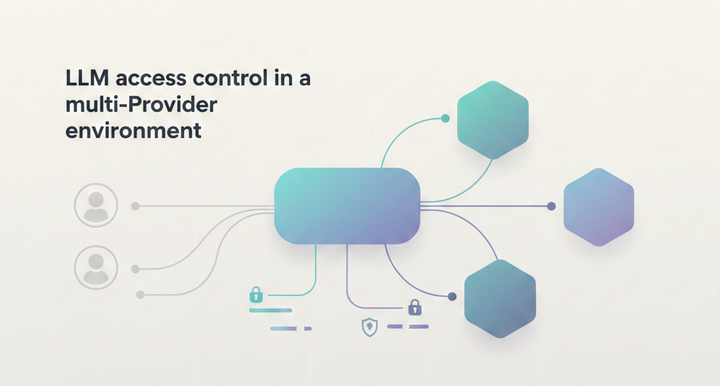
What is LLM Orchestration?
Learn how LLM orchestration manages model interactions, cuts costs, and boosts reliability in AI applications. A practical guide to managing language models with Portkey
Building AI apps with large language models (LLMs) opens up amazing possibilities - but it also brings some real headaches. Whether you're coordinating multiple models, managing API calls, or trying to keep costs under control, there's a lot to juggle. That's what LLM orchestration is all about.
LLM orchestration is about managing AI applications' interactions with large language models in a structured way. Instead of making basic API calls, it creates a system to coordinate multiple models, balance costs, track performance, and maintain reliability. The system handles key tasks like picking the right model for each job, storing responses for reuse, monitoring operations, and enforcing security rules - all to make AI workflows run better.
Why do you need LLM orchestration?
Running AI applications at scale brings unique challenges, and this is where proper orchestration becomes essential - it helps you balance the books while keeping performance high. Smart caching and resource management mean you're not paying for the same computations twice.
Cost management is just the start. As your AI applications grow, you'll find yourself working with multiple models to handle different tasks. Good orchestration makes this complexity manageable. You can scale up operations smoothly, add new models when needed, and handle increasing request volumes without disrupting your existing services.
Of course, technical hiccups are inevitable when working with AI services. Models have downtime, APIs hit their limits, and responses sometimes take longer than expected. A well-designed orchestration system handles these challenges automatically. It includes backup plans for when things go wrong, switching between models as needed, and retrying failed requests intelligently. These behind-the-scenes adjustments keep your applications running smoothly even when individual components hit snags.
Organizations also need to maintain control over their AI operations. Different projects have different requirements around security, data handling, and output quality. Orchestration provides a central point for enforcing these policies consistently across all your AI applications. When rules change, you can update them once and know they'll be applied everywhere.
Core elements of LLM orchestration
Smart Prompt Handling
Set up a robust prompt management system that standardizes how you talk to LLMs. This means creating reusable templates, tracking which prompts work best, and updating them based on performance data. Your prompts should adapt to different use cases while maintaining quality - whether you're doing text analysis, content generation, or data extraction.
Model Selection and Backup
Build a smart routing system that matches tasks to the most suitable models. This means setting clear criteria: maybe you need GPT-4 for complex reasoning but a smaller model works fine for text classification. Your system should automatically switch to backup models if the primary one fails, hits rate limits, or costs too much. Track the success rates of these switches to fine-tune your routing rules.
Context Management
Develop a solid strategy for handling conversation history and relevant context. This goes beyond just storing past messages - you need to decide what context matters, how long to keep it, and when to clear it. Good context management means knowing when to summarize long conversations, what details to preserve, and how to feed this context back to your models effectively.
Performance Tracking
Set up comprehensive monitoring that covers all key metrics: response times, token usage, error rates, and output quality. Break down costs per model and per task type. Track how different prompts perform with different models. Set up alerts for unusual patterns or performance drops. This data helps you optimize your system and justify your architecture choices.
Protection and Rules
Implement security at every level - from API access to data handling. Set up role-based access control for different parts of your system. Build data filtering and sanitization into your pipeline. Make sure you can trace how data flows through your system and prove you're meeting compliance requirements. Consider implementing content filtering and output validation.
Smart Resource Use
Design an intelligent caching system that knows what responses to store and for how long. Set up rate limiting that balances between different API endpoints and adapts to usage patterns. Track cache hit rates and adjust caching rules based on actual usage. Build in retry logic that handles API failures gracefully without wasting resources.
Selecting an LLM Orchestration Framework
Selecting a framework for LLM orchestration requires evaluating several technical and operational factors. A thorough assessment ensures your infrastructure can support both current needs and future expansion.
Your framework's scalability capabilities should be a primary consideration. Assess how it manages concurrent requests, handles distributed workloads, and coordinates multiple LLM providers. The architecture should support horizontal scaling and maintain performance under varying load conditions without requiring significant infrastructure changes.
Next, you need to examine the framework's caching mechanisms, model routing algorithms, and rate limiting implementations. These components should work together to optimize resource utilization while maintaining response quality. Look for granular controls over model selection and request patterns.
Also, the framework should be able to integrate smoothly with your current LLM providers, API endpoints, and development stack. Review the available SDKs, API specifications, and integration patterns to make sure they align with your architecture.
Security architecture needs to be comprehensive as well. Evaluate the framework's access control systems, data encryption capabilities, and compliance features. The security model should support fine-grained permissions, audit logging, and industry-standard compliance frameworks without compromising system performance.
You need monitoring capabilities need to provide deep visibility. Look for frameworks offering detailed telemetry, performance metrics, and real-time analytics. The observability stack should capture key metrics across your entire LLM pipeline while supporting custom instrumentation for specific use cases.
How Portkey Simplifies LLM Orchestration
Portkey stands out as a comprehensive platform that brings together all the essential elements of LLM orchestration in one place. The platform handles model routing with precision - directing each request to the most suitable LLM based on your defined parameters. This goes beyond simple API routing by factoring in performance requirements, cost constraints, and specific use case needs.

The platform implements systematic guardrails across your LLM operations. Your team can set clear boundaries for model interactions, enforce security protocols, and maintain consistent output quality.
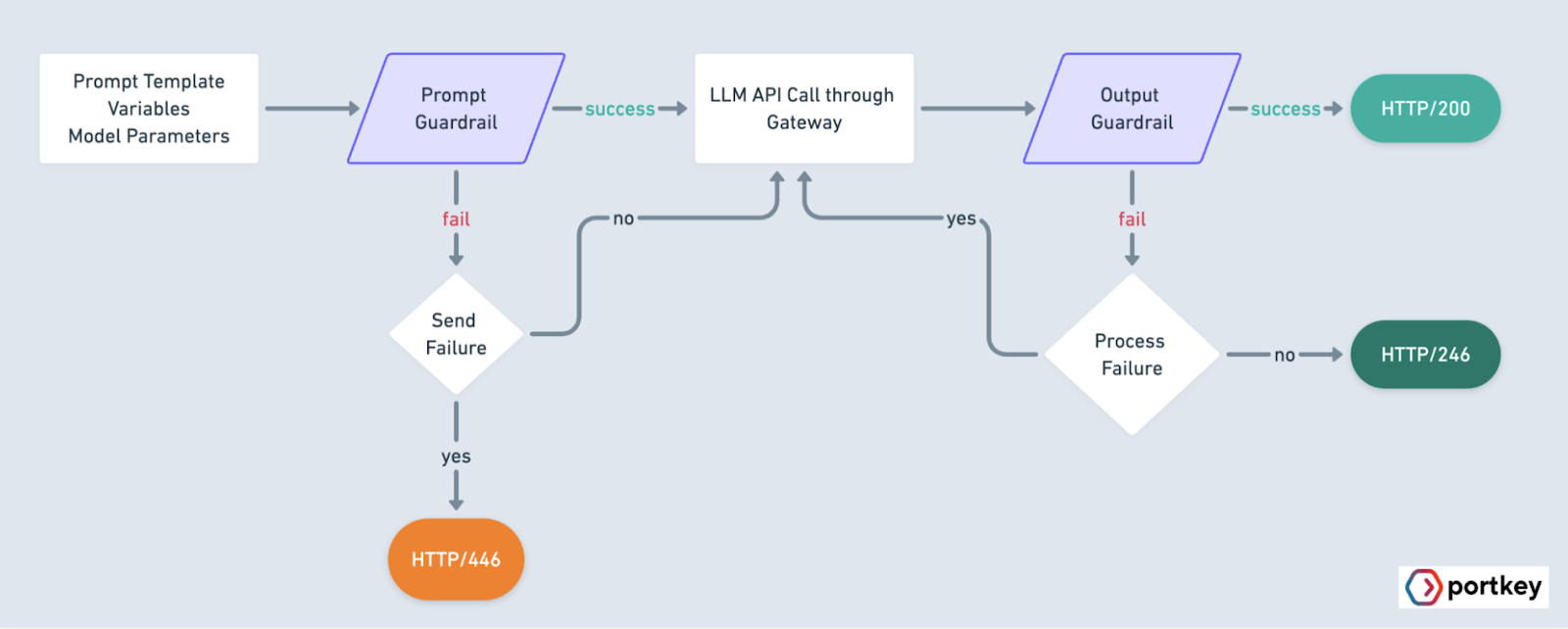
Cost optimization runs deep in Portkey's architecture. The platform tracks token usage, manages request patterns, and implements intelligent caching strategies. You get real-time visibility into spending across different models and endpoints, along with tools to optimize LLM costs without sacrificing performance.
The platform also provides an observability layer to collect and analyze detailed metrics about your LLM interactions - from response times and success rates to token usage patterns and error types. This data isn't just collected; it's presented in ways that help you make informed decisions about your AI infrastructure.
By bringing these capabilities together in a cohesive system, Portkey eliminates the need to build and maintain complex LLM orchestration logic internally. Teams can deploy sophisticated LLM applications while maintaining control over their AI operations, all through a single, integrated platform.
Ready to see how proper LLM orchestration can transform your operations? Try Portkey today!