Why Portkey is the right AI Gateway for you
Discover why Portkey's purpose-built AI Gateway fulfills the unique demands of AI infrastructure. From intelligent guardrails to cost optimization, explore how Portkey empowers teams to scale AI with confidence.
As AI becomes essential to modern applications, teams need infrastructure built specifically for AI workloads. AI gateways play a crucial role here - they're the layer that manages how your apps interact with AI models.
You'll find two types of AI gateways out there. Some companies repurpose their API gateways for AI. At Portkey, we built it from scratch for AI's specific demands.
The difference matters. When you're running AI at scale, you need a gateway that understands LLM challenges. It bundles the essentials - speed, monitoring, security, and cost control - in one package that meshes with how AI teams actually work.
Built for AI-specific needs
AI infrastructure operates differently from traditional API environments. The non-deterministic nature of AI models, with requirements like streaming responses, high-latency handling, and token-based operations, pushes conventional architectures to their limits.
Many gateways attempt to repurpose existing API infrastructure for AI workloads, but these solutions often fall short. Why? Because they weren’t designed to handle the complexities of AI.
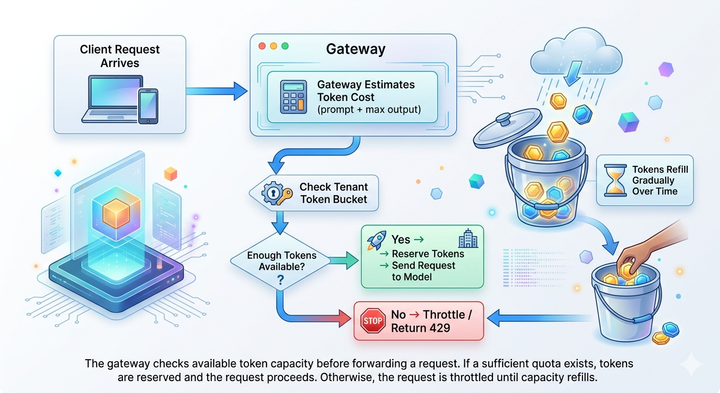
Streaming and token management are prime examples. When an AI model streams a response, you need real-time token counting for both billing and rate limiting.
Routing gets complex too. With traditional APIs, you route based on simple rules like endpoints or HTTP methods. But AI routing often needs to factor in:
- Real-time model costs (GPT-4 vs GPT-3.5)
- Current performance metrics
- Model specializations (e.g, Claude for analysis, PaLM for coding)
- Fallback paths when primary models fail
- Token quotas and budget constraints
That's why we built Portkey's LLM Gateway specifically for AI. Instead of adapting old tools, we designed a gateway that handles these challenges natively.

Deep observability tailored for AI
Traditional API monitoring tools often focus on binary outcomes—success (2XX) or failure (4XX/5XX). While this works for standard APIs, it falls short for AI workflows, where success isn’t just about a response being delivered but also about the quality and relevance of that response.
That's why we built deep monitoring into Portkey's AI Gateway. Our LLM observability module now tracks 50+ AI-specific metrics per request, giving teams real-time insights into hallucinations, token optimization, and response quality - things traditional API metrics never considered.
The goal? You see exactly what your AI models are doing, not just if they're running. When something's off, you'll know why. When costs spike, you'll see where. And when you need to optimize, you'll have real data showing where to focus.
This isn't just monitoring - it's AI-native observability that gives you the full picture of your model's behavior, costs, and performance.
Intelligent guardrails and security
Traditional API gateways rely on static security policies designed for predictable systems, but these fall short when dealing with AI models' dynamic and unpredictable nature.
Portkey introduces an AI guardrails framework tailored for these unique challenges. Unlike static policies, guardrails dynamically analyze and manage real-time outputs to ensure safety and reliability. Key capabilities include:
- Prompt security: Protect against prompt injection and other vulnerabilities that can compromise the integrity of AI interactions.
- Custom guardrails: Quickly deploy intelligent safeguards specific to your use case without weeks of development time.
- Dynamic response handling: Handle issues like irrelevant or harmful outputs, ensuring higher-quality responses.
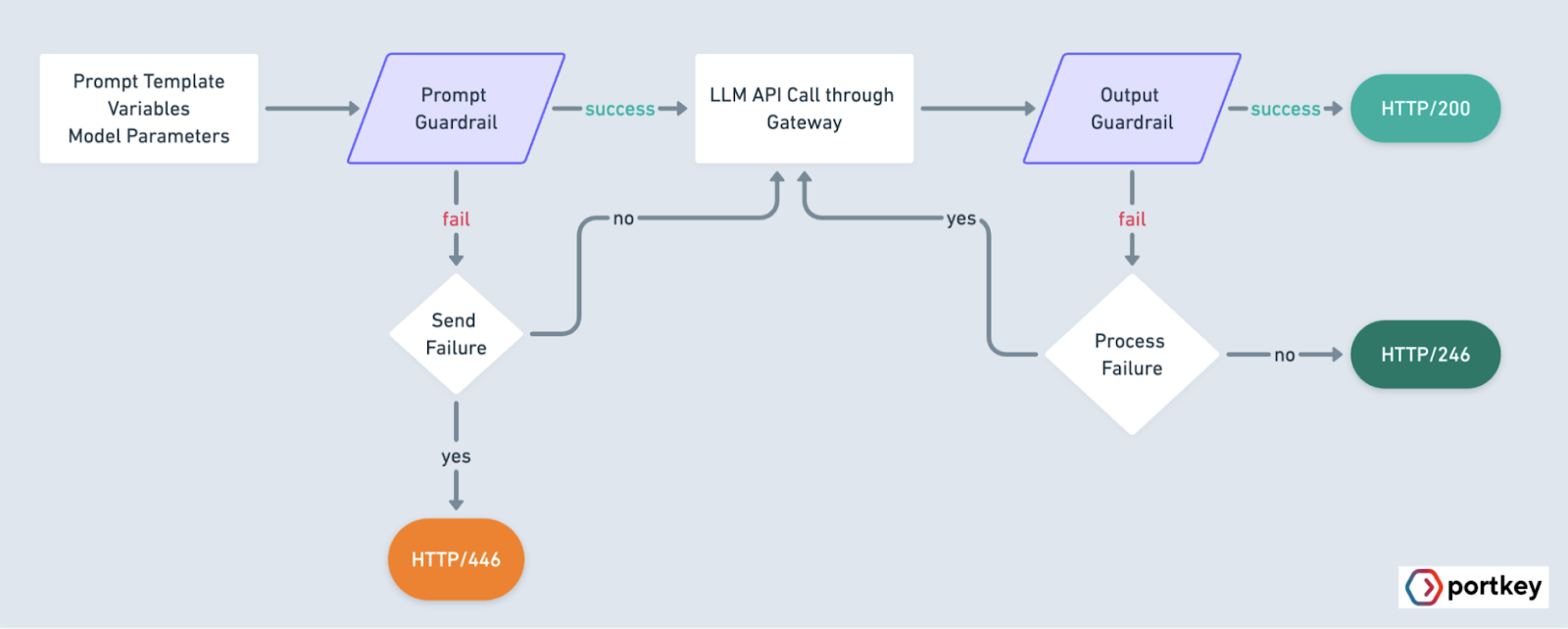
This framework builds security directly into your AI pipeline, reducing risks while maintaining consistent output quality.
Unmatched performance and scalability
AI workloads often involve high request volumes, long response windows, and unpredictable traffic patterns. Also, legacy API infrastructure was optimized for ingress & collocated services. However, AI providers are distributed across regions and cloud providers.
We built Portkey's architecture specifically for these challenges.
- Efficient resource usage: Portkey handles 1,000 requests per second with all features enabled on a machine with just 2 vCPUs—a level of performance that would require 5x the resources with traditional solutions.
- Compact edge deployment: You need the AI gateway to be lightweight enough to run across regions, to minimize roundtrip latencies. We kept the footprint small - the entire gateway is just 120kb. This lets us run right at the edge, cutting down latency when you're juggling requests across different AI providers.
- Resilience under load: Designed to handle irregular traffic spikes and high-latency AI provider interactions, Portkey ensures smooth operations even at scale.
Cost Optimisation
While API costs often revolve around bandwidth and computing, AI costs are mainly around token usage, model selection, and provider pricing.

Portkey's LLM Gateway is designed with cost-efficiency in mind, offering integrated tools to help teams optimize AI spending without sacrificing performance. Through token optimization, model routing, response caching, and other features, our users typically cut AI costs by 30-50%. No code changes needed, no performance trade-offs.
Seamless developer experience
Portkey simplifies AI infrastructure with its plugin architecture, allowing deep integration with components like evals, guardrails, security policies, and provider-specific optimizations. Instead of layering plugins on top of existing plugins, Portkey provides a solution that’s both intuitive and reliable.

Need to add custom guardrails? That's hours of work, not weeks. Want to optimize for a specific AI provider? It's built-in. Security policies? They plug right into the core system.
This means developers spend less time wrestling with infrastructure and more time building what matters. Everything's designed to work reliably at scale, so what works in testing keeps working in production.
Final thoughts
Portkey isn't a repurposed API gateway with AI features added on.

Unlike API gateways that act as reverse proxies, Portkey’s forward-proxy architecture addresses the unique needs of AI workloads, from managing non-deterministic outputs to optimizing costs and scaling efficiently.
In practice, this means comprehensive observability of model behavior, AI-native security guardrails, and developer tools designed for AI workflows. The architecture is engineered to adapt as AI capabilities expand and new models emerge.
Ready to see what a purpose-built AI gateway can do? Try Portkey and transform how you manage AI infrastructure.