

How to improve LLM performance
Learn practical strategies to optimize your LLM performance - from smart prompting and fine-tuning to caching and load balancing. Get real-world tips to reduce costs and latency while maintaining output quality
Getting the most out of Large Language Models (LLMs) takes fine-tuning - both literally and figuratively. Sure, these AI apps can work magic, but making them run efficiently in production is another story. Whether you're trying to keep costs down, speed up response times, or balance both, you need the right approach.
Let's look at some practical ways to optimize your LLM performance and a tool that makes the whole process easier.
Optimize prompts for efficiency
Prompt design plays a critical role in the quality and speed of LLM responses. A well-crafted prompt ensures the model understands the task while reducing unnecessary token usage. Prompt engineering techniques like chain-of-thought prompting, few-shot prompting, etc. can drastically improve your LLM performance.
Structured queries and clear instructions further eliminate ambiguity, ensuring faster and more accurate responses.
Fine-tuning LLMs for specific use-cases
Fine-tuning helps your LLM understand your specific domain without complex prompts, improving LLM performance. By training on your data - whether it's legal docs, medical records, or customer support tickets - the model learns industry terms and context naturally.
The payoff? Faster responses, better accuracy, and less prompt engineering overhead. A model fine-tuned on legal documents picks up terms like "tort" or "amicus curiae" automatically. Similarly, one trained in medical records understands conditions and treatments without extra context.
When you fine-tune a model, your prompts get shorter because you don't need to spell everything out. A model that knows legal terms understands "draft a tort claim" without needing a definition of what a tort is.
The model also gets faster at its job. Since it's trained specifically for your field, it spends less time figuring out context and more time giving you useful answers. This means quicker responses and lower costs since you're using fewer tokens per request.
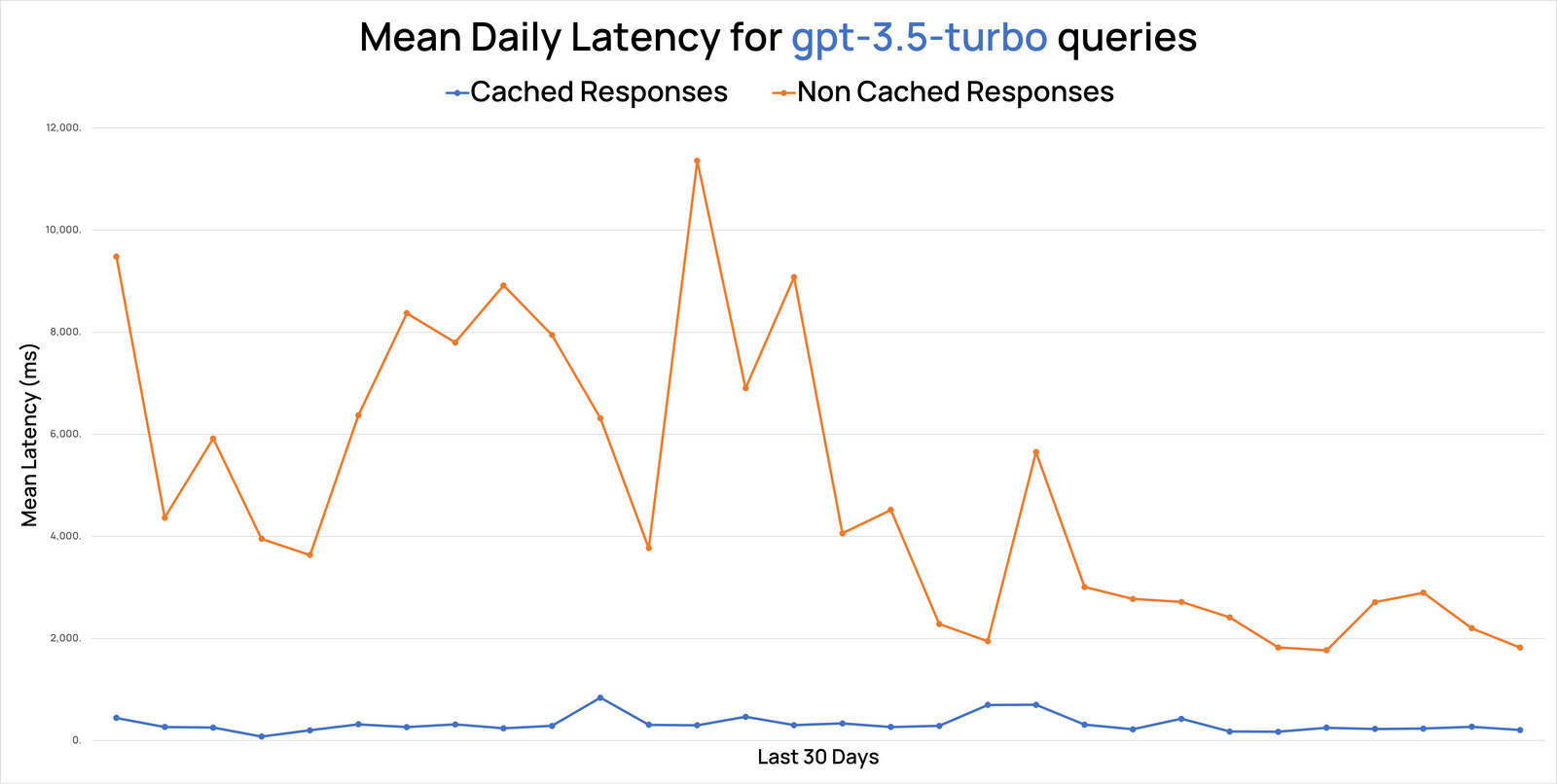
Caching
For LLMs handling repeat questions, smart caching cuts response times and costs significantly.

Simple caching stores exact matches between queries and responses. When a user asks "What's your return policy?", the system checks if this exact question exists in the cache before calling the API.
Semantic caching is smarter - it recognizes similar questions, not just exact matches. If someone asks "Tell me about returns" or "How do returns work?", the system can serve the cached "return policy" response since they're semantically equivalent.
Implementation strategies:
- Store both exact queries and semantic embeddings
- Use vector similarity for semantic matching
- Set cache TTL based on content volatility
- Monitor cache performance metrics
- Scale with distributed caching systems
Monitor and measure performance continuously
Performance optimization is an ongoing process that requires continuous monitoring. Key metrics to track include latency (response time), throughput (requests handled per second), and accuracy (output quality).
Observability tools provide real-time insights into these metrics, helping identify bottlenecks or inefficiencies. Regular audits and feedback loops ensure that the LLM adapts to evolving requirements and maintains optimal performance.
A better way to improve LLM performance
If you’re looking to handle all your LLM optimizations in one place, Portkey can help. It takes the headaches out of managing LLM performance, so you can focus on building great AI applications.
Want to test different prompts? Portkey helps you craft and refine them while tracking token usage and response quality. No more guesswork about which prompts work best - you'll see the results right there.
Need to fine-tune models for your specific needs? You can do it right in the platform. Train your models on your data without juggling multiple tools or dealing with complex setups. Watch the training progress and see how your model improves over time.
The built-in smart caching system learns from your usage patterns. When users ask similar questions, it serves cached responses instantly, cutting down on API calls and costs. Plus, it's smart enough to recognize when questions mean the same thing, even if they're worded differently.
On the infrastructure side, Portkey handles the heavy lifting. It scales resources automatically based on your needs and keeps an eye on everything from response times to API costs. You'll spot potential issues before they become problems.
What makes Portkey special is how it brings all these pieces together. Instead of cobbling together different tools and hoping they work well together, you get one smooth system that helps you build better AI applications while keeping costs in check.
Looking to improve your LLM performance? Get started today.

