
Prompt Security and Guardrails: How to Ensure Safe Outputs
Prompt security is an emerging and essential field within AI development making sure that AI-generated responses are safe, accurate, and aligned with the intended purpose.
When prompts are not secured, the resulting outputs can unintentionally generate or amplify misinformation. Compliance risks are also a major concern. Enterprises deploying AI systems must adhere to regulatory standards, including data privacy laws and content moderation guidelines. Without robust prompt security, an AI could generate outputs that violate these regulations, potentially exposing the organization to compliance penalties.
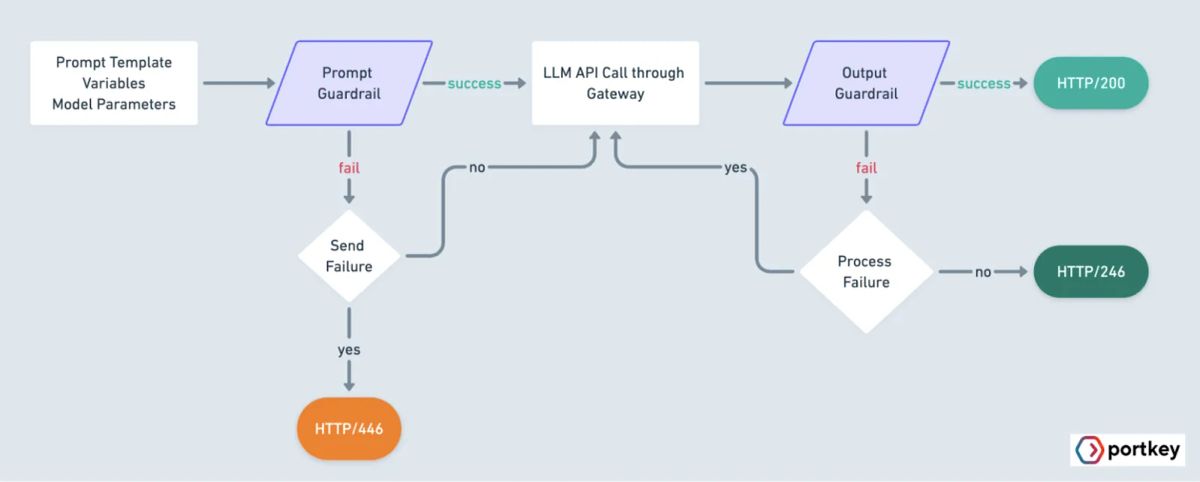
To address these concerns, guardrails play a pivotal role in securing prompt-based outputs. Together, prompt security and guardrails form a proactive approach to managing risks and ensuring that AI-generated outputs are trustworthy, ethical, and safe.
Understanding Prompt Security
Prompt security refers to the set of practices, technologies, and policies that protect AI models from producing harmful, biased, or inaccurate outputs.
Prompt engineering helps minimize these risks by crafting inputs that guide the model’s behavior. For instance, rather than using open-ended prompts, structured prompts can encourage more controlled responses. However, prompt engineering alone may not fully secure outputs in high-stakes applications, which is why guardrails are necessary.
The primary goals of prompt security include:
Safety: Ensuring that AI outputs do not pose harm, misinform, or violate ethical and legal standards.
Reliability: Consistent, accurate responses that are in line with the intended purpose of the AI application.
Ethics: Preventing AI from generating offensive, biased, or otherwise inappropriate responses that could damage the organization’s reputation or harm individuals.
Risks Associated with Unguarded Prompts
Without prompt security measures, AI models are vulnerable to producing outputs that could lead to serious consequences for users, organizations, and society at large. Here are some common risks associated with unguarded prompts:
Bias: AI models trained on vast datasets can inadvertently reflect and amplify biases present in the data. Unguarded prompts can lead to biased outputs, reinforcing harmful stereotypes or providing unequal treatment based on gender, race, or other demographic factors.
Misuse: Users may intentionally or unintentionally exploit prompt systems to generate content that AI models are not designed to produce. This misuse can result in inappropriate responses, such as promoting harmful advice, creating toxic or offensive content, or making unsubstantiated claims.
Privacy Violations: If prompts are not properly secured, there is a risk of the AI sharing sensitive or personal information, whether through unintended data leakage or responses that expose confidential details.
Core Components of Prompt Security and Guardrails
Below are the core elements of prompt security and how they function as guardrails for safer, more reliable AI interactions.
- Input Validation
Input validation is the first line of defense in prompt security, ensuring that user inputs meet established security, ethical, and contextual standards before they reach the AI model. This process involves examining prompts to identify potentially harmful or ambiguous input before it can produce a response.
Input validation can be achieved through rule-based filters, regular expressions for flagging certain keywords, or more sophisticated natural language processing models that assess prompt content for appropriateness.
In a customer service chatbot, input validation could filter out prompts asking for unauthorized personal data, ensuring that responses don’t reveal or request sensitive information. - Content Filtering
Content filtering applies security measures to the output stage, ensuring that generated responses do not contain inappropriate, offensive, or biased information.
Content filtering often uses combinations of keyword filtering, sentiment analysis, and more advanced AI models that can interpret the tone, context, and implications of responses before allowing them through.
In social media moderation tools, content filtering could help prevent AI from generating or amplifying harmful or extremist content. If a prompt leads the AI toward a potentially harmful response, content filtering can adjust or block that response.
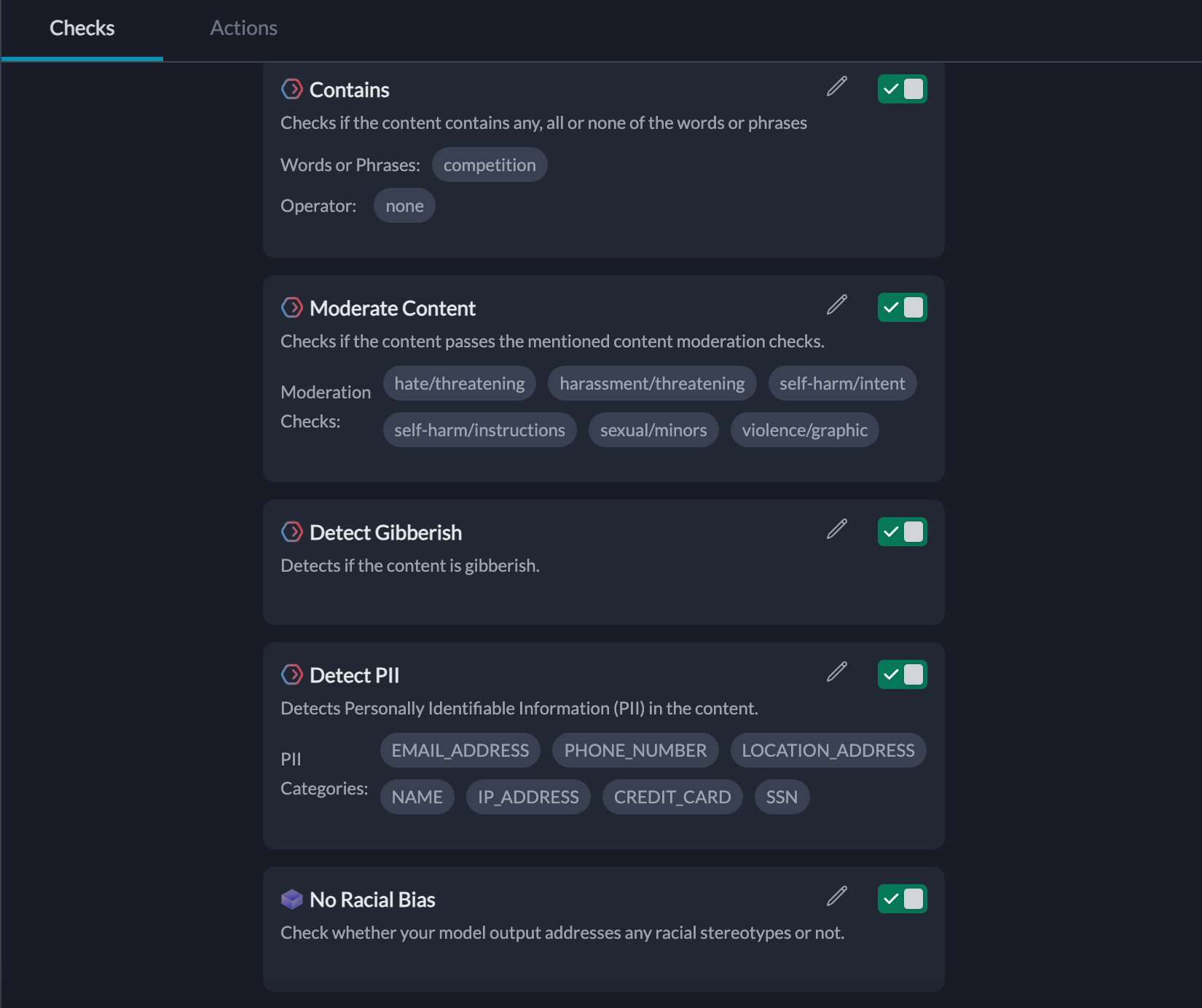
3. Response Consistency
Response consistency aims to ensure that the AI’s replies remain within the defined scope and offer predictable, dependable information. Consistency is crucial when dealing with sensitive subjects, as it minimizes the risk of the AI delivering conflicting or unreliable answers.
4. Red-Teaming and Testing
Red-teaming is a security approach where teams intentionally test the AI by submitting challenging or potentially harmful prompts to evaluate how well the model’s guardrails hold up. This approach helps uncover gaps in prompt security by pushing the AI’s boundaries in a controlled environment.
Each component offers unique protective functions, but together they create a layered security strategy that significantly enhances prompt security.
Best Practices for Implementing Prompt Guardrails
Achieving effective prompt security requires a strategic blend of prompt engineering and guardrails. While prompt management—carefully designing and structuring prompts—helps set boundaries for responses, adding guardrails is essential to catch any outputs that fall outside of safe parameters. Here are some best practices to consider:
- Use of Contextual Safeguards:
Contextual safeguards tailor guardrails based on the specific application, use case, and intended audience of the AI. This approach ensures that the security measures are sensitive to the nuances of different contexts and can prevent inappropriate or harmful outputs effectively. - Role of Human Oversight:
Human oversight is crucial for maintaining prompt security, especially for sensitive or high-stakes AI applications. Human reviewers can monitor the AI’s responses, flagging any issues that automatic systems might miss, such as subtle biases or inappropriate undertones in responses. This feedback loop between human reviewers and the AI helps improve prompt guardrails over time, making the model more robust and adaptive. - Audit Trails and Transparency:
By keeping an audit trail of inputs, outputs, and any modifications made to AI responses, organizations can evaluate their prompt security effectiveness, diagnose potential issues, and provide accountability. Transparent systems also allow organizations to investigate incidents retrospectively, improving guardrails based on real-world data. - Regular Updates and Fine-Tuning:
As AI applications encounter new types of prompts and adapt to different scenarios, developers need to continuously fine-tune models and prompt guardrails to keep outputs secure. Regular updates help address emerging security gaps, adapt to shifting regulatory requirements, and ensure that the AI’s responses remain relevant and accurate.
Technological Tools for Prompt Security and Guardrails
Below is an overview of some prominent tools that enable prompt security, how they integrate with existing LLM frameworks, and the critical features to look for in these tools.
- OpenAI's Moderation API: OpenAI’s Moderation API is designed to detect and filter harmful content in real-time by evaluating the likelihood that generated content might be offensive, biased, or otherwise unsafe. The Moderation API scores output on metrics such as violence, hate speech, and adult content, allowing developers to block or modify responses based on these scores.
- Portkey’s AI Guardrails: Portkey offers prompt security features designed specifically for enterprises, including customizable guardrails that control outputs based on ethical, regulatory, and organizational standards. Portkey’s AI guardrails can be configured for different applications, giving organizations control over how prompts are interpreted and ensuring outputs are consistent with brand and compliance guidelines.
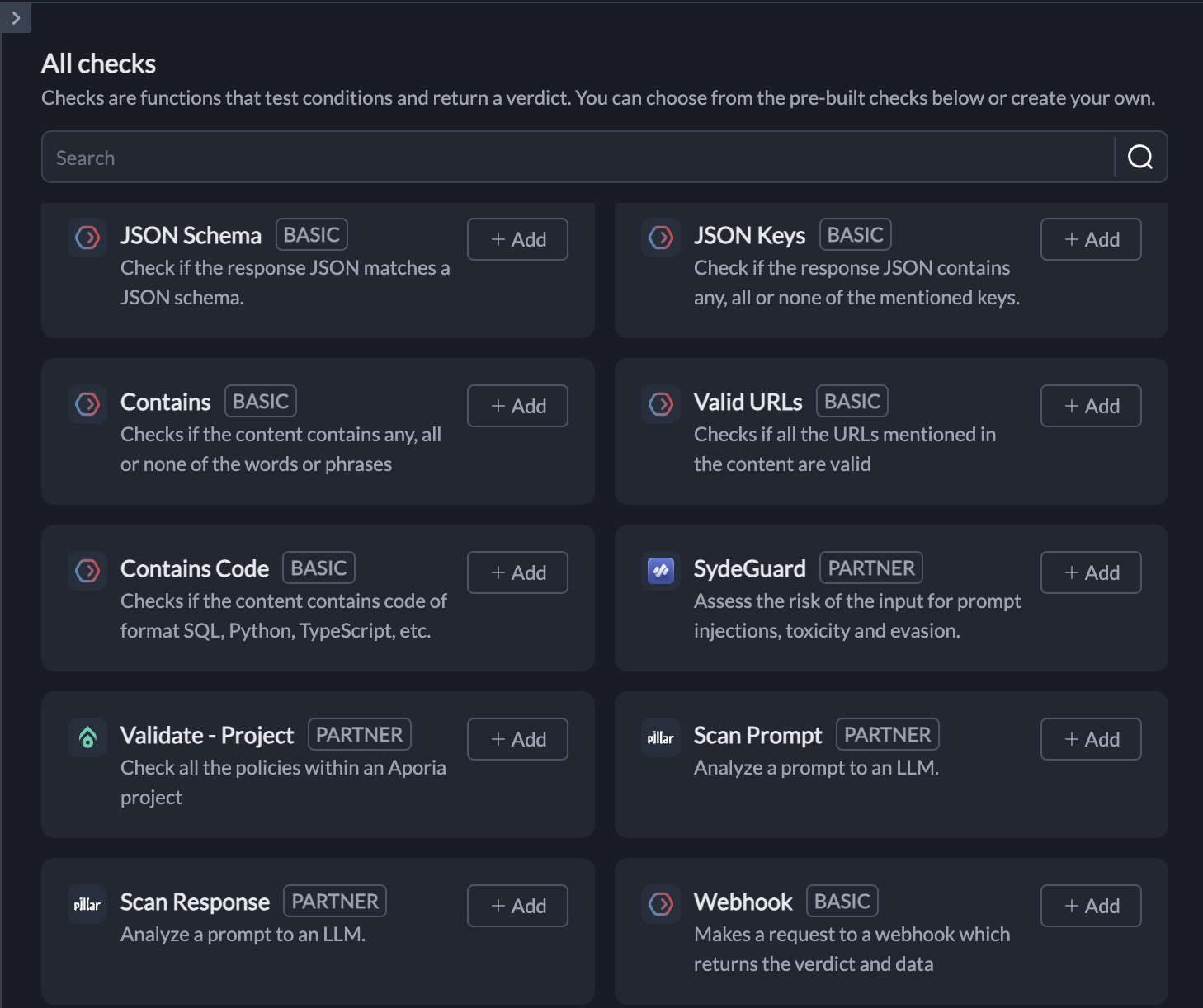
3. Patronus: Patronus is a real-time AI monitoring platform for tracking model behavior, spotting biases, and managing security risks with detailed alerts and metrics. Through its integration with Portkey, teams can apply Patronus’s advanced evaluators directly within the AI Gateway to enforce real-time LLM behavior and secure production-level AI.
4. Pillar: Pillar offers prompt and content moderation for LLMs with customizable guardrails that block or adjust risky outputs, which is ideal for high-stakes applications. Integrated with Portkey, Pillar’s low-latency, model-agnostic security layer enables enterprise-grade security in GenAI applications, protecting against current and emerging AI threats.
5. Aporia: Aporia provides ML observability for monitoring outputs, detecting drift, and flagging risky responses in real time. When integrated with Portkey’s LLM Gateway, Aporia’s high-accuracy guardrails offer seamless, low-latency security for GenAI applications within Portkey’s AI framework.
As AI applications become more sophisticated and widely used, prompt security and effective guardrails are essential to protecting users, maintaining trust, and upholding brand integrity.
With Portkey, you gain access to comprehensive tools and integrations that provide top-tier prompt security, observability, and content moderation, all tailored to meet the needs of enterprise-level AI applications. Ready to build safer, smarter, and more secure AI? Try Portkey today.

