
Task-Based LLM Routing: Optimizing LLM Performance for the Right Job
Learn how task-based LLM routing improves performance, reduces costs, and scales your AI workloads
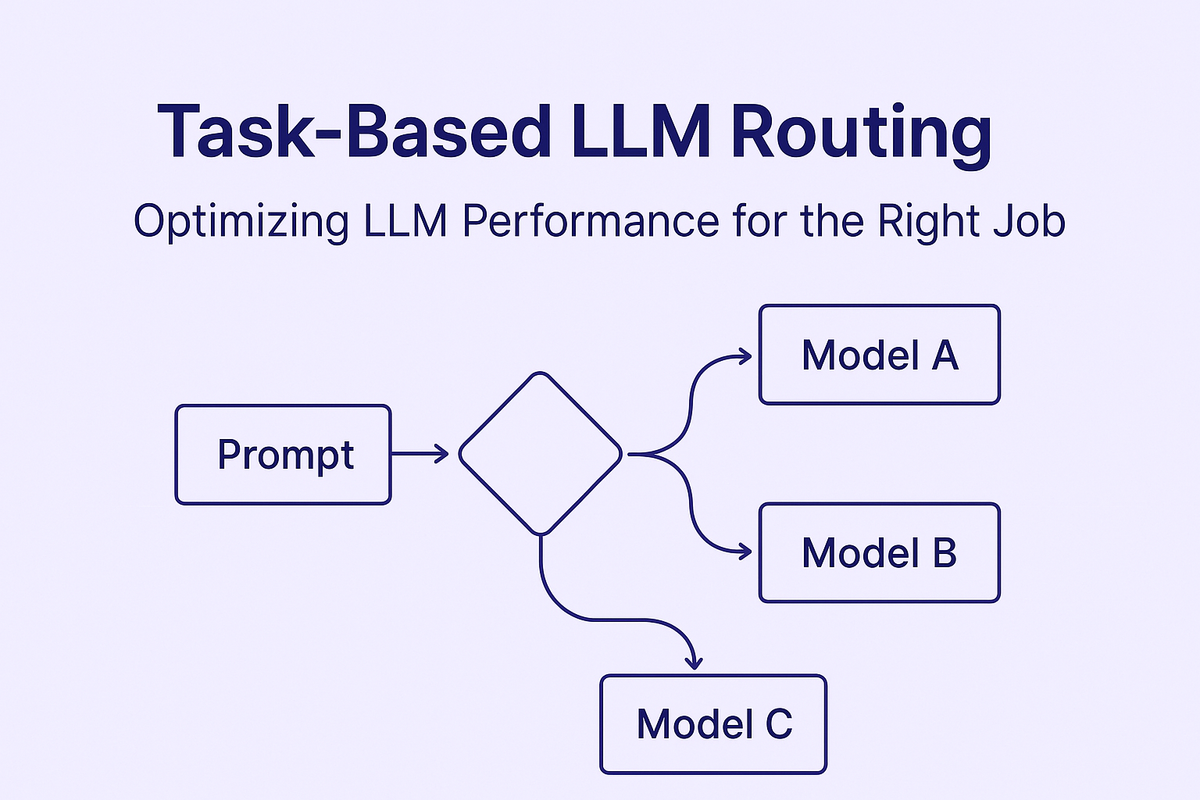
As large language models (LLMs) become central to modern AI applications, teams face a common challenge: balancing performance, cost, and response time across a growing list of use cases.
In this blog, we’ll break down what task-based routing means, why it’s gaining traction, and how to implement it effectively.
What is task-based LLM routing?
Task-based LLM routing is the practice of directing each incoming request to the most suitable large language model based on the type of task it needs to perform. Instead of relying on a single model to handle all workloads, this approach intelligently matches tasks with models optimized for those specific needs.
For example, a chatbot might use a lightweight model like GPT-3.5 for answering FAQs to minimize latency and cost, while routing long-form creative writing prompts to GPT-4 or Claude for richer, more nuanced output. Similarly, code formatting tasks might be handled by a fast, cheaper model, while code generation or debugging gets routed to a more capable one.
Why task-based LLM routing matters
Not all prompts are created equal. Some need deep reasoning, others just need speed. Task-based routing helps you align the complexity of the task with the right model, leading to clear benefits:
1. Performance optimization
Different models excel at different tasks. Routing factual queries to a model like Claude and creative tasks to GPT-4 can improve the overall quality and relevance of responses.
2. Cost efficiency
High-end models like GPT-4 are powerful but expensive. By routing only complex or high-value tasks to them and simpler ones to smaller models (e.g., GPT-3.5 or Mistral), you reduce unnecessary spend.
3. Reduced latency
Lighter models are faster. For real-time applications where speed matters, like chatbots or autocomplete, routing to faster models improves user experience.
4. Better reliability
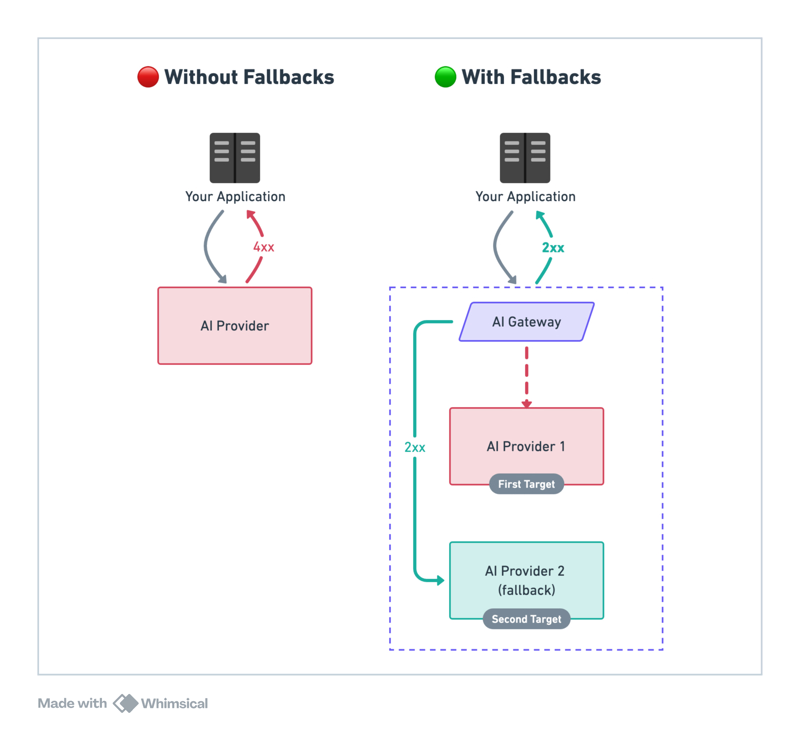
Task-based routing can include fallback logic. If a primary model fails, the system can reroute to an alternative, ensuring availability and consistency.
Common use cases for task-based LLM routing
AI models have different strengths. Some think deeply but slowly, while others respond quickly but with less nuance. That's where task-based routing comes in - it matches each prompt with the model best suited to handle it.
Task-based routing helps you send different types of requests to different AI models based on what each request needs. This approach offers several key benefits for your AI applications.
When you route factual questions to Claude and creative tasks to GPT-4, you get better answers across the board. The most powerful models cost more per request, so by sending only complex tasks to premium models like GPT-4 and routing simpler queries to more affordable options like GPT-3.5 or Mistral, you cut costs without sacrificing quality where it matters.
See how Claude compares with ChatGPT
Speed matters in many applications. Lighter models process requests faster, which makes a big difference for real-time features like chatbots or text suggestions. Users notice when responses take too long. Task-based routing also lets you create fallback options. If your first-choice model is unavailable or returns an error, your system can automatically try a different model instead. This helps maintain consistent service even when individual models have issues.
Many teams are already using task-based LLM routing in their AI systems. In customer support, simple billing questions can be routed to quick, lightweight models that follow clear rules. For product troubleshooting that needs more context, a general-purpose model works well. When customers are upset or need special care, models specifically trained to be empathetic can take over.
Content needs vary widely too. Short ad copy or simple product descriptions can go to faster, less expensive models. For long-form content or writing that represents your brand voice, you'll want to use more sophisticated models that capture nuance and maintain quality.
In retrieval-augmented generation systems, you're often doing two distinct jobs. The retrieval part can use a smaller, faster model to find relevant information, while the generation part can use a more powerful model to create detailed, accurate responses based on that information.
Code-related tasks have different complexity levels as well. Simple formatting or adding comments can be handled by quick, basic models. More complex tasks like generating new code, refactoring existing code, or debugging tricky problems benefit from advanced models like GPT-4 or Claude 3 Opus.
For multilingual applications, you can use specialized translation models for converting between languages, while sending language-specific tasks like grammar checking or summarization to models that specialize in particular languages.
Key considerations for building task-based LLM routing
When building your router, the first challenge is figuring out what task each incoming prompt represents. You have several options here. The simplest approach uses keyword matching to quickly identify task types based on specific words or phrases in the prompt. If your upstream systems already tag incoming requests, you can use these metadata tags to make routing decisions. For more sophisticated needs, you might use a small, fast model to classify each prompt's intent - whether it's asking for a summary, translation, or sentiment analysis.
No system works perfectly all the time, so plan for failures. Your router should know what to do when a model times out, returns an error, hits token limits, or reaches rate limits. Define fallback models for each task type and set up retry logic so tasks still get completed even when your first choice fails.
To improve your system over time, you need to see what's happening. Set up logging that shows which model handled each task, what each request cost, how long responses took, and whether the primary model worked or if you needed to use a fallback. This data helps you fine-tune your routing rules and make better model selections as you learn from real-world usage.
How Portkey helps implement task-based LLM routing
Building a solid task-based routing system from scratch gets complicated quickly, especially when you're working with multiple AI providers, models, and use cases. Portkey's AI gateway takes this complexity off your hands.
With support for ChatGPT, Claude, and over 250 models, Portkey lets you pick the best model for each task, regardless of which company made it. This freedom means you can choose models based on what works best, not just what's available from one provider.
Portkey makes it easy to set up routing based on what's in each request. You can route based on metadata you define, and choose the right model automatically.
{
"strategy": {
"mode": "conditional",
"conditions": [
...conditions
],
"default": "target_1"
},
"targets": [
{
"name": "target_1",
"virtual_key":"xx"
},
{
"name": "target_2",
"virtual_key":"yy"
}
]
}
When things go wrong—timeouts, rate limits, or provider errors—Portkey can automatically retry the request or fallback to a backup model. This means your application stays up and running with consistent results, without your team writing lots of extra code.
Portkey gives you full visibility into what's happening with your AI requests. You can see which model handled each request, check response times and costs for different types of tasks, and track how often your system had to use backup options. This information helps you fine-tune your routing rules based on real performance data.
As your application grows and changes, so will your routing needs. Portkey lets you make adjustments from one central place without having to change code throughout your backend every time you want to try something new.
Bottom line: Portkey takes care of the heavy lifting so you can focus on your application logic, not infrastructure or model orchestration.
Get started with smarter routing
Task-based LLM routing is essential for teams that want to scale their AI applications efficiently. By sending each task to the most suitable model, you can boost performance, cut costs, and create better experiences for your users.
But creating and maintaining this type of routing system yourself takes significant time and ongoing attention. That's where Portkey fits in. If you're looking to work smarter with your AI models and get more from your LLM applications, give Portkey a try and start optimizing your AI workloads today.

