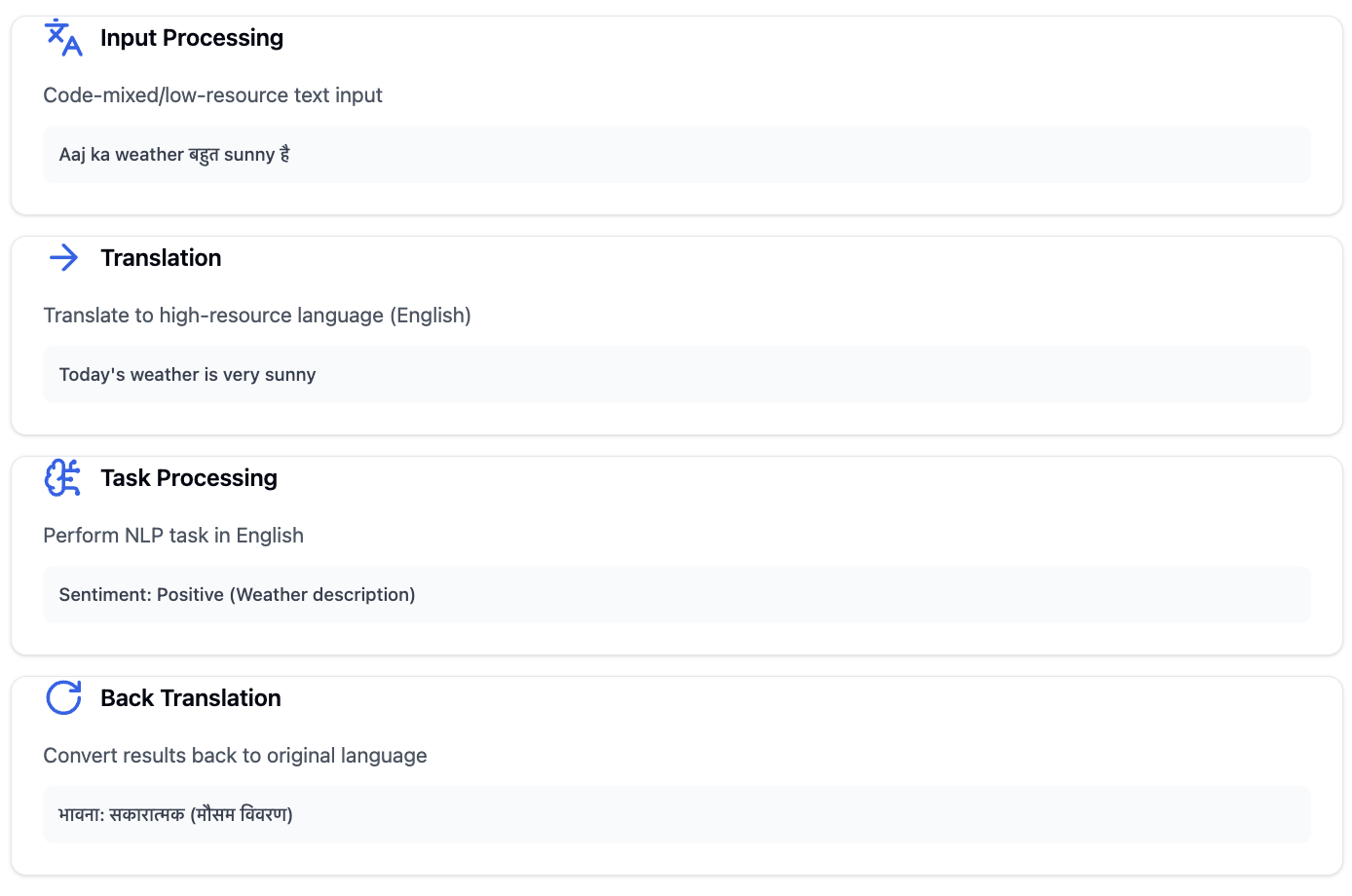
Chain-of-Translation Prompting (CoTR) has emerged as a novel strategy to enhance language model performance for low-resource languages. As described by Deshpande et al. (2024), this technique restructures prompts to bridge the gap between low-resource and high-resource languages through a systematic translation approach. Instead of directly processing text in languages with limited training data, CoTR first translates the input into English, performs the desired task, and then translates the results back if needed.
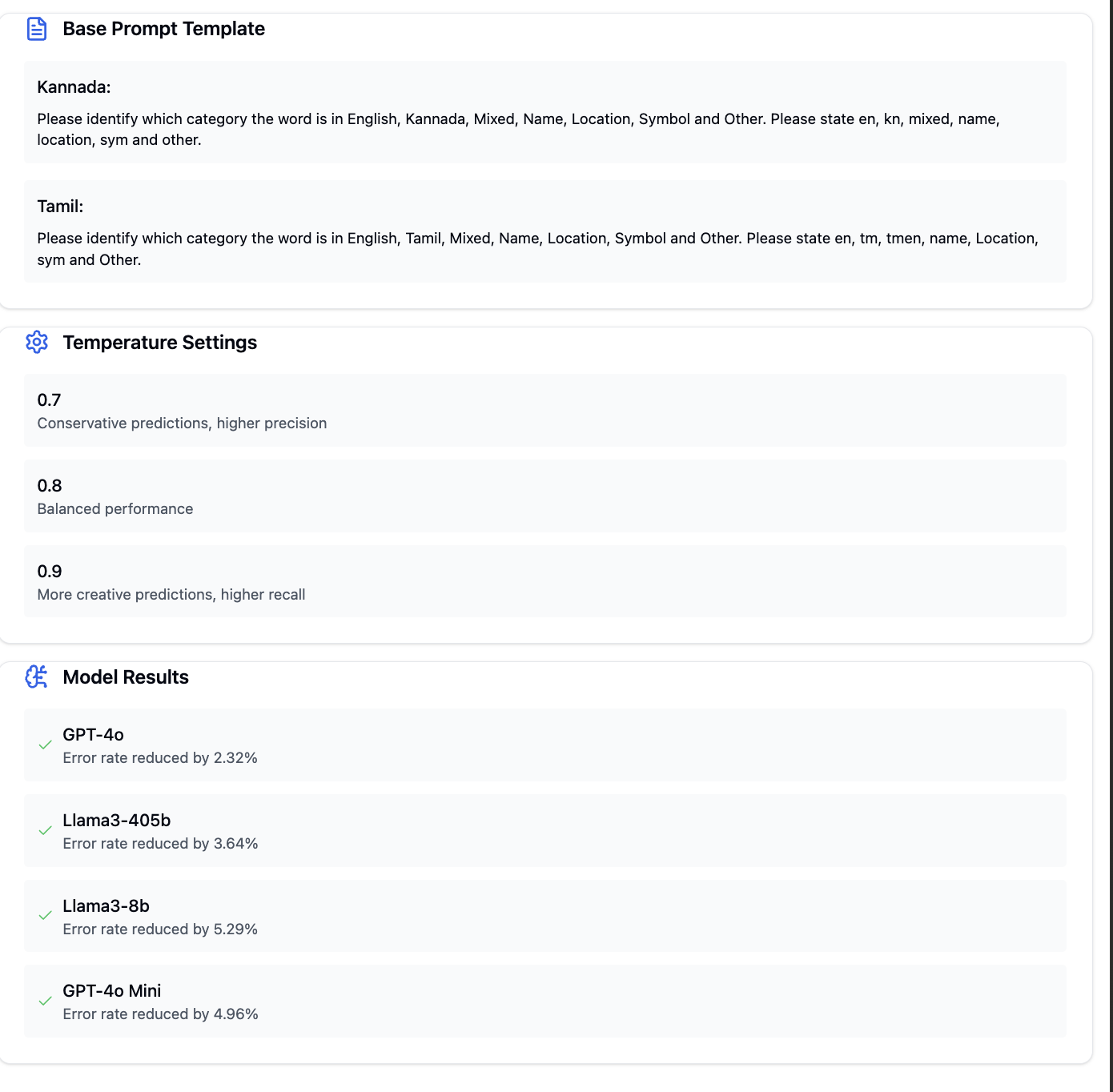
The effectiveness of this approach is particularly notable in complex tasks. Research by Deshpande et al. demonstrates significant error rate reductions ranging from 2.32% to 5.29% across different models, with the most substantial improvements seen in hate speech detection and sentiment analysis. For example, when processing Marathi-English code-mixed text, GPT-4 showed a 2.32% improvement in accuracy using CoTR compared to direct processing.
Looking toward practical applications, the technique has shown promise in various real-world scenarios, from news categorization to headline generation.
2. Code-Mixed Prompting
Code-mixing presents one of the most fascinating challenges in modern natural language processing, particularly in regions with rich linguistic diversity. According to research by Deroy and Maity (2024), this phenomenon is especially prevalent in Dravidian languages, where speakers naturally blend local languages with English at various linguistic levels.
The complexity of code-mixing manifests in several ways. First, there's the script variation challenge—many users write Dravidian language content using Roman script (Romanization) instead of their native scripts, leading to multiple valid representations of the same word.
Word-level language identification becomes particularly challenging in code-mixed text. A single sentence might contain words from multiple languages, each following different grammatical rules. The difficulty increases when words themselves are hybrid formations—combining roots from one language with suffixes from another.
This is a novel prompt engineering approach specifically designed for word-level language identification in code-mixed languages. Here's how the solution works:
- Prompt Structure: Develop carefully structured prompts for different languages:
For example, for Kannada, "Please identify which category the word is in English: Kannada, Mixed, Name, Location, Symbol, or Other. Please state en, kn, mixed, name, location, sym and other."
2. Temperature Optimization: Experiment with different temperature values (0.7, 0.8, and 0.9) to find the optimal setting for language identification accuracy. This tuning is crucial because:
- Lower temperatures (0.7) produce more conservative predictions
- Mid-range temperatures (0.8) provide a balanced performance
- Higher temperatures (0.9) allow for more creative predictions
3. Few-Shot and Zero-Shot Learning
By providing structured examples in prompts, we can help LLMs generalize better even when there is little to no training data for a specific language. Few-shot learning, where the model is given a few labeled examples before generating its own output, has proven effective in multilingual NLP tasks.
4. Explicit Instruction-Based Prompts
LLMs perform better when given step-by-step instructions rather than vague prompts. For instance:
"Step 1: Translate the sentence into English. Step 2: Classify the sentiment. Step 3: Translate the output back to the original language."
Looking forward
The research into prompt engineering for low-resource languages marks a significant step in making NLP technologies more accessible. These advances matter because they directly impact millions of speakers of low-resource languages.
Looking ahead, the path is clear but challenging. We need to:
- Build stronger bridges between academic research and practical applications
- Create more comprehensive datasets that reflect real-world language use
- Develop fine-tuning strategies that work with limited resources
- Support community-driven efforts to collect and validate language data
The next phase of development will likely focus on hybrid approaches that combine different prompting strategies. By mixing Chain-of-Thought reasoning with translation-based methods, we can create more sophisticated systems that better understand context and meaning across languages.
The goal isn't just to improve technology – it's to ensure that speakers of all languages can participate fully in the digital age. Through continued collaboration between researchers, developers, and language communities, we're moving closer to truly inclusive AI systems.