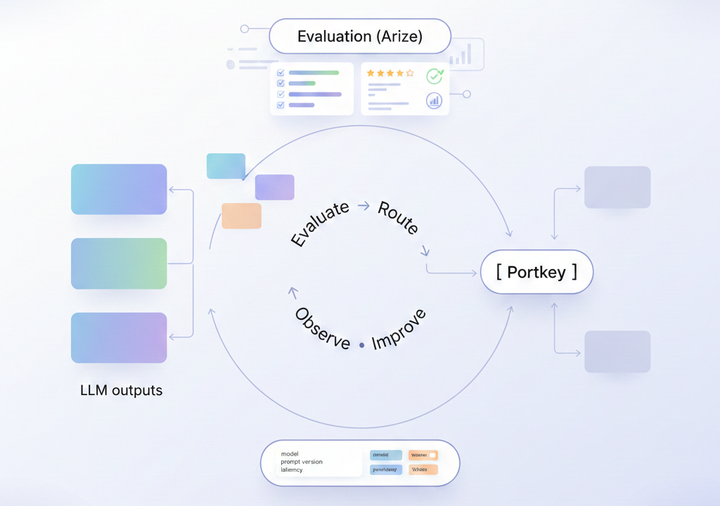
Tracking LLM token usage across providers, teams and workloads
Learn how organizations track, attribute, and control LLM token usage across teams, workloads, and providers and why visibility is key to governance and efficiency.
LLM token usage is the meter behind every model interaction. Most teams understand this in isolation: they know models bill by tokens, and they know more tokens mean more spend.
What’s harder is understanding LLM token usage across a growing landscape of workloads, teams, and providers.
This piece outlines a practical framework to make token usage traceable and governable, so platform teams can understand where tokens go, who consumes them, and how to control it.
Check this out!
What LLM token usage actually represents
Tokens represent computational work. They are how model providers meter capacity, and they sit at the intersection of pricing, latency, and efficiency.
Every interaction with an LLM breaks down into:
- Input tokens: your prompt, instructions, retrieved context, system messages
- Output tokens: the model’s response
Providers charge per thousand tokens, but two subtleties matter:
- Input vs output economics differ by provider and model
Some models are cheap to prompt but expensive to generate with; others flip the ratio. - Context window pricing quietly shifts behavior
Larger prompts mean more tokens consumed before inference even begins, especially in RAG or agent use cases.
Because of this, the most reliable view of usage and cost is not the number of API calls but it's the volume and pattern of tokens behind them.
Teams that monitor only request counts miss:
- Whether one workload is inflating output
- Whether a small number of users are consuming the majority of tokens
- Whether retries or agent loops are multiplying consumption
- Whether model selection inefficiencies are driving unnecessary spend
Token-level attribution becomes essential because tokens are where cost, usage, and intent converge.
Understanding tokens lets organizations answer questions that logs and billing pages don’t:
- Which teams or workloads consume the most tokens?
- For what purpose?
- How does one model’s efficiency compare to another’s?
- Where is usage growing fastest?
The challenge: LLM token usage is scattered, inconsistent, and difficult to act on
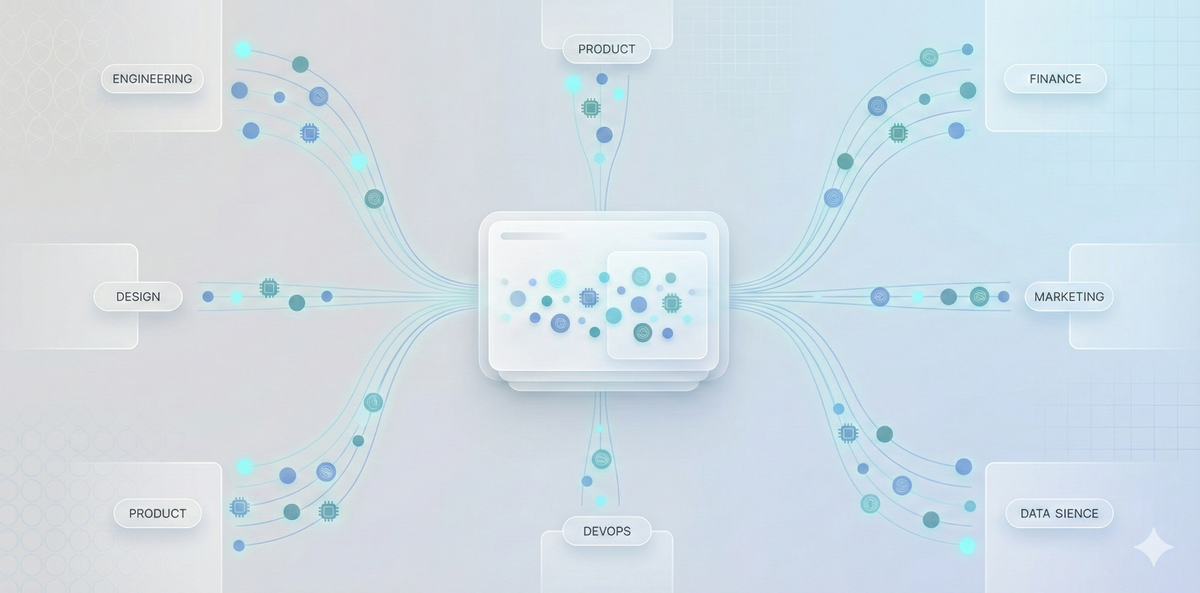
a) Token usage exists across multiple apps, teams, and experiment streams
Departments, research groups, product teams, and student initiatives all access the same AI infrastructure.
What this creates is:
- Shared consumption without shared ownership
- Shadow AI usage through unmanaged keys
- Spikes generated by experiments unknown to platform teams
b) Providers don’t standardize token behavior
Different model providers count, tokenize, and bill tokens differently.
OpenAI, Anthropic, Bedrock, Vertex, and others each use their own tokenization strategies, generation behavior, and context accounting rules. As a result, two identical workloads can produce wildly different token consumption and cost profiles depending on the model chosen.
Add tool use, function calling, or agent loops, and the variation gets amplified. This inconsistency makes forecasting and comparison unreliable without a unifying layer that normalizes token visibility.
Visibility stops at logs or billing dashboards
Most teams can see total tokens consumed or total spend, but they cannot trace tokens to purpose, owner, or intent. Billing pages tell you “how much” but not “who” or “why.”
Without attribution, organizations can’t separate productive usage from waste, identify runaway workloads, compare efficiency between models, or justify costs to leadership. Token usage becomes a static data point rather than a lever for governance, optimization, or accountability.
Components of an effective tracking framework
A useful token accounting system tags token usage it with identity, purpose, and consequence.
1. Identity and segmentation
Every request needs context. That means tagging calls with information like team, department, workspace, use case, region, or application name. Without this segmentation, all usage collapses into a single bucket, making responsibility and optimization impossible.
2. Token accounting
Counting tokens should go beyond provider billing outputs. It needs to capture input and output tokens per request, retries, parallel tool calls, and agent-loop amplification. This lets teams understand not just consumption, but where it originated and how it multiplied.
3. Attribution and allocation
Once tokens are tagged, they need to be mapped back, whether that’s a department, environment (production vs research), or workload. Some organizations prefer showback models where teams see their spend; others enforce chargeback, where usage affects internal budgets.
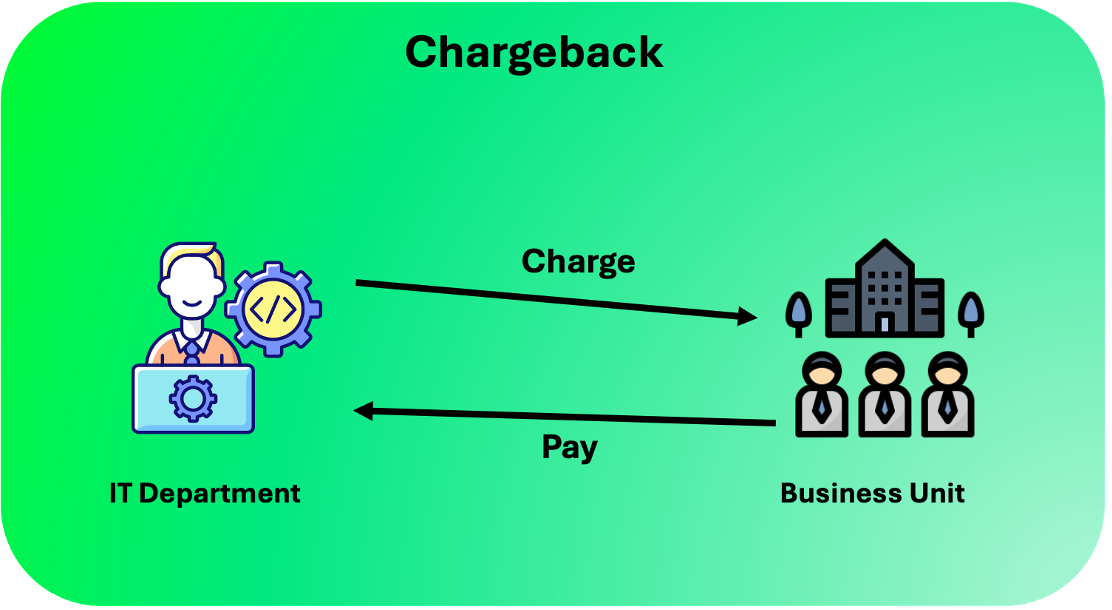
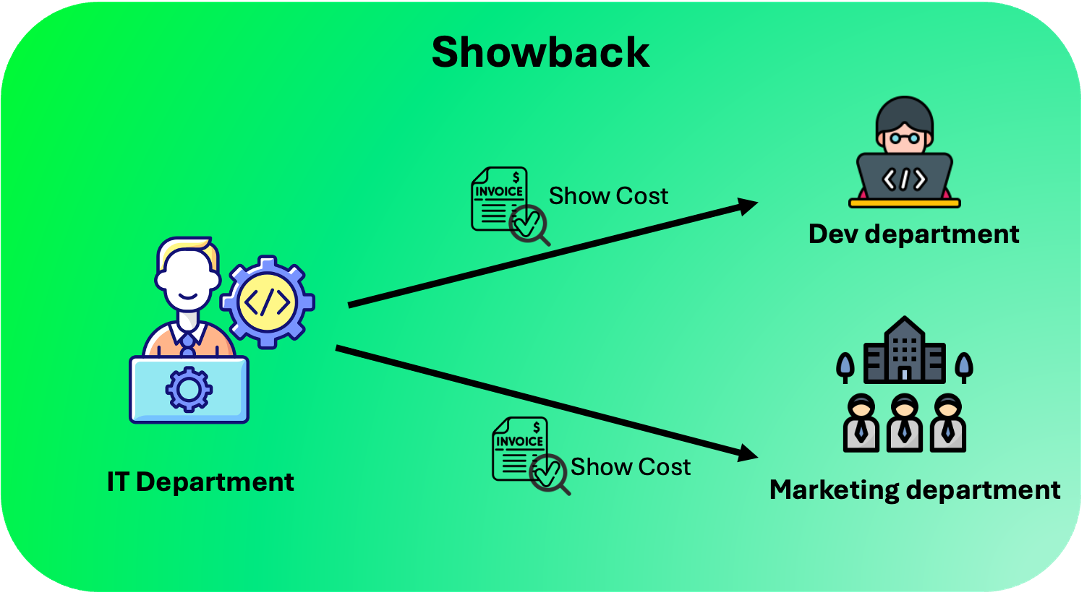
Chargeback vs Showback. Source
4. Budgeting and enforcement
Visibility without consequences doesn’t change behavior. The framework needs to support usage caps, rate limits, and budget thresholds that can apply per team, per workload, or per model. Enforcement should be automated. Exceeding budgets shouldn’t require manual intervention.
4.5 Observability and reporting
Finally, the data has to surface somewhere usable. LLM observability dashboards that track spend over time, rank workloads by consumption, highlight anomalies, and compare model efficiency help teams see patterns and course-correct. For engineering, this means identifying inefficient prompts. For leadership, it means forecasting and governance.
Together, these layers turn token usage from a billing detail into a measurable, attributable, and controllable resource.
How Portkey enables this framework in practice
Tracking LLM token usage across teams sounds straightforward until you try to implement it. Most organizations discover quickly that doing this manually means instrumenting every SDK, stitching logs from multiple providers, reconciling mismatched accounting methods, and building dashboards that nobody trusts.
Portkey solves this upstream by making token tracking a byproduct of how teams access models.
One gateway for all model access
Instead of applications calling each provider directly, Portkey's AI Gateway sits in the middle as the access layer. This gives platform teams a single entry point to observe traffic, enforce policy, and standardize token behavior even if apps are distributed, built in different stacks, or talking to multiple model vendors.
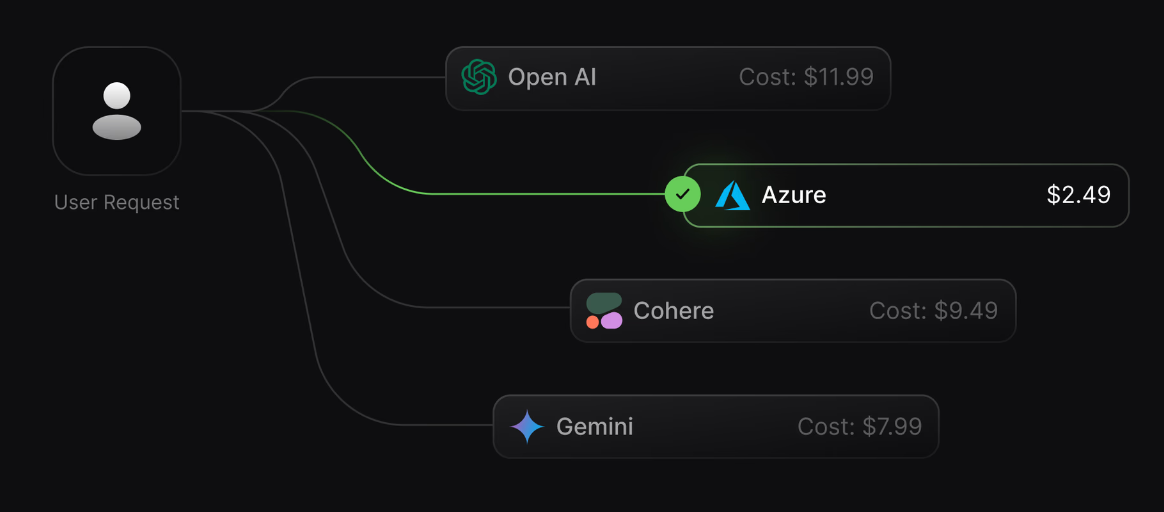
Unified token accounting
Because Portkey sees every call across OpenAI, Anthropic, Bedrock, Vertex and others, it counts tokens independently and normalizes them into a consistent format. Input tokens, output tokens, retries, agent steps, and tool calls are all logged automatically.
This eliminates the provider discrepancy problem and creates an apples-to-apples view of consumption.
Attribution through metadata and workspaces
Portkey treats context as first-class data. Teams can attach metadata like team, project, department, environment, or region to each request. Workspaces let universities, enterprises, or departments create isolation boundaries so that costs and controls apply only where intended. This turns token usage from a package of billing numbers into a structured model of accountability.
Budgets, rate limits, and automated controls
Once usage is attributed, Portkey lets platform teams enforce behavior rather than just observe it. Budgets can apply at the organization, workspace, application, or metadata-driven level. Teams can enforce soft limits with alerts or hard limits that throttle or block traffic. Rate limits ensure no single workload overwhelms provider quotas or inflates spend. Policy changes can propagate instantly without requiring application rewrites.
Observability and reporting for leaders and engineers
All of this rolls into dashboards built for different consumers:
- Engineering teams see request traces, retries, chain steps, efficiency metrics, and model comparisons.
- Finance and leadership see LLM usage breakdowns, cost tracking, trends, top consumers, and spend forecasts.
- Compliance teams gain audit records they can trace to users, workloads, and decisions.
Instead of waiting for billing cycles to discover runaway usage, teams see it in near-real time and can intervene automatically if needed.
Best practices for platform teams
Make metadata mandatory
Treat contextual tagging as a requirement. Teams should not be able to send requests without specifying owner, workload, or environment. This is what turns consumption into accountability.
Track retries, failures, and agent loops
Usage spikes rarely come from single requests. They come from chains, retries, or looping agents. Logging these flows ensures inflated usage isn’t misinterpreted as application demand.
Compare token efficiency, not just volume
Two workloads consuming the same tokens may produce radically different outcomes. Track how many tokens are required per resolved ticket, per generated page, or per student interaction. This is where token optimization payoff lives.
Normalize costs across models
Teams often switch models based on perceived accuracy, but cost per task is a better lens than tokens alone. Standardized token counting enables apples-to-apples efficiency comparisons that influence routing and model selection.
Give visibility to both finance and engineering
Finance needs clarity for budgeting and allocation. Engineers need insight for optimization. Token visibility should be accessible to stakeholders who drive decisions.
The way forward
Teams don’t lose budget because models are mysterious, they lose budget because usage is opaque.
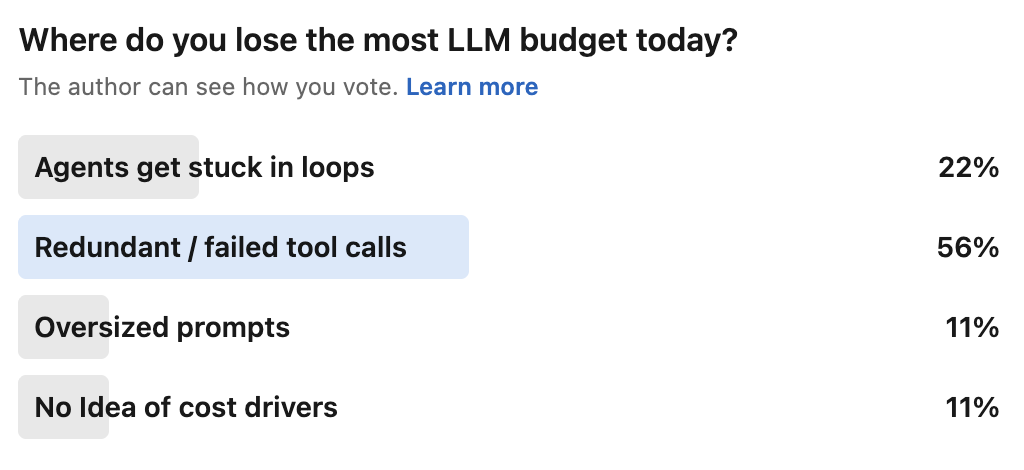
A tracking framework shifts token usage from something that happens to organizations into something they can measure, attribute, and influence. When every request carries context, when tokens are normalized across providers, and when budgets and rate limits can be enforced automatically, governance stops being reactive.
Portkey exists so teams don’t have to stitch this together themselves. If you're serioud about managing usage and spends for your team or organization, get started with Portkey or book a demo with our team.