The real cost of building an LLM gateway
When your AI apps start to scale, managing multiple LLM integrations can get messy fast. That's when teams usually realize they need an LLM gateway. Many developers jump straight to building their own solution, often without seeing the full picture of what's involved.
Drawing from what we've seen across engineering teams, let's break down what it really takes to build and run your own gateway - from the technical challenges to the hidden costs that tend to catch teams off guard.
What makes up an LLM Gateway?
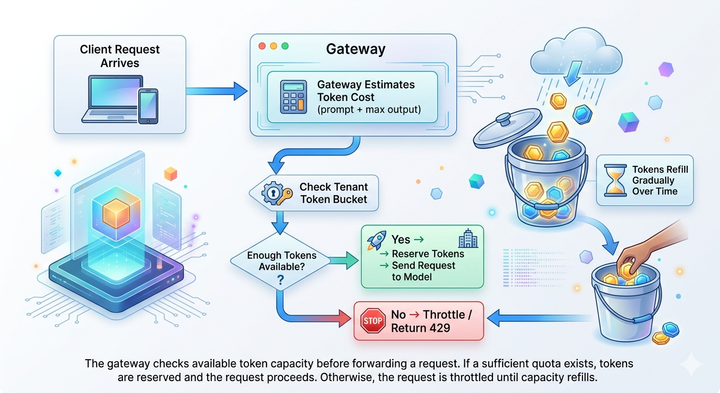
Before we talk costs, let's look at what you're actually building. An LLM gateway acts as your AI command center, handling four key jobs -
First, it manages your API connections. Want to switch between GPT-4 and Claude, or run them side by side? Your gateway handles all those integrations in one place.
Next up is keeping an eye on everything. You need to track spending, watch response times, and make sure you're getting quality outputs. The observability layer handles all of this monitoring.
Safety comes third - your gateway needs guardrails. These are the checks and balances that keep your AI outputs reliable and appropriate for your use case.
The next is prompt engineering - you need to set up prompts to guide the AI model's responses - this includes designing, optimizing and versioning of prompts.
Finally, there's the performance piece. This includes features like caching to avoid repeat API calls and load balancing to keep everything running smoothly when traffic spikes.
While each component might seem straightforward on paper, building them to production standards takes serious work. Let's walk through what that really involves.
Breaking down the costs of building an LLM gateway
Let's start with the foundation - infrastructure
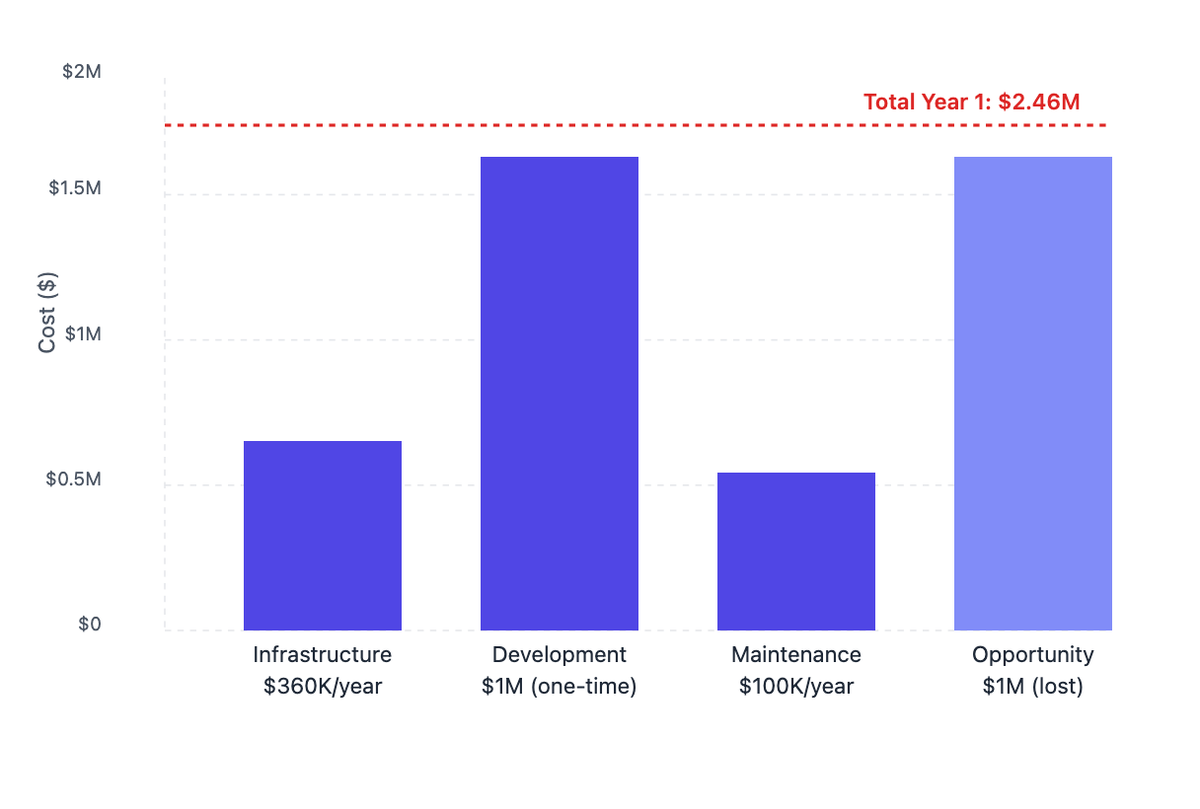
The first big chunk of your budget goes into building a rock-solid infrastructure. Here's what the numbers typically look like for a mid-sized operation.
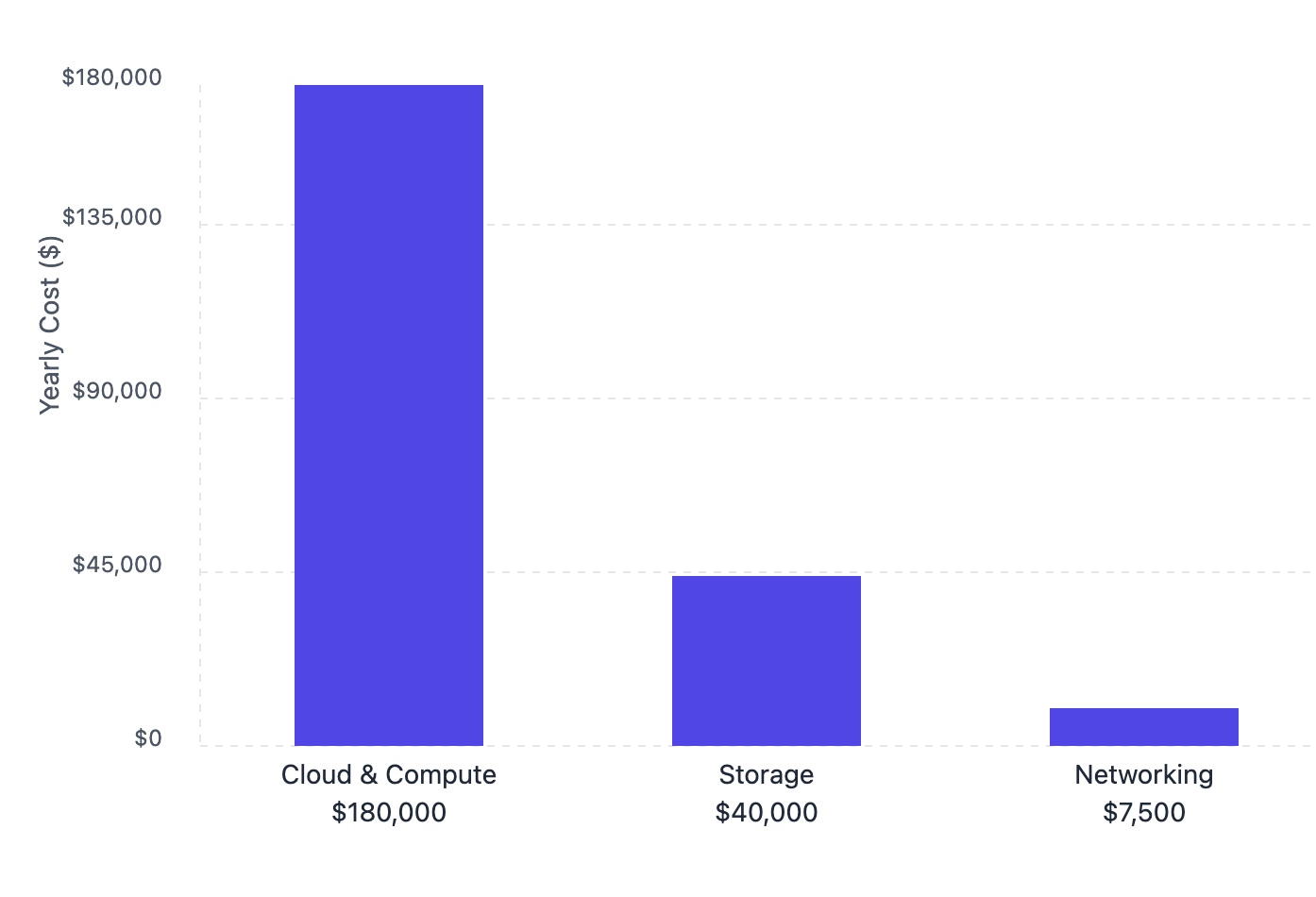
For cloud hosting and computing, you're looking at $10,000-$20,000 monthly. This isn't just about having servers running - you need infrastructure that can scale up when traffic spikes and handle requests without breaking a sweat.
Storage often catches teams by surprise. Those logs pile up fast - we're talking about every request, response, image, and metadata you process. For an enterprise setup, you're easily spending $40,000 yearly just keeping those logs on something like S3.
Then there's networking - all the plumbing that keeps data flowing smoothly. Load balancers, auto-scaling groups, and failover systems add another $5,000-$10,000 to your yearly bill. These aren't nice-to-haves; they're essential for keeping your gateway reliable in production.
Keep in mind these are baseline figures for a mid-sized operation - they can climb significantly as your usage grows.
Coming to development costs - building the brain of your gateway
Let's map out the development effort and costs that go into building a solid LLM gateway. These numbers reflect what we typically see for a production-grade system.
The core gateway design takes the biggest slice of your development budget. You're looking at 6-12 months of work from your engineering team to build out the APIs, set up load balancing, and implement retry logic. This typically runs between $200,000-$300,000, just for the basic infrastructure.
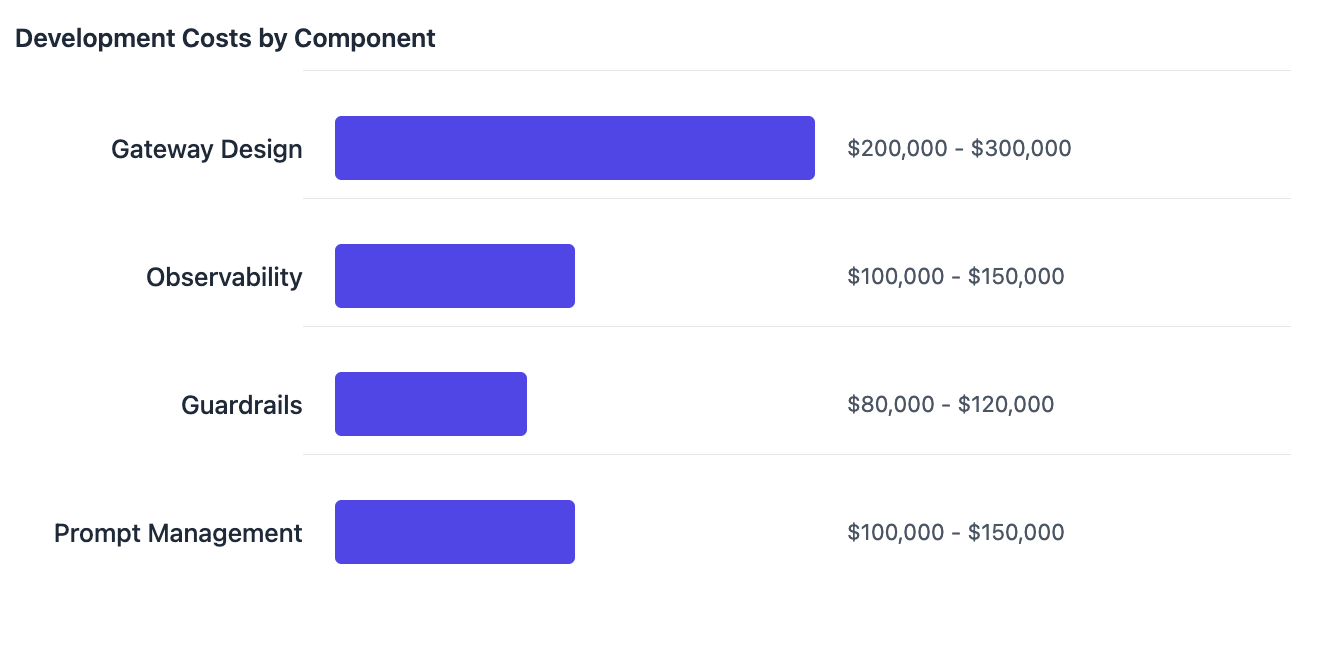
Next up is observability - and it's more complex than most teams expect. You need to track over 40 different metrics, from response times to token usage, and present them in a way that makes sense. This piece usually costs $100,000-$150,000 to build right.
Guardrails are crucial for production use. Building systems to validate outputs and keep your AI responses in check isn't quick work - expect to spend $80,000-$120,000 here.
Finally, there's prompt engineering. Your team needs a way to design, test, and deploy prompts collaboratively. Building this interface typically adds another $100,000-$150,000 to your budget.
Maintenance costs - the ongoing investment
Just launching your gateway isn't the end of the story. Here's what it takes to keep everything running smoothly:
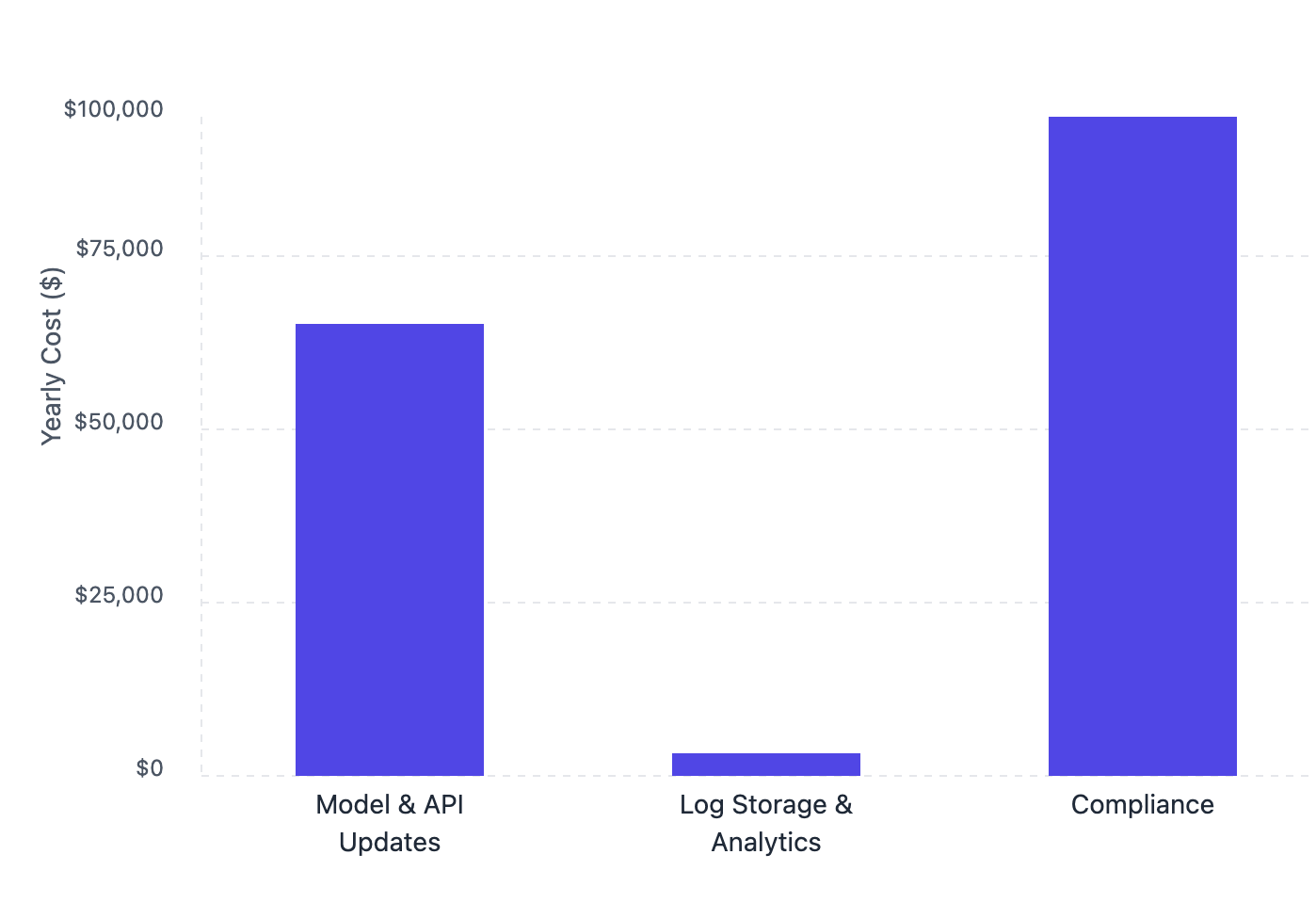
Model updates require constant attention. Every time OpenAI, Anthropic, or other providers update their APIs or pricing, your team needs to adapt. You'll typically need a dedicated engineer to handle these changes and keep everything running smoothly.
Compliance is the silent budget-eater. Keeping up with GDPR and SOC2 requirements isn't just a one-time thing. You're looking at $50,000-$100,000 every year to maintain compliance, run security audits, and implement required updates.
Next - opportunity cost
Building in-house delays AI deployments by 12–18 months. Here's what that delay really costs your business
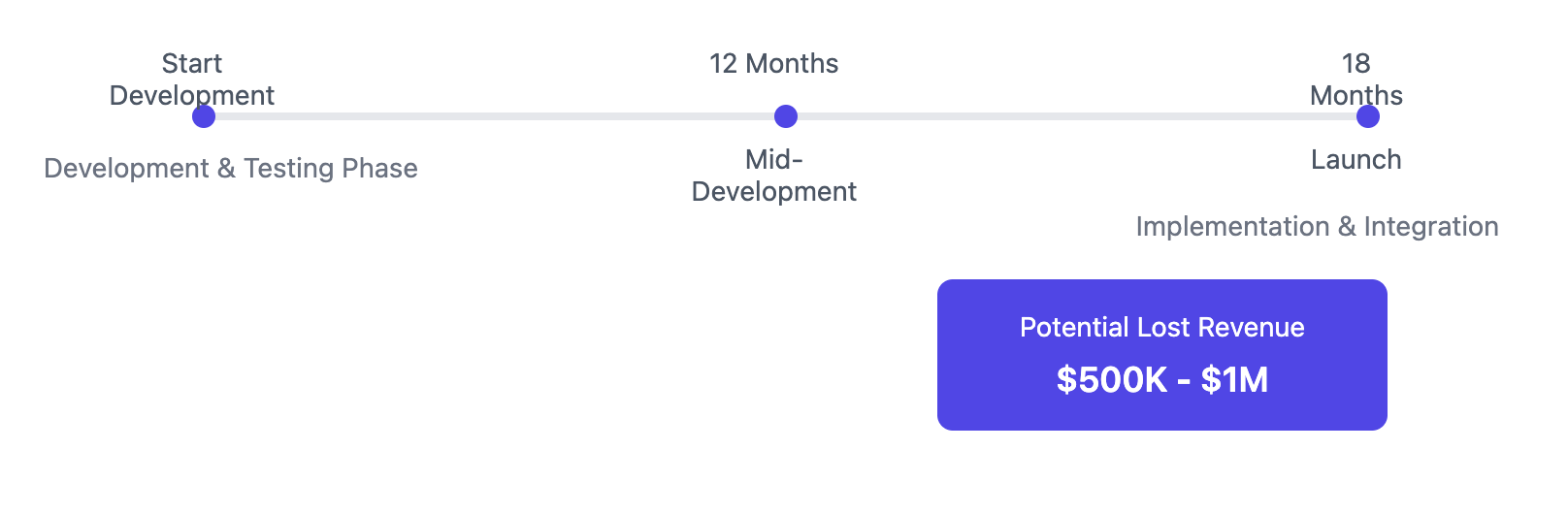
Time to Market: While you're spending a year or more building your gateway, your competitors are already deploying AI solutions. The timeline above shows how development, testing, and implementation eat up valuable time.
Revenue Impact: That delay isn't just about time - it translates directly to missed revenue. Companies typically see potential losses between $500,000 to $1,000,000 from:
- Delayed product launches
- Competitors gaining market share
- Missed early adoption advantages
- Lost productivity gains
Each month spent in development is a month you're not in the market capturing value from AI capabilities.
Hidden challenges and time drains
Let's break down these hidden challenges that often catch teams off guard. These are the complexities that don't show up in the initial project plans but end up consuming significant resources.
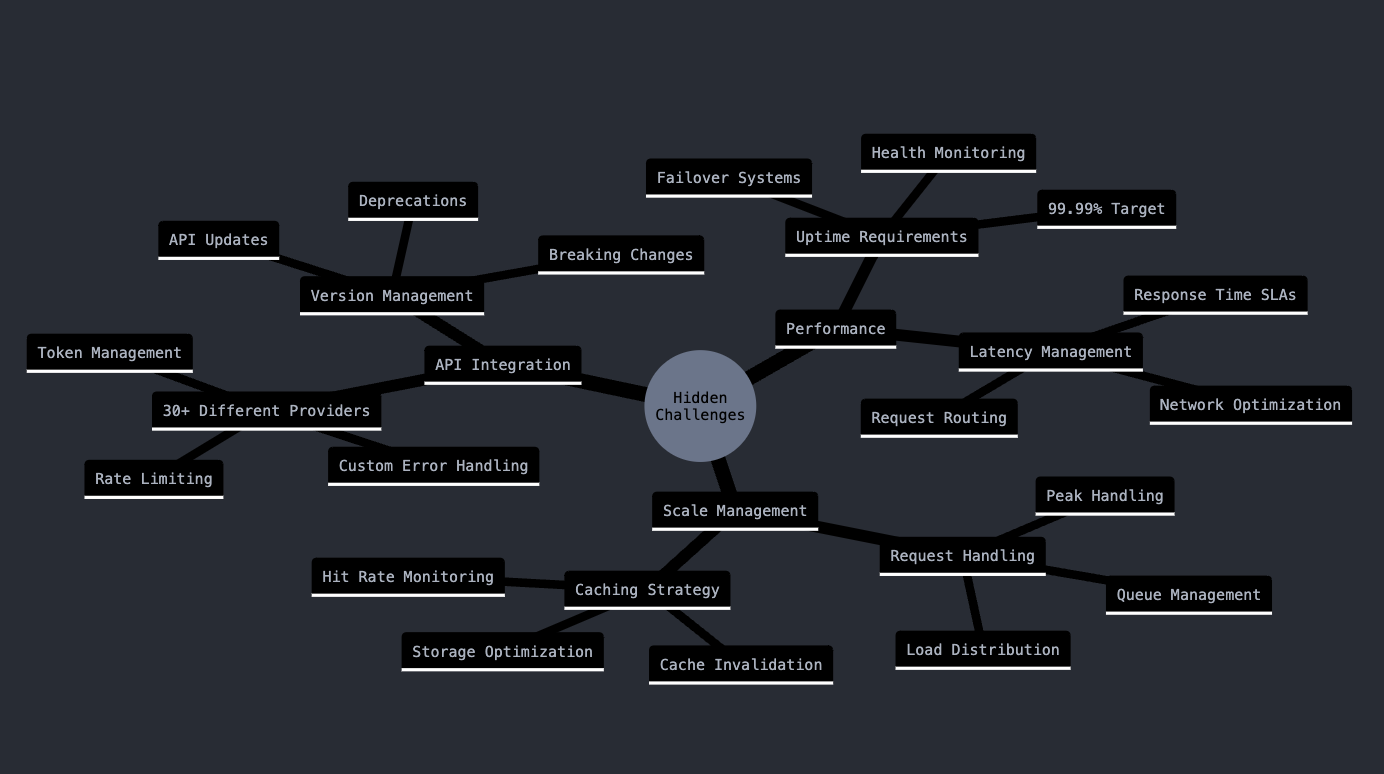
API Diversity - Think you're just connecting to a few APIs? The reality is messier. Most enterprises need to integrate with 30+ providers, and each one comes with its own quirks:
- Different authentication methods
- Unique error handling requirements
- Varying rate limits and token counting
- Custom response formats
Uptime and Latency - That 99.99% uptime target? It means you can only be down for about 52 minutes per year. Getting there requires:
- Building redundant systems
- Setting up sophisticated monitoring
- Creating automated failover mechanisms
- Constantly optimizing network routes
- Managing multiple provider SLAs
Scalability - Handling millions of requests isn't just about having bigger servers. You need:
- Smart load distribution across providers
- Complex caching strategies
- Queue management for traffic spikes
- Real-time performance monitoring
- Dynamic resource allocation
The mind map above shows how these challenges interconnect and multiply. Each branch introduces its own set of technical hurdles that your team needs to solve and maintain.
Breaking down your first-year investment
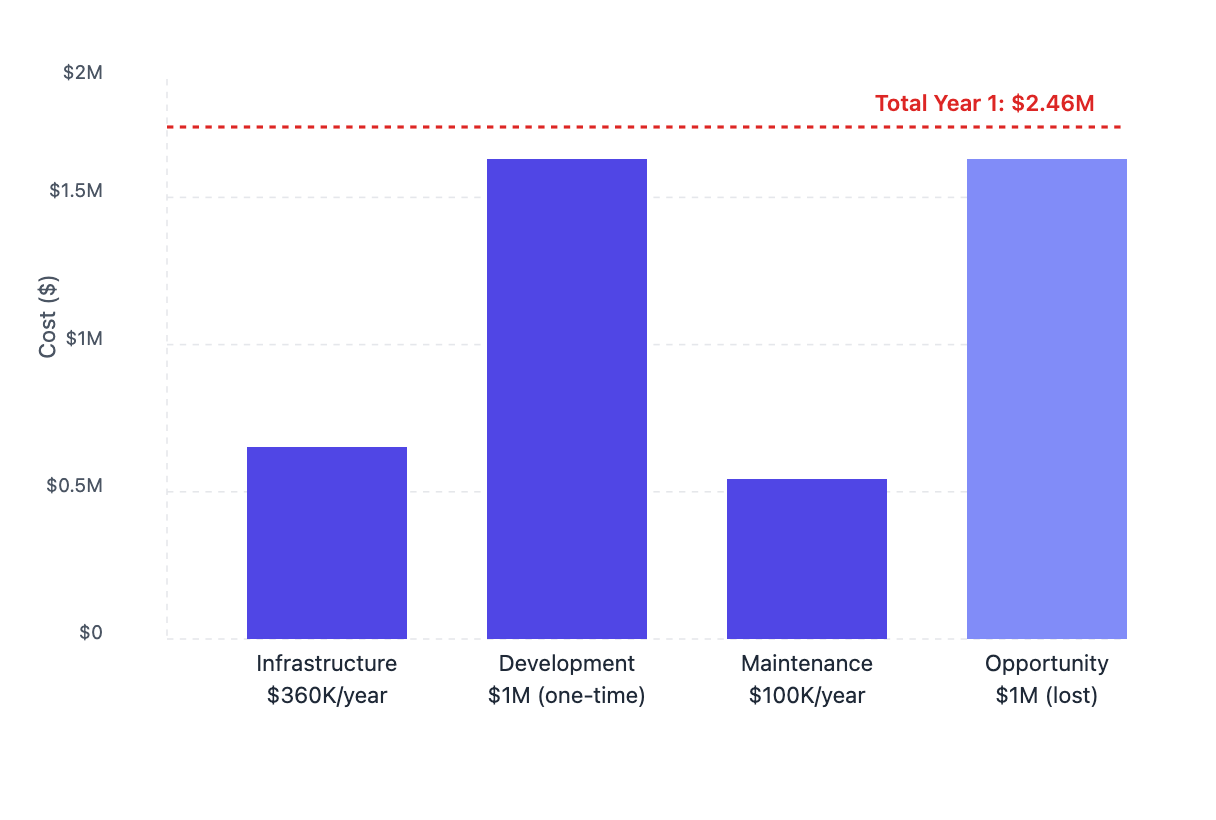
And remember, while development is a one-time cost, you'll continue paying infrastructure and maintenance costs each year after launch.
Why buying can be cheaper than building
Think of Portkey as your fast track to production-ready AI infrastructure - it's an open-source LLM gateway backed by a thriving community of 50+ contributors. You get all the enterprise features out of the box: observability, safety guardrails, multi-cloud support, and prompt management.
Instead of spending over $1.5M and waiting a year to build your own gateway, you can start deploying AI applications at scale today. For teams focused on shipping features rather than building infrastructure, Portkey's open-source solution offers the best of both worlds - enterprise reliability with community-driven innovation.
The decision comes down to this: you can spend over a year and millions of dollars building a gateway, or get started today with a ready-made solution. Rather than investing resources into building infrastructure, your team can focus on what matters most - creating AI applications that drive value for your business.
If you’re evaluating your options, let Portkey simplify your journey with a ready-to-use platform designed for scale and efficiency. Get started today