
Summary
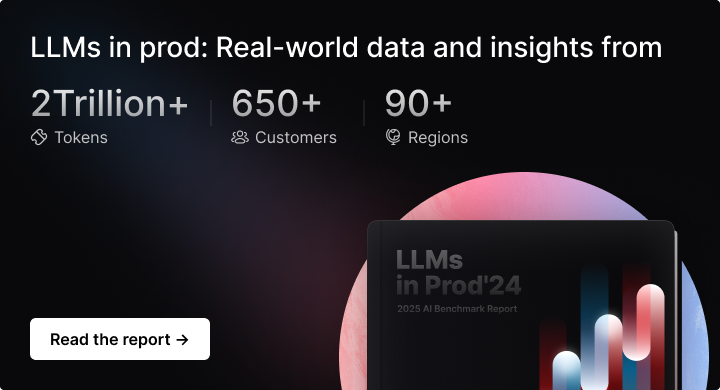
Multi-LLM is the New Normal
Despite OpenAI’s dominance (>50% of prod traffic), teams are actively implementing multi-LLM strategies for reliability and specialized use cases
Prompts are Getting Complex
Average prompt size has increased 4x in the last year, indicating more sophisticated engineering techniques and complex workloads
Caching is Critical
Implementation of proper caching strategies leads to up to 40% cost savings - a must-have for production deployments
Read the full LLMs in Prod 2025 Report →
Platform
Advanced PII Redaction We’ve significantly enhanced Portkey’s Guardrails with request mutation capabilities. When any sensitive data (like email, phone number, SSN) is detected in user requests, our PII redaction automatically replaces it with standardized identifiers before it reaches the LLM. This works seamlessly across our entire guardrails ecosystem, including AWS Bedrock Guardrails, Patronus AI, Promptfoo, Pangea, and more. Unified Files & Batches API Managing file uploads and batch processing across multiple LLM providers is now dramatically simpler. Instead of building provider-specific integrations, you can:- Upload once, use everywhere - test your data across different foundation models
- Run A/B tests seamlessly across providers - Choose between native provider batching or Portkey’s custom batch API
- Configure your model’s base URL
- Set required authentication headers
- Start routing requests through our unified API
- Automatically monitor how a service/user is consuming Portkey API by enforcing metadata
- Apply Guardrails on requests automatically by adding them to Configs and attaching that to the key
- Set default fallbacks for outgoing request
Enterprise
Running AI at scale requires robust security, visibility, and control. This month, we’ve launched a comprehensive set of enterprise features to enable that:Authentication & Access Control
- JWT Authentication: Secure API access with JWT tokens, with support for JWKS URL and custom claims validation.
- Workspace Management: Manage workspace access and control who can view logs or create API keys from the Admin dashboard
Governance & Compliance
- Metadata Schemas: Enforce standardized request metadata across teams - crucial for governance and cost allocation
- Audit Logging: Track every critical action across both the Portkey app and Admin API, with detailed user attribution
- Security Settings: Expanded settings for managing logs visibility and API key creation
Customer Love
After evaluating 17 different platforms, this AI team replaced 2+ years of homegrown tooling with Portkey Prompts.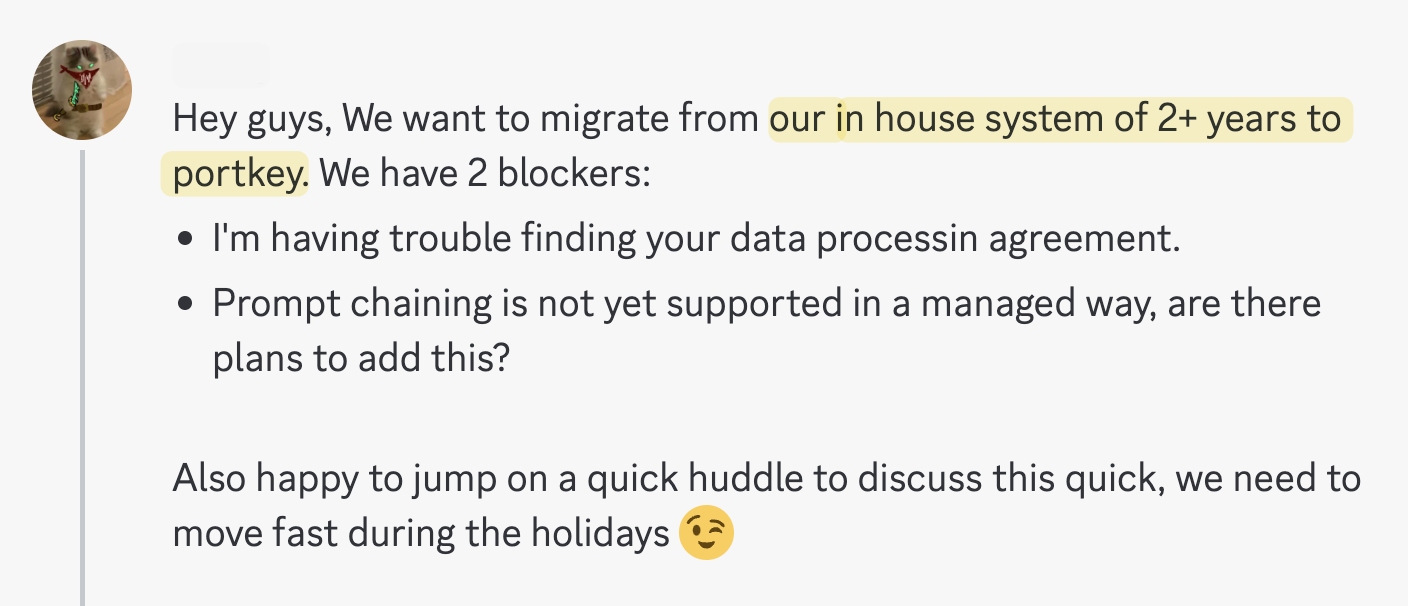
- They could build reusable prompts with our partial templates
- Our versioning let them confidently roll out changes
- And they didn’t have to refactor anything thanks to our OpenAI-compatible APIs
Integrations
Models & Providers
Deepseek R1
Access Deepseek’s latest reasoning model through multiple providers: direct API, Fireworks AI, Together AI, Openrouter, Groq, AWS Bedrock, Azure AI Inference, and more.
Gemini Thinking Model
To keep things OpenAI compatible, you can decide if you’d like Portkey to return the reasoning tokens or not
o3-mini
Available across both OpenAI & Azure OpenAI
Perplexity Sonar
Along with support for their citations and other features
Replicate
Full support for Replicate’s model marketplace
Libraries & Tools
Milvus DB
Direct routing support for Milvus vector database
Qdrant DB
Direct routing support for Qdrant vector database
Open WebUI
Expanded integration capabilities
Langchain
Enhanced documentation and integration guides
Guardrails
Inverse Guardrail All eligible checks now have anInverse option in the UI - which triggers a TRUE verdict when the Guardrail verdict fails.
AWS Bedrock Guardrails
Native support for AWS Bedrock’s guardrail capabilities
Community

LLMs in Prod Mumbai
LLMs in Prod NYC
Resources
EDA for Agents
- LLMs in Prod Report 2025: Comprehensive analysis of production LLM usage patterns
- The Real Cost of Building an LLM Gateway: Understanding infrastructure investments
- Critical Role of Audit Logs: Enterprise AI governance
- Error Library: New documentation covering common errors across 30+ providers
- Deepseek on Fireworks: How to use Portkey with Fireworks to call Deepseek’s R1 model for reasoning tasks
Improvements
- Token counting is now more accurate for Anthropic streams
- Added logprobs for Vertex AI
- Improved usage object mapping for Perplexity
- Error handling is more robust across all SDKs
Support
Need Help?
Open an issue on GitHub
Join Us
Get support in our Discord