What are vision models?Vision models are artificial intelligence systems that combine both vision and language modalities to process images and natural language text. These models are typically trained on large image and text datasets with different structures based on the pre-training objective.
Vision Chat Completion Usage
Portkey supports the OpenAI signature to define messages with images as part of the API request. Images are made available to the model in two main ways: by passing a link to the image or by passing the base64 encoded image directly in the request. Here’s an example using OpenAI’sgpt-4o model
- NodeJS
- Python
- OpenAI NodeJS
- OpenAI Python
- cURL
API Reference
On completion, the request will get logged in the logs UI where any image inputs or outputs can be viewed. Portkey will automatically load the image URLs or the base64 images making for a great debugging experience with vision models.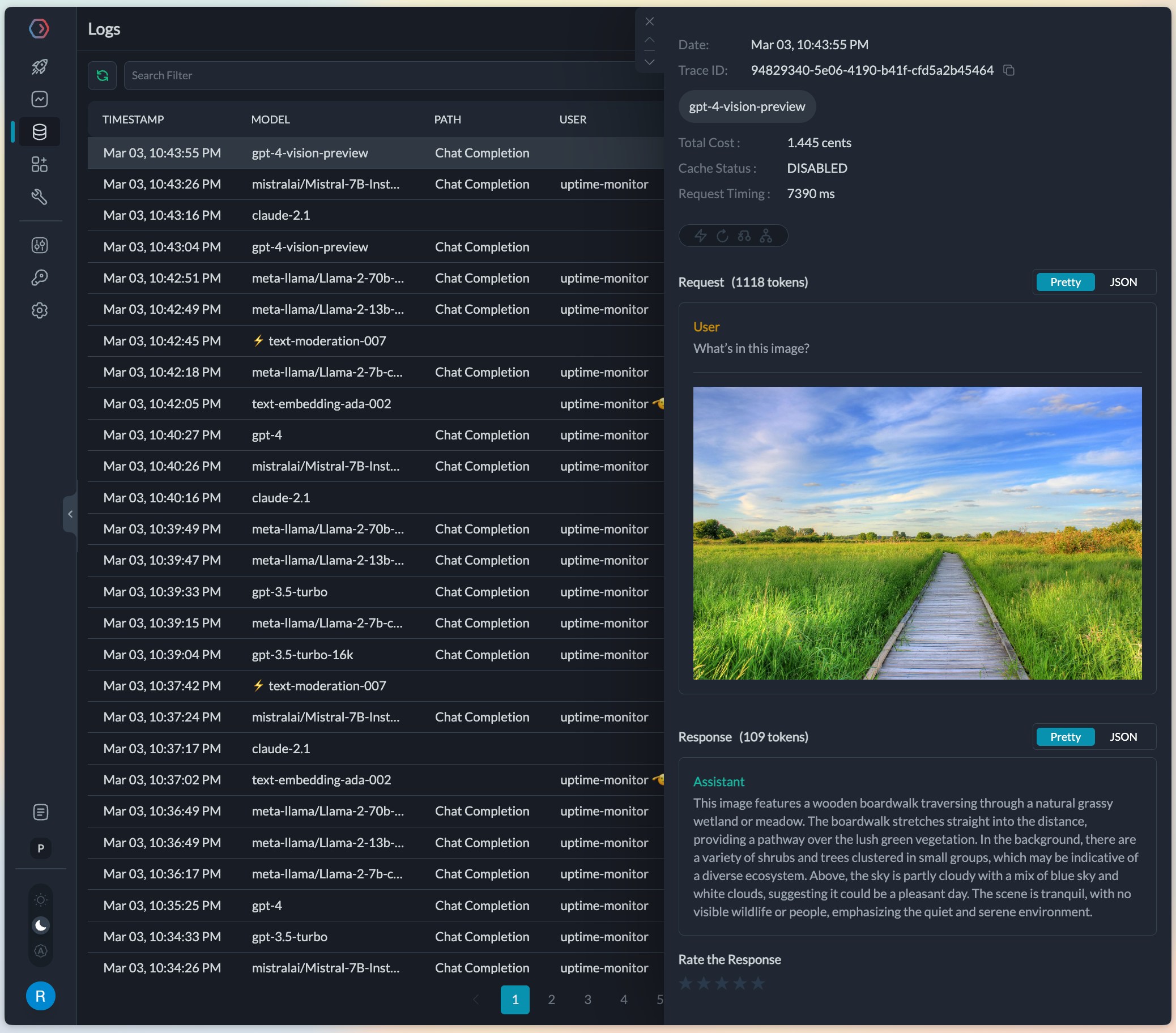
Creating prompt templates for vision models
Portkey’s prompt library supports creating templates with image inputs. If the same image will be used in all prompt calls, you can save it as part of the template’s image URL itself. Or, if the image will be sent via the API as a variable, add a variable to the image link.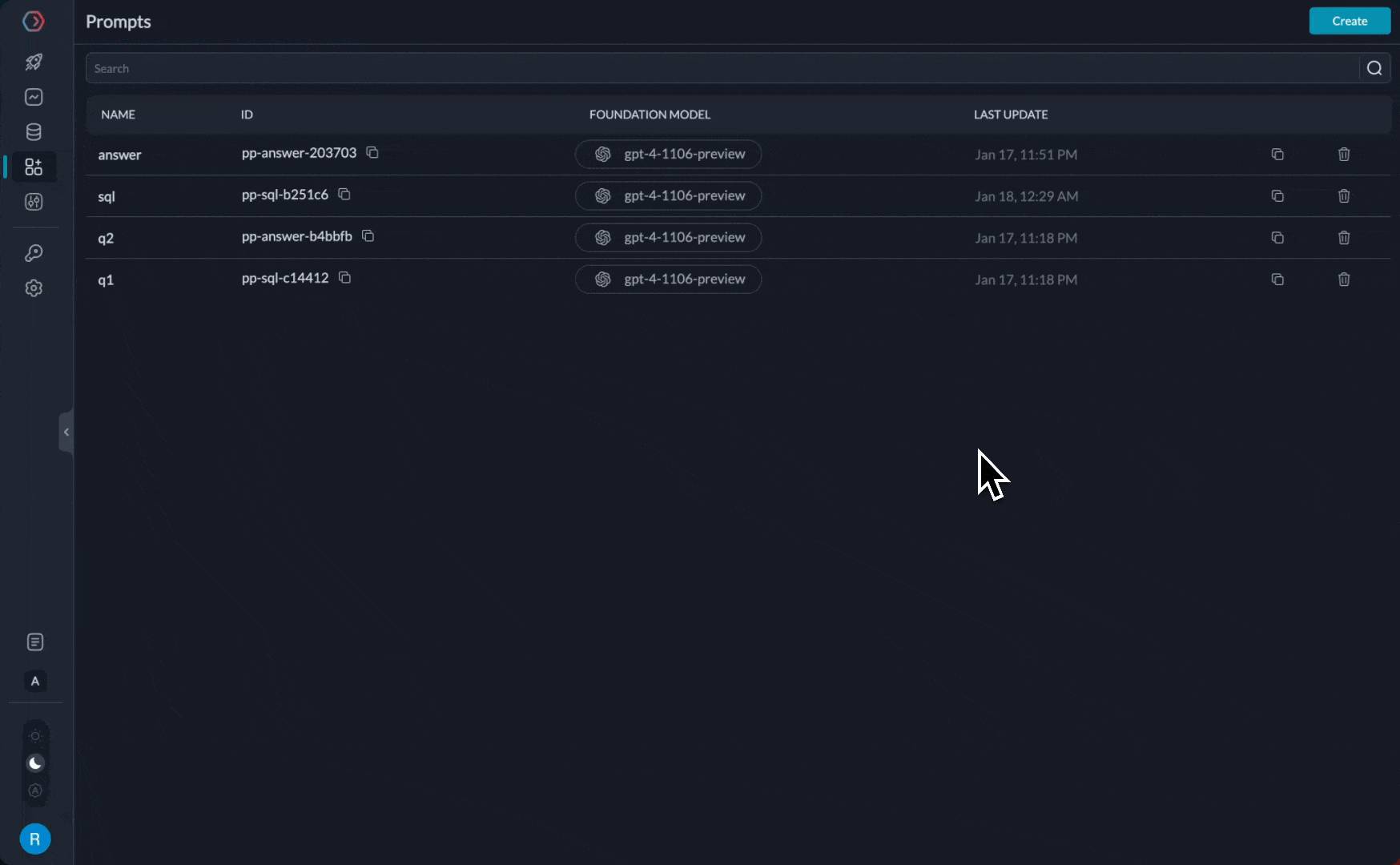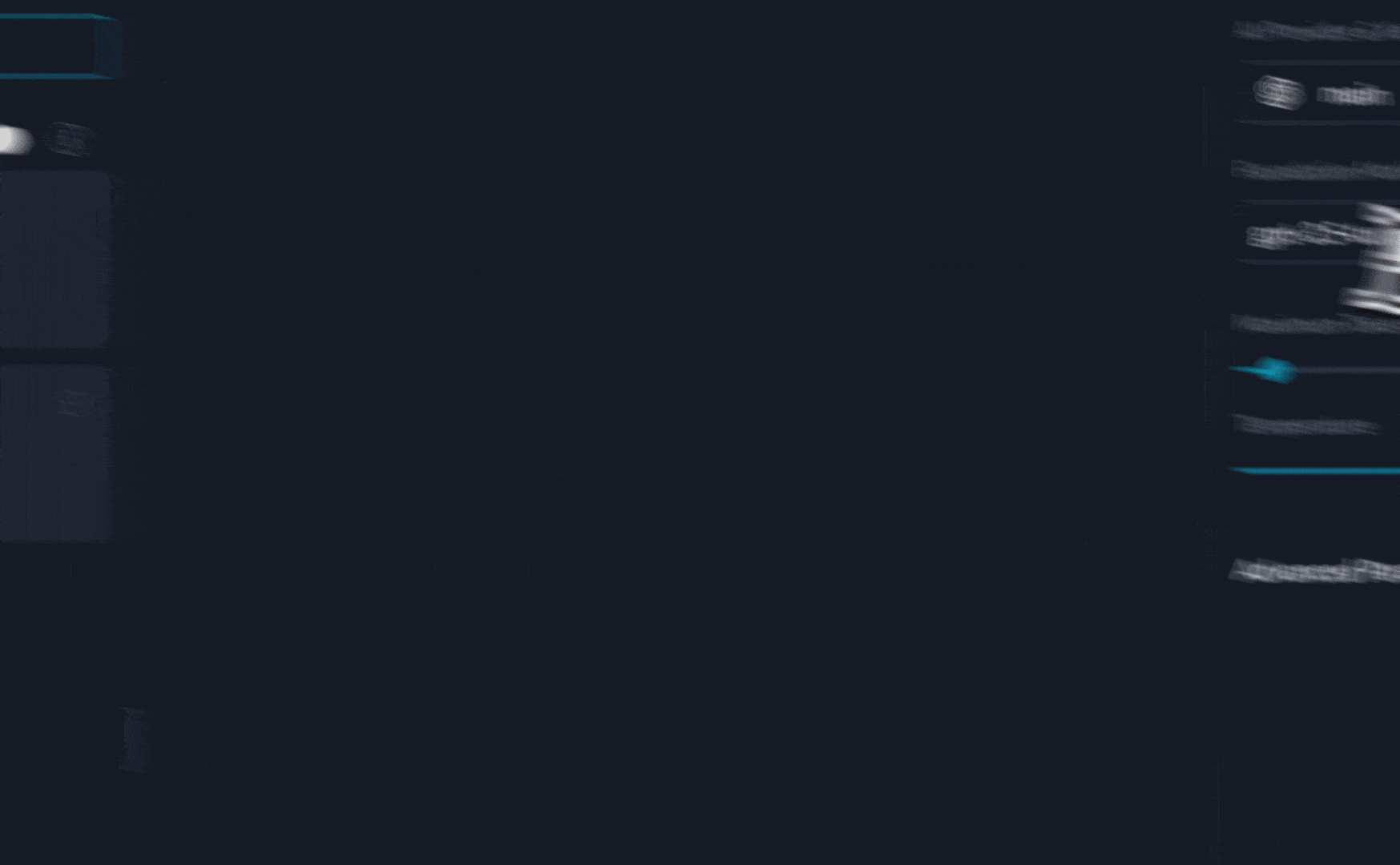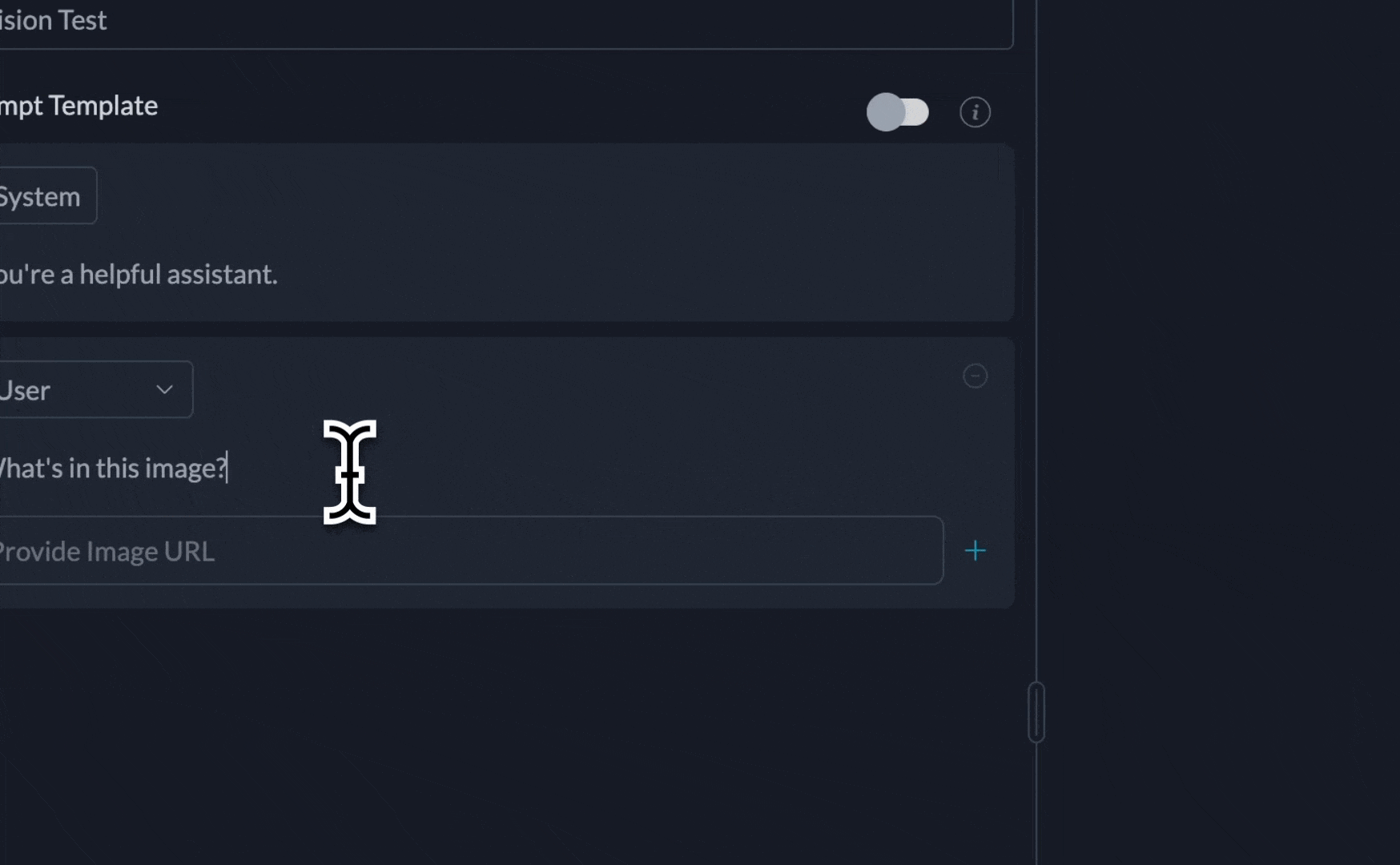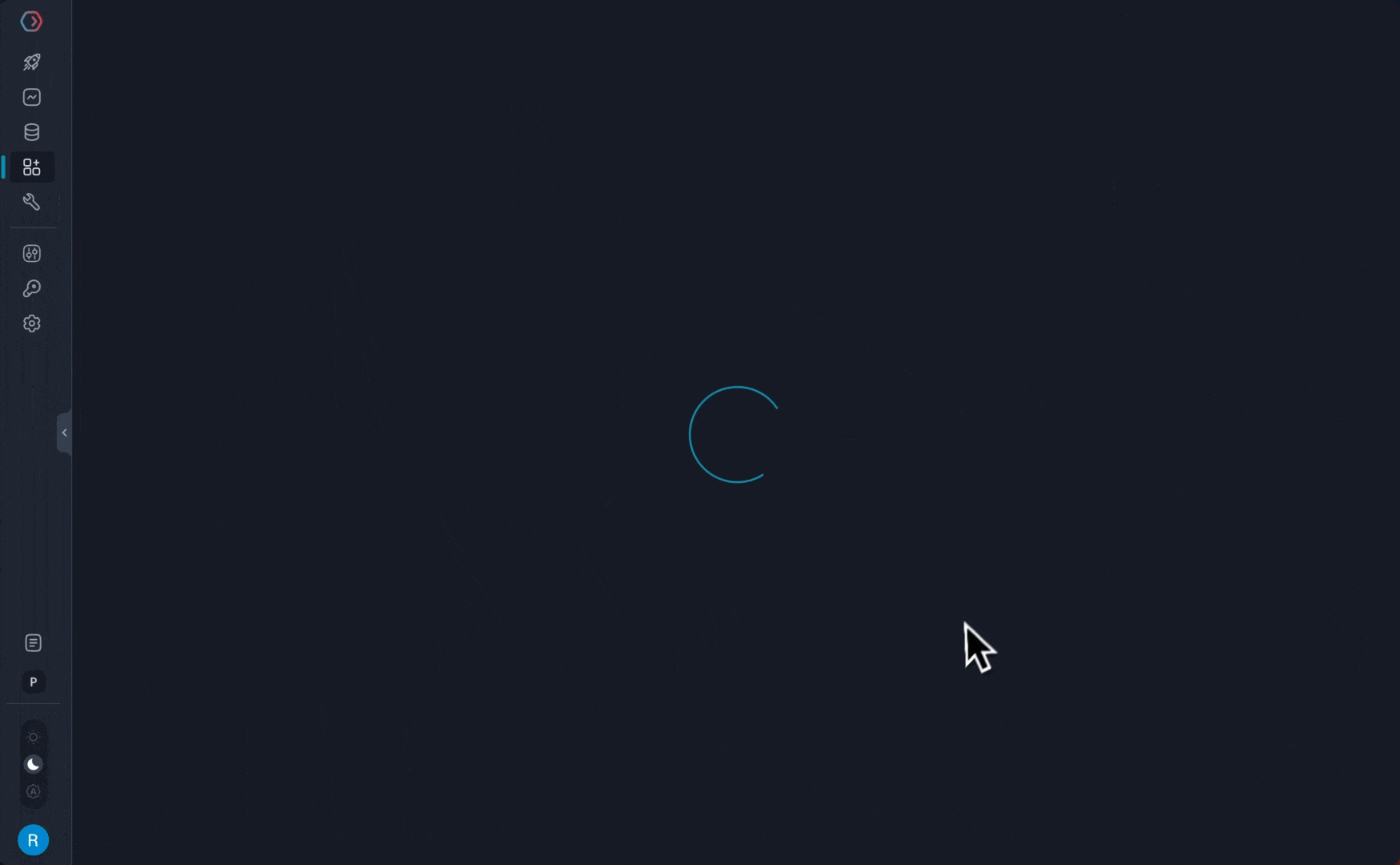
Supported Providers and Models
Portkey supports all vision models from its integrated providers as they become available. The table below shows some examples of supported vision models. Please raise a request or a PR to add a provider to the AI gateway.
For a complete list of all supported provider (including non-vision LLMs), check out our providers documentation.