

Accelerating LLMs with Skeleton-of-Thought Prompting
A comprehensive guide to Skeleton-of-Thought (SoT), an innovative approach that accelerates LLM generation by up to 2.39× without model modifications. Learn how this parallel processing technique improves both speed and response quality through better content structuring.
Large Language Models bring powerful capabilities to AI applications, but they come with a notable drawback: slow inference speeds. When generating responses token by token in sequence, these models create noticeable delays that get in the way of smooth real-time interactions and make scaling difficult.
Skeleton-of-thought prompting tackles this problem with a fresh approach. By structuring responses in a way that allows for parallel processing, this method cuts down on wait times while keeping answer quality high—and sometimes even making it better.
What is Skeleton-of-Thought prompting?
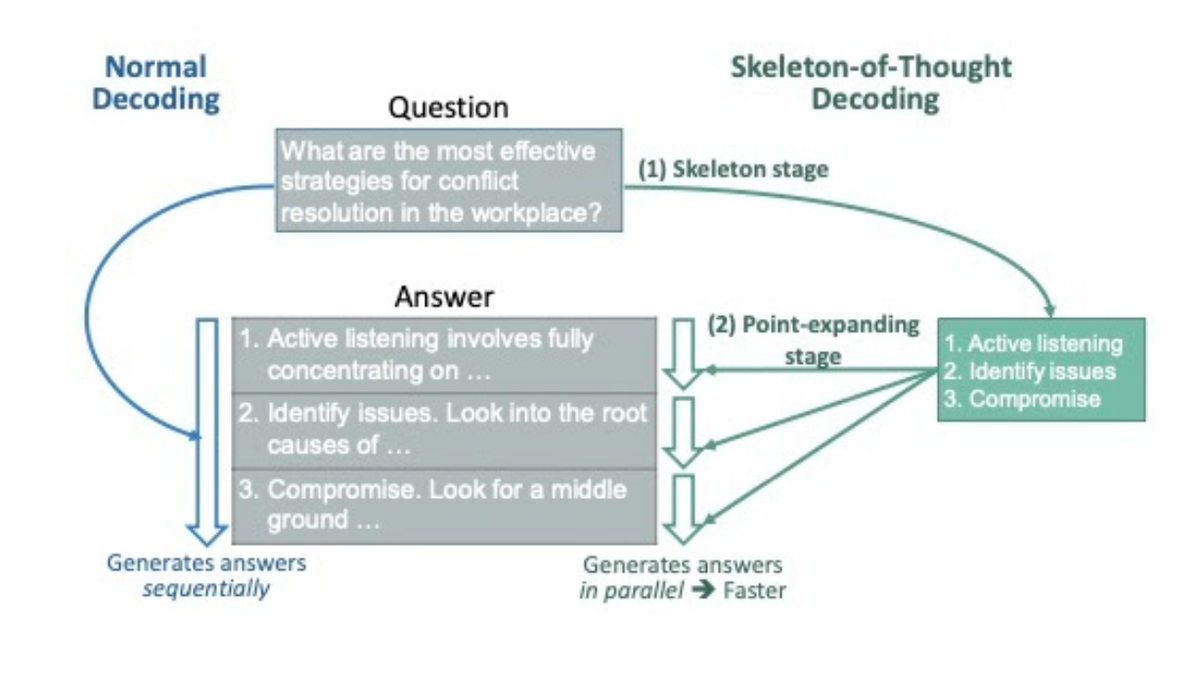
Skeleton-of-Thought is a smart prompt engineering technique that speeds up how LLMs generate responses. Instead of building content one token after another, it first creates a structured outline—the "skeleton"—and then fills in multiple sections at the same time.
This approach mirrors how many of us write: we sketch out the main points first, then develop each section. The beauty of SoT is that it works with existing models without any modifications to their architecture. You simply change how you prompt the model to get faster results.
How Skeleton-of-Thought prompting works
SoT prompting breaks down the generation process into three streamlined steps:
Skeleton Creation: The LLM first generates a concise outline of 3-10 bullet points that address the query. This skeleton maps out the structure of the complete response.
Parallel Point Expansion: Each point in the skeleton gets developed independently through parallel API calls (for cloud-based models) or batch processing (for local models). This is where the time savings happen - instead of generating content sequentially, multiple sections are developed simultaneously.
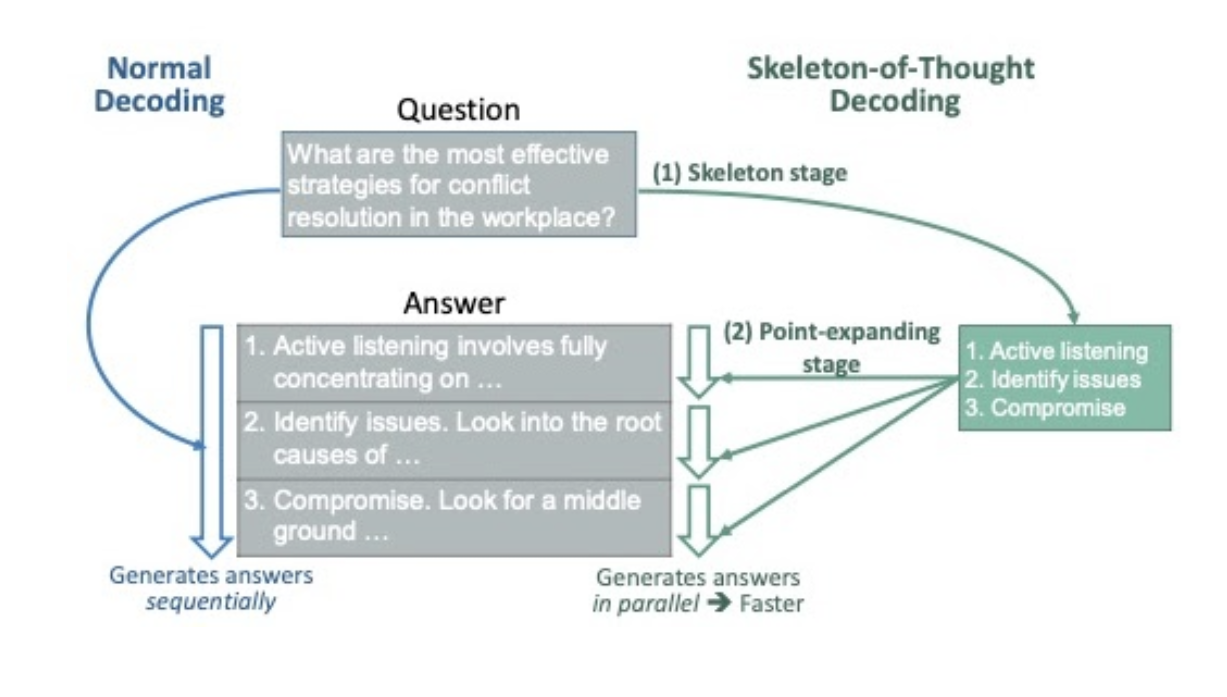
Response Assembly: The expanded points are combined into a single coherent answer. The result is a well-structured response that was generated in a fraction of the time compared to traditional sequential generation.
This approach is powerful because it mimics how humans tackle complex questions - we often think about the main points first, then fill in the details for each section. This not only speeds up generation but can sometimes improve response quality by encouraging more structured thinking.
Benefits of SoT
SoT prompting offers compelling advantages for teams working with large language models.
Speed improvements
Testing across multiple LLMs shows impressive results, with latency reductions of up to 2.39× compared to standard generation. These speed gains were consistent across various models including GPT-4, Claude, and the Vicuna family of models.
More structured responses
By design, SoT produces well-organized answers with clear sections. This improved structure makes responses easier to read and understand, especially for complex topics that benefit from being broken down into distinct components.
The skeleton generation step forces the model to plan its response before elaborating, resulting in more comprehensive coverage of relevant aspects of a question.
Enhanced response quality
Interestingly, SoT doesn't just make generation faster - it can also improve the quality of responses. Evaluations show that for knowledge-based questions, open-ended queries, and common-sense reasoning, SoT-generated answers were often rated higher than those from standard generation methods.
The improvement is particularly noticeable in diversity and relevance metrics. By explicitly planning multiple aspects of an answer during the skeleton stage, SoT helps ensure the model addresses different perspectives rather than focusing on a single angle.
These benefits make Skeleton-of-Thought particularly valuable for applications where response time matters but where you can't compromise on answer quality or structure.
Limitations and edge cases
While Skeleton-of-Thought offers impressive benefits, it's not a one-size-fits-all solution:
Not suitable for step-by-step reasoning: SoT shows limitations when handling problems that require strict sequential reasoning. Mathematical calculations, coding challenges, and logic puzzles often need each step to build directly on previous ones. In these cases, the parallel nature of SoT can lead to errors since each section doesn't have access to information developed in other sections.
Increased token usage: For teams using API-based models with per-token pricing, SoT might increase costs. The multiple parallel calls required for point expansion may use more tokens overall than a single sequential generation, even though the result comes faster.
Model dependence: The effectiveness of SoT varies significantly between models. Some LLMs interpret the skeleton and expansion prompts better than others. Less capable models might create poor skeletons or generate expansions that don't properly address the points, reducing the quality advantage.
These limitations highlight that SoT works best as part of a broader toolkit rather than as a universal approach to LLM optimization.
Skeleton-of-Thought prompting vs other acceleration methods
SoT prompting represents a fundamentally different approach to speeding up LLM responses compared to existing methods in the field. While most acceleration techniques focus on model architecture or computation, SoT tackles the problem from a content organization perspective.
Speculative decoding methods like those used in systems from Anthropic and Google use smaller, faster models to predict multiple tokens that the larger model then verifies in parallel. This approach still operates at the token level and maintains the sequential nature of text generation. SoT, in contrast, works at a higher level by reorganizing how content is structured and generated, allowing entire sections to be created simultaneously.
Traditional model compression techniques such as quantization, pruning, and distillation focus on reducing model size or computational requirements. These approaches often require retraining or fine-tuning and may compromise model capabilities. SoT takes a different route by keeping the model unchanged while optimizing how it generates responses through smarter prompting.
What makes SoT interesting is that it's a data-centric optimization approach. Instead of modifying hardware configurations or model architectures, it changes how we structure the generation process itself. This represents a new direction in AI efficiency research that leverages the emerging capabilities of LLMs to plan and organize their own outputs. The approach is especially valuable because it can be combined with hardware and model-level optimizations for compounding benefits.
These data-centric optimization methods may become more important as models continue to grow in size and capability, offering a way to improve efficiency without the computational costs associated with retraining or architectural changes.
Real-world applications of SoT prompting
Skeleton-of-Thought prompt engineering has several practical applications where its benefits can significantly enhance existing AI systems:
In chatbots and virtual assistants, the speed improvements from SoT can transform user interactions. When a user asks a complex question, the difference between waiting 40 seconds versus 15 seconds for a response completely changes the conversation flow. The structured format of SoT responses also makes information easier to scan and comprehend, improving the overall user experience.
For customer support systems, SoT can organize troubleshooting procedures into clear, logical steps. The faster generation time is particularly valuable during high-volume support periods when minimizing wait times is crucial.
Content generation tools benefit substantially from SoT's approach. When creating academic summaries, research reports, or technical documentation, the skeleton stage ensures comprehensive coverage of key topics. The parallel expansion ensures efficiency without sacrificing depth. This makes SoT particularly valuable for workflows where both structure and efficiency matter, such as generating product descriptions, educational materials, or business reports.
Another application is meeting assistants and note-taking tools, where SoT can quickly organize discussion points into coherent summaries that maintain the logical relationship between topics.
Future directions
SoT opens up several promising avenues for future research and development:
Adaptive Routing
While SoT performs well for many question types, it's not optimal for all queries. Developing intelligent routing systems that can automatically determine when to use SoT versus standard generation would maximize both efficiency and accuracy.
Graph-of-Thought Expansion
Current SoT implementations treat each point in the skeleton as independent, but many complex topics have interconnected ideas. Future implementations could use a graph structure to represent dependencies between points, allowing for more sophisticated parallel processing that respects these relationships.
Fine-tuning for SoT Compatibility
Some models perform better with SoT than others, suggesting that specific training or fine-tuning could enhance compatibility with this approach. Models could be explicitly trained to create better skeletons, follow expansion instructions more precisely, or automatically adjust their generation strategy based on query complexity.
These enhancements would address some of SoT's current limitations while building on its strengths, making it applicable to an even wider range of use cases and model architectures.
For teams looking to implement SoT in their LLM applications, Portkey's prompt engineering studio can be invaluable for testing and refining the approach. By iteratively testing different prompt strategies, prompt engineers can maximize both the speed benefits and quality improvements that SoT offers.
As research in this area continues to evolve, we can expect to see more sophisticated implementations that combine SoT with other acceleration techniques, potentially revolutionizing how we interact with large language models in production environments.
Source: Skeleton-of-Thought: Prompting LLMs for Efficient Parallel Generation [arXiv:2307.15337]

