Summary
Platform
MCP Gateway (beta)
Enterprises can now bring MCP servers and tools into production with governance, observability, and access controls built-in. The Gateway helps teams avoid authentication sprawl, shadow tool usage, and fragmented monitoring—giving enterprises a central way to manage how agents interact with external tools.- Centralized MCP tool access
- Unified authentication and credentials handling
- Complete visibility into agent-tool interactions
- Access controls and usage limits by team
Unified token counting endpoint
Token counting is now unified across AWS Bedrock, Vertex AI, and Anthropic. With a single endpoint, you can:- Estimate token usage before sending a request (avoid context limit errors)
- Standardize cost/usage logic across providers
- Enforce routing and quota rules directly inside your app

Guardrails
Metadata-based Model Access guardrail

Regex-replace guardrail
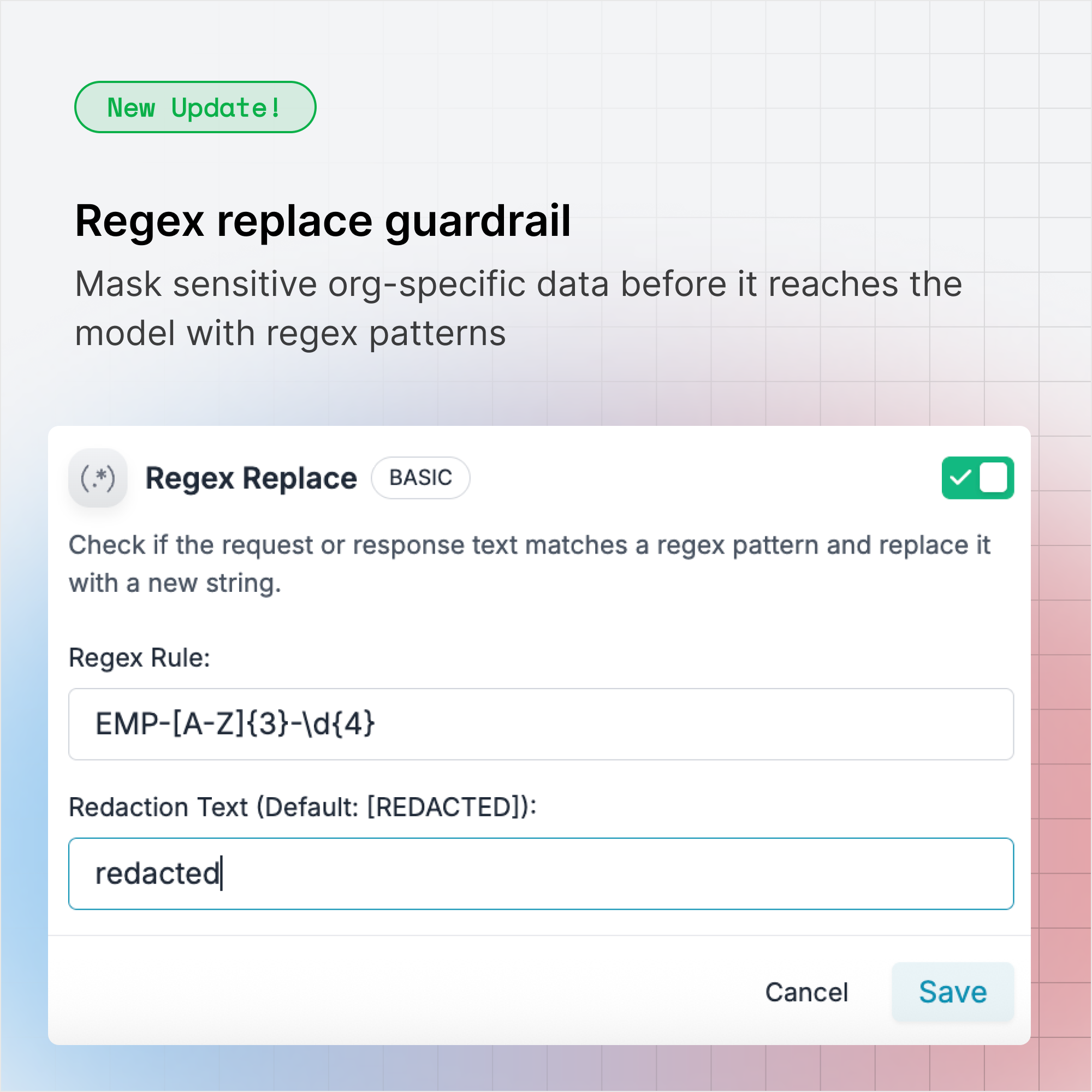
- Define your own regex patterns
- Replace matches with a chosen string (e.g., [masked_user])
- Enforce masking rules at runtime, before data reaches the model
Gateway and Providers
Unified finish_reason parameter
We standardized the finish_reason field across all providers. By default, values are mapped to OpenAI-compatible outputs, ensuring consistent handling across multi-provider deployments.
If you prefer to keep the original provider-returned value, set x-portkey-strict-openai-compliance = false.
Conditional router enhancement
Conditional routing now supports parameter-based routing in addition to metadata. Parameter-based routing enables dynamic, per-request optimizations, giving you better performance, cost efficiency, and control over user experience. Read more about this hereGateway and Providers
New Models
Claude Sonnet 4.5
Anthropic’s latest model, now available via Portkey
GPT-5 Codex
OpenAI’s specialized coding model, supported with full observability
New Providers
Meshy
Specialized 3D generation and design workflows provider
Tripo3D
Next-generation 3D modeling and visualization
Cerebras
High-performance AI inference provider offering up to 70x faster speeds than GPU-based solutions
Nextbit256
New provider focused on efficient inference for specialized workloads
Improvements and Fixes
- DashScope → Updated supported parameters
-
Vertex AI:
- Added
timeRangeFiltersupport for Google Search tool - Added support for Mistral models
- Added support for
task_typeanddimensionsparameters in Vertex AI batch embeddings - Handle empty responses returned by the provider
- Support for
globalregion
- Added
- Fireworks → Better handling of non-ASCII characters in file uploads, plus removed unnecessary response transforms for faster performance
-
OpenAI & Azure OpenAI:
- Added new parameters for GPT-5 compatibility
- Updated the tokenizer to support streaming request token calculation for latest gpt-5 models
-
AWS Bedrock:
- Added
videosupport in chat completions - Added support for
APACcross region inference profiles - Added support for
performance_configparameter which will be passed as-is to the provider asperformanceConfigparameter - Support Inference Profiles when uploading files for batches & finetuning
- KMS Support for file uploads to AWS
- Added
- Azure Foundry and Github → Updated the parameter mapping to support all the latest OpenAI compatible chat completions parameters
- Adding new models to Azure OpenAI → Now much simpler. You just need to add the target URI, and the model will be fetched and added directly to your integration.
- Azure Foundry → You can now enable multiple models in a single Azure Foundry integration. This simplifies management and makes it easier to experiment with different models under the same integration, without repetitive setup.
- Support custom scope for entra auth to use with deprecated azure serverless models
- Custom Header support for OTel Export of analytics data
Community & Events
Protecting your AI platform with Palo Alto Networks and Portkey
LLMs in Prod, San Francisco
PG&E Immersion Day
We had the privilege of joining Pacfic Gas & Electricity for their internal Immersion Day. It was a hands-on session with their teams, exploring how enterprises can adopt AI responsibly and scale across critical operations.Syngenta Devcon 2025
Our customer Syngenta hosted Devcon 2025, centered on AI.
MCP Salon
We hosted some of the most illustrious MCP builders for a closed-door roundtable. The group went deep into the technical challenges of building MCP servers and clients, serving them in production, and solving real-world adoption hurdles. 👉 To stay updated on upcoming events, subscribe to our event calendarResources
- Blog: MCP Message Types: Complete MCP JSON-RPC Reference Guide
- Blog: Failover routing strategies for LLMs in production
- Partnership Blog with Feedback Intelligence: Tracing Failures from the LLM Call to the User Experience
- Blog: A Strategic Perspective on the MCP Registry for the Enterprise
Community Contributors
A special thanks to our contributor this month:Coming this month!
Webinar - LibreChat in Production Register here →Support
Need Help?
Open an issue on GitHub
Join Us
Get support in our Discord