Benchmarking the new moderation model from OpenAI
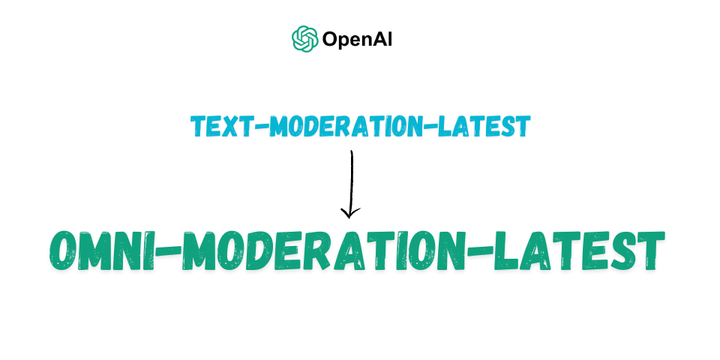
OpenAI's new "omni-moderation-latest" model shows significant improvements over the legacy model, especially in multilingual performance and image moderation.
We benchmark it's capabilties with it's predecessor.