Summary
How Snorkel AI runs multi-agents evals for frontier models
Snorkel AI has been doing some fascinating work around evaluating frontier models from Anthropic, Google, and others. Their team built a multi-agent evaluation system that plans, reasons, and verifies model outputs. As the scale and complexity of these eval workloads increased, they needed a way to move beyond fragmented scripts and logs toward a single, reliable source of truth for debugging. Read their full breakdown that includes architecture, evaluation flows, learnings, and infrastructure decisions.
Platform
Budget policies
You can now define usage budgets and throughput controls at an organization or team level, without configuring them individually using budget policies. You can create usage limits and rate limit policies with conditions based on:- API keys
- Metadata fields
- Workspaces
- Combined multi-condition rules
URL support in Conditional Router
You can match requests based on the request’s URL path, increases the for routing and giving you granular control over model selection. Read more about this here.
From the who’s who in the industry!
Observability
Improved trace visibility
You can now see traces by category, making it easier to understand whether traffic originated from chat, batch, routing, agent calls, or system functions.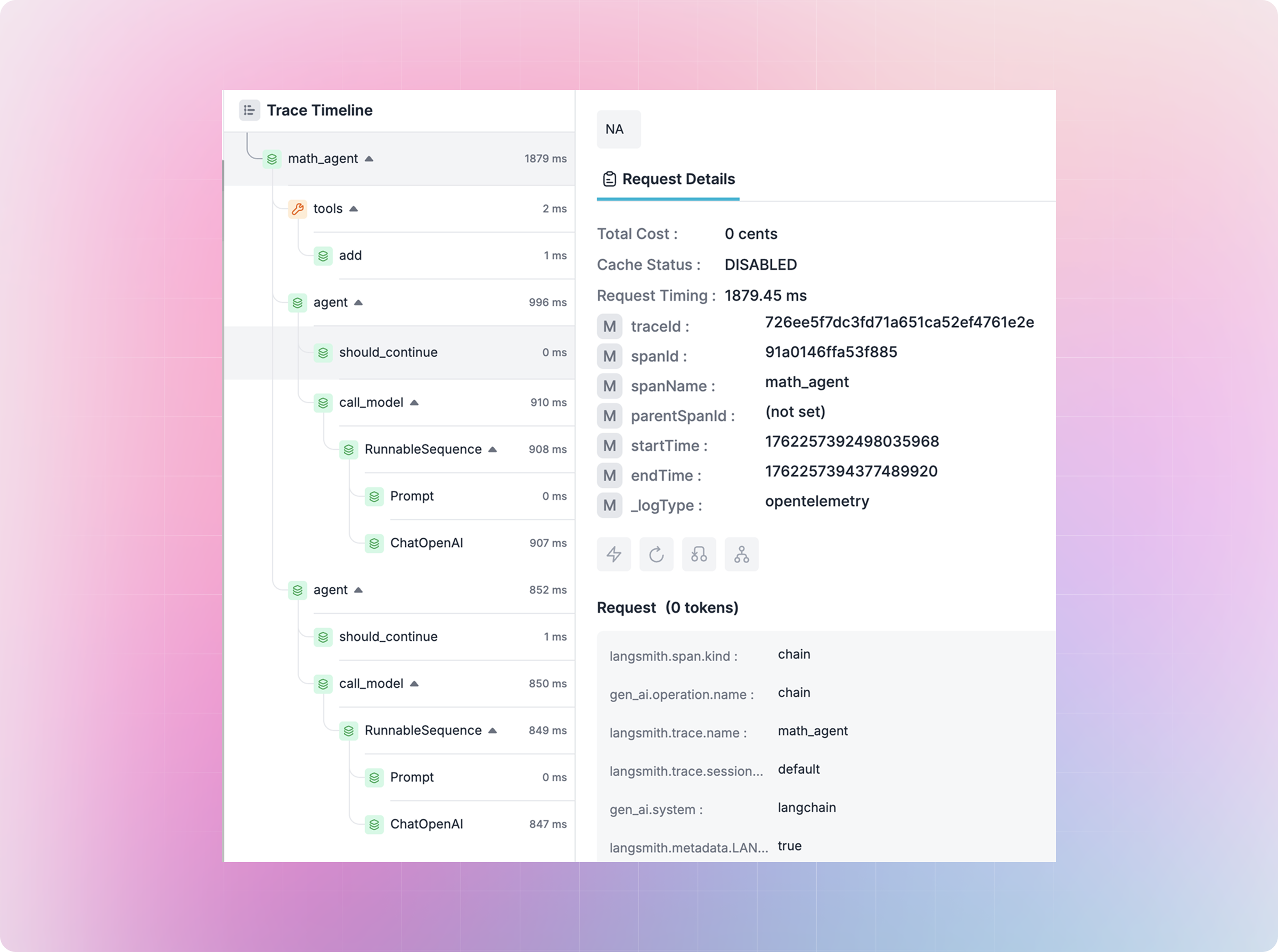
Detailed guardrail checks in logs
See guardrail-flagged events more prominently in logs, simplifying debugging of blocked, redacted, or policy-violating requests.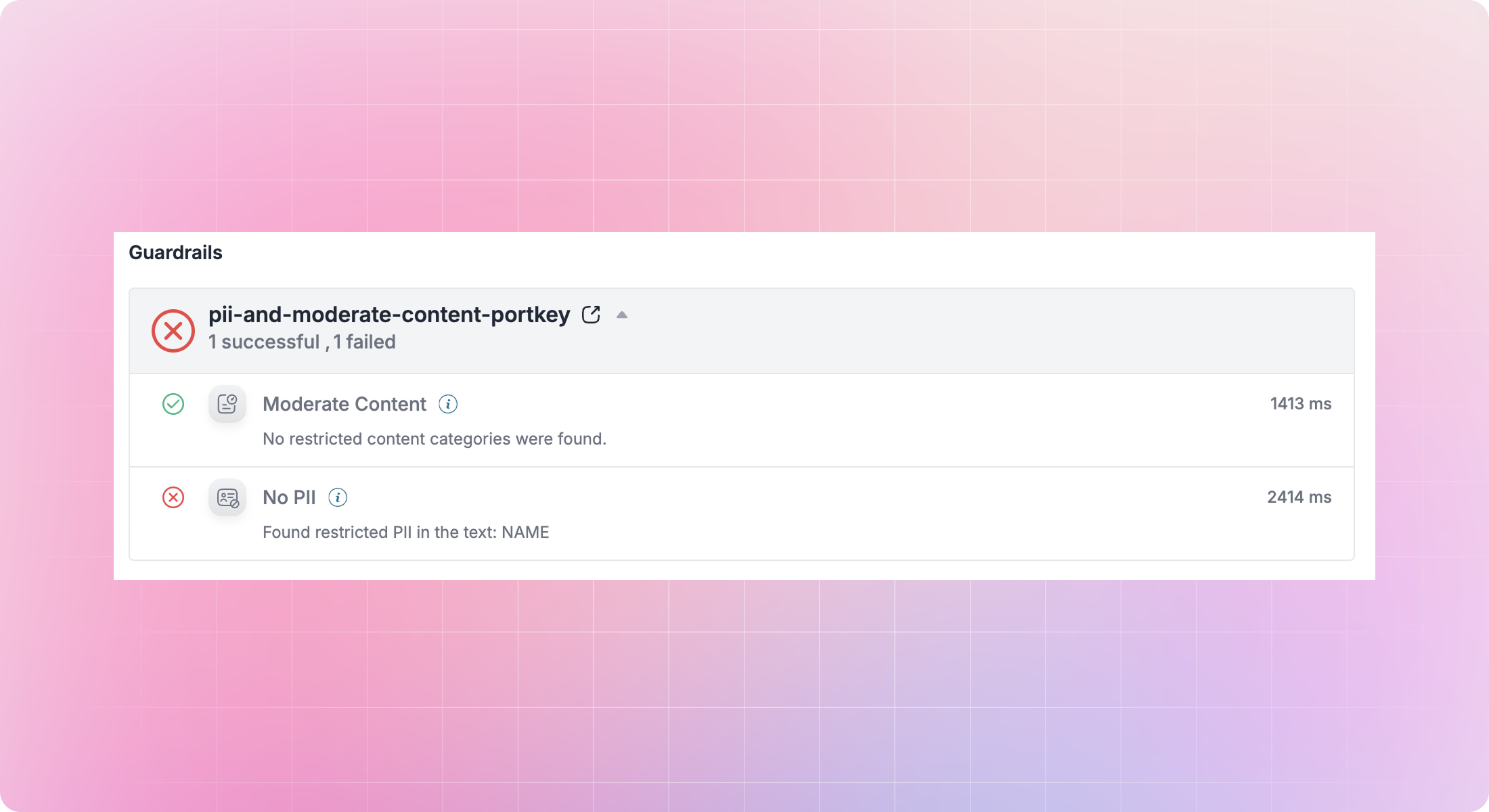
OTel Log Export [Experimental]
You can now export Gateway logs to an OpenTelemetry-compatible endpoint, aligned to experimental GenAI semantic conventions, allowing external systems to ingest AI activity traces. Read more about this here.Guardrails
F5 Guardrail
You can now configure F5 Guardrails, expanding Portkey’s guardrails ecosystem for runtime moderation, safety filtering, and structured response control. This enables additional security layers for production workloads and is especially useful when running automated agent pipelines or public-facing interfaces. See how you can implement F5 Guardrails here.Qualifire Guardrails
Qualifire offers a comprehensive suite of AI safety and quality guardrails designed to keep applications compliant, safe, and high-integrity in production. Their platform provides 20+ guardrail checks spanning content risk, output validation, and policy compliance. See how you can implement Qualifire Guardrails here.Guardrails in streaming responses
Streaming endpoints (/chat/completions, /completions, /embeddings, /messages) can now return guardrail evaluation results in real time.
This helps you to:
- Stop streaming mid-response
- Mask or redact content dynamically
- Enforce content policy on UI without waiting for the full generation
Customer Love!

Gateway
New models & providers
- GPT-5.1: Frontier-grade model now available.
- Gemini 3.0: Google’s latest model with improved reasoning performance.
- Claude Opus 4.5: Anthropic’s strongest reasoning model.
- MatterAI: Reasoning-focused LLM provider with models Axon, Axon Mini, Axon Code.
- Z-AI: Multiple model families with flexible deployment for experimentation, inference, and evaluation
- CometAPI: Enabling high-concurrency access to hundreds of models through a single endpoint.
- Modal Labs: A high-performance serverless platform for model hosting and inference execution.
Model & Provider Enhancements
- Vertex AI: Added support for Computer Use and
anthropic-beta - OpenAI: Added support for
conversation&modalitiesparameters and pricing for Sora models. - Azure OpenAI: Added support for
model-routerand pricing for Sora models. - Azure Foundry: Added support for Anthropic models
- Pricing for gemini-2.5-flash-image, gemini-3-pro-image-preview, Veo and Together AI’s image models
- Pricing for fine-tuning operations across OpenAI, Azure OpenAI, and Vertex AI
Community & Events
Meet us in person at AWS re:Invent!
We’re at AWS re:Invent! If you’d like to meet the founders, discuss platform strategy, or just meet for ☕️ ,grab a 1:1 slot here.3000 Tokens/Sec - Building a high throughput LLM inference engine
We’re hosting a joint session with Cerebras on running high-throughput inference (~3,000 tokens/sec+) in production. 📅 9th December: Join us livePrivate Dinner with AI & Tech Leaders (San Francisco)
We’re hosting a private dinner in San Francisco on 8th December, Monday for AI infra leaders, CTOs, and platform engineers. Expect deep product conversations, real scaling stories, and strong networking energy. Seats are limited, request an invite.Private Dinner for Higher Education and Research (Denver)
We’re also hosting a closed-room education-focused leadership dinner at Denver on 10th December, Wednesday. We’ll be discussing the unique challenges of adopting AI in research and higher-ed settings, including compliance, data privacy, and infrastructure needs. 🎓 Ideal for CIOs and higher-ed AI program leads. Request an inviteResources
- Blog: From standard to ecosystem: the new MCP updates
- Blog: AI tool sprawl: causes, risks, and how teams can regain control
- Blog: The complete guide to LLM observability for 2026
- Blog: AI cost observability: A practical guide to understanding and managing LLM spend
Community Contributors
A special thanks to our contributors this month:jroberts2600 and drorIvry.Support
Need Help?
Open an issue on GitHub
Join Us
Get support in our Discord