Before reading this guide: We recommend checking out Hamel Husain’s excellent post on LLM-as-a-Judge. This cookbook implements the principles discussed in Hamel’s post, providing a practical walkthrough of building LLM-as-a-judge evaluation .
Introduction
AI-powered customer support agents are great, but how do you ensure they provide high-quality responses at scale? You need a system that can automatically evaluate customer support interactions by analyzing both the customer’s query and the AI agent’s response. This system should determine whether the response meets quality standards, provide a detailed critique explaining the reasoning behind the judgment, and scale easily to run tests on thousands of interactions. Quality assurance for customer support interactions is critical but increasingly challenging as AI Agents handle more customer conversations. Manual reviews are great but they don’t scale. The “LLM-as-a-Judge” approach offers a powerful solution to this challenge. This guide will show you how to build an automated evaluation system that scales to thousands of interactions. By the end, you’ll have a robust workflow that helps you improve AI agents responses.What We’re Building
We’ll create an LLM as a judge workflow that evaluates customer support interactions by analyzing both the customer’s query and the AI agent’s response. For each interaction, our system will:- Determine whether the response meets quality standards (pass/fail)
- Provide a detailed critique explaining the reasoning behind the judgment
- Scale easily to run tests on thousands of interactions
- Ensuring consistent quality across all AI responses
- Identifying patterns of problematic responses
- Maintaining security and compliance standards
- Quickly detecting when the AI is providing incorrect information
- Get specific feedback on why responses fail to meet standards
- Identify trends and systematic issues in your support system
- Provide targeted training and improvements based on detailed critiques
- Quickly validate whether changes to your AI agent have improved response quality
System Architecture: How It Works
Industry Best Practices for AI Agent Evaluation Before diving into implementation, let’s briefly look at evaluation approaches for customer support AI:- Human Evaluation: The gold standard, but doesn’t scale
- Offline Benchmarking: Testing against curated datasets with known answers
- Online Evaluation: Monitoring live interactions and collecting user feedback
- Multi-dimensional Scoring: Evaluating across different attributes (accuracy, helpfulness, tone)
- LLM-as-a-Judge: Using a powerful model to simulate expert human judgment
Working with Portkey’s Prompt Studio
We will be using Prompt Studio in this cookbook. Unlike traditional approaches where prompts are written directly in code, Portkey allows you to:- Create and manage prompts through an intuitive UI
- Version control your prompts
- Access prompts via simple API calls
- Deploy prompts to different environments
{{variable}} in our prompts, which allows for dynamic content insertion. This makes our prompts more flexible and reusable.
What are Prompt Partials?
Prompt partials are reusable components in Portkey that let you modularize parts of your prompts. Think of them like building blocks that can be combined to create complex prompts. In this guide, we’ll create several partials (company info, guidelines, examples) and then combine them in a main prompt.
To follow this guide, you will need to create prompt partials first, then create the main template in the Portkey UI, and finally access them using the prompt_id inside your codebase.
Step-by-Step Guide to Building LLM-as-a-Judge
The Judge Prompt Structure To build an effective LLM judge, we need to create a well-structured prompt that gives the model all the context it needs to make accurate evaluations. Our judge prompt will consist of four main components:- Company Information - Details about your company, products, and support policies that help the judge understand the context of customer interactions
- Evaluation Guidelines - Specific criteria for what makes a good or bad response in your customer support context
- Golden Examples - Sample evaluations that demonstrate how to apply the guidelines to real iteractions
- Main Judge Template - This brings everything together and creates the Judgement System
Step 1: Define Your Company Information in a Partial
First, we’ll create a partial that provides context about your company, products, and support policies. This helps the judge evaluate responses in the proper context.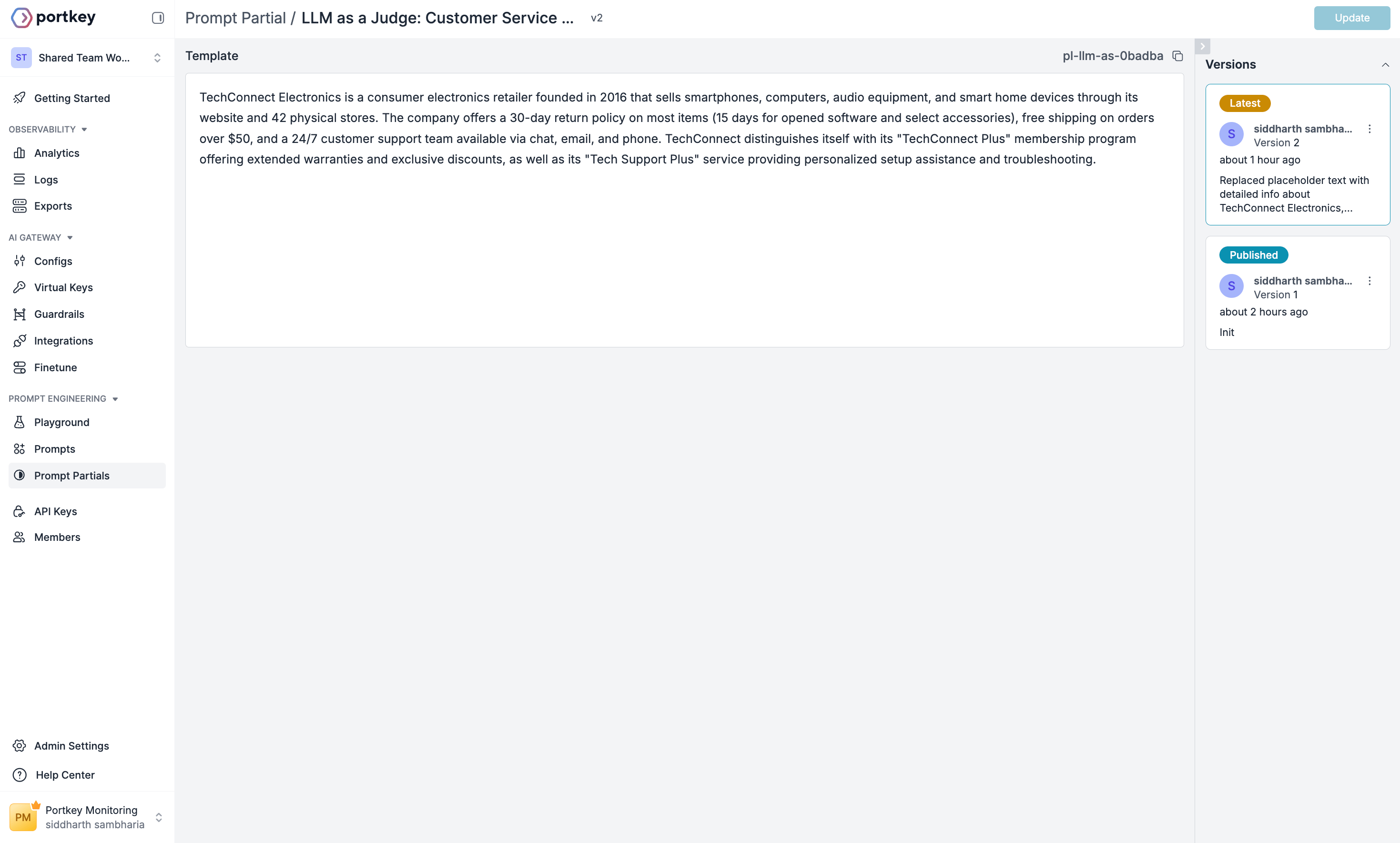
Company Info Prompt Partial
Company Info Prompt Partial
TechConnect Electronics is a consumer electronics retailer founded in 2016 that sells smartphones, computers, audio equipment, and smart home devices through its website and 42 physical stores. The company offers a 30-day return policy on most items (15 days for opened software and select accessories), free shipping on orders over $50, and a 24/7 customer support team available via chat, email, and phone. TechConnect distinguishes itself with its “TechConnect Plus” membership program offering extended warranties and exclusive discounts, as well as its “Tech Support Plus” service providing personalized setup assistance and troubleshooting.
pl-llm-as-0badba) that you’ll reference in your main prompt template.
Step 2: Define the Evaluation Guidelines Partial
Next, create a partial that defines the criteria for evaluating responses. This ensures consistent quality standards.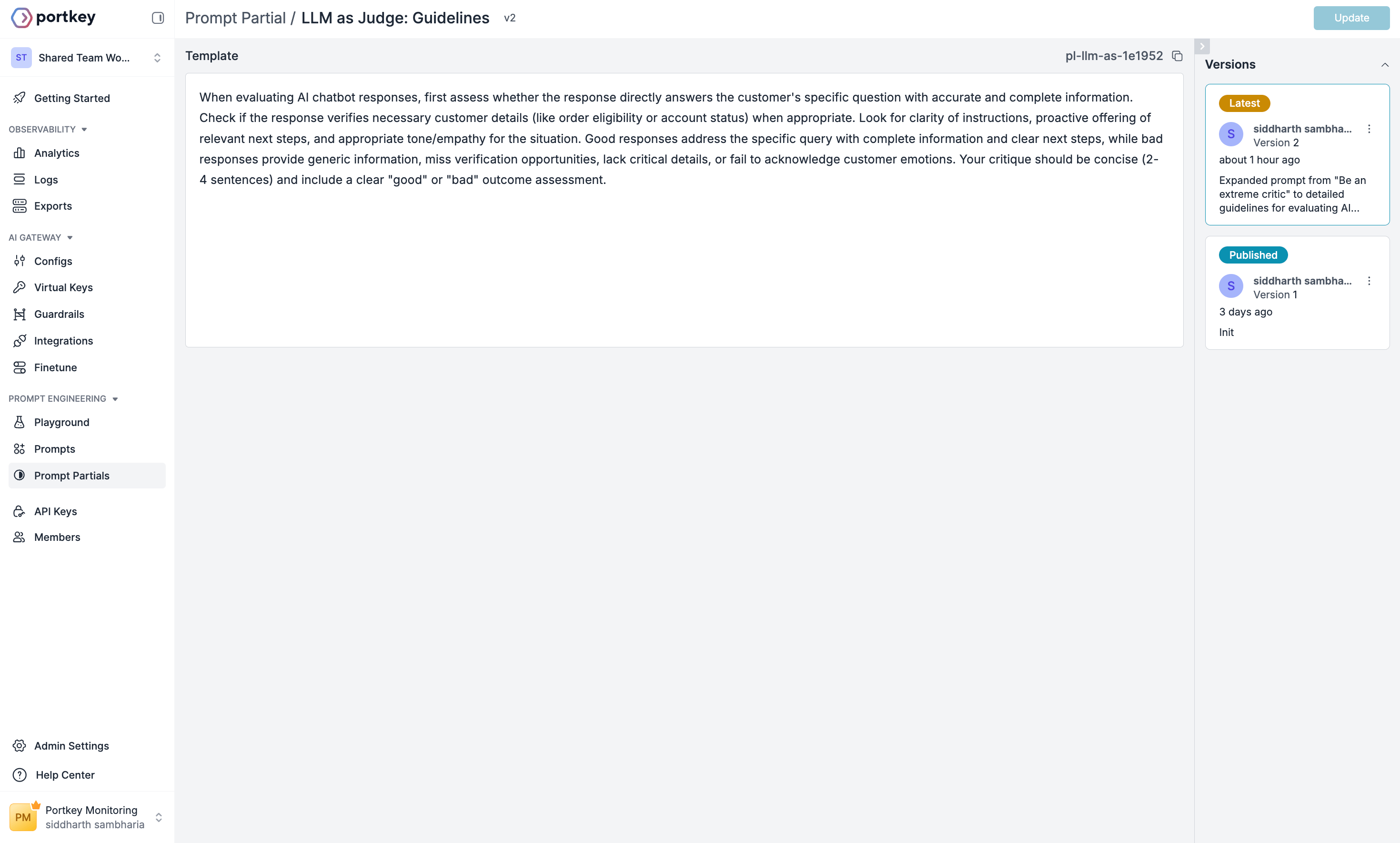
Judge Guidelines Partial Prompt
Judge Guidelines Partial Prompt
When evaluating AI chatbot responses, first assess whether the response directly answers the customer’s specific question with accurate and complete information. Check if the response verifies necessary customer details (like order eligibility or account status) when appropriate. Look for clarity of instructions, proactive offering of relevant next steps, and appropriate tone/empathy for the situation. Good responses address the specific query with complete information and clear next steps, while bad responses provide generic information, miss verification opportunities, lack critical details, or fail to acknowledge customer emotions. Your critique should be concise (2-4 sentences) and include a clear “good” or “bad” outcome assessment.
pl-llm-as-1e1952) to reference in your main template.
Step 3: Create Golden Examples Partial
Now create a partial with example evaluations. These examples “teach” the LLM what good and bad responses look like in your specific context.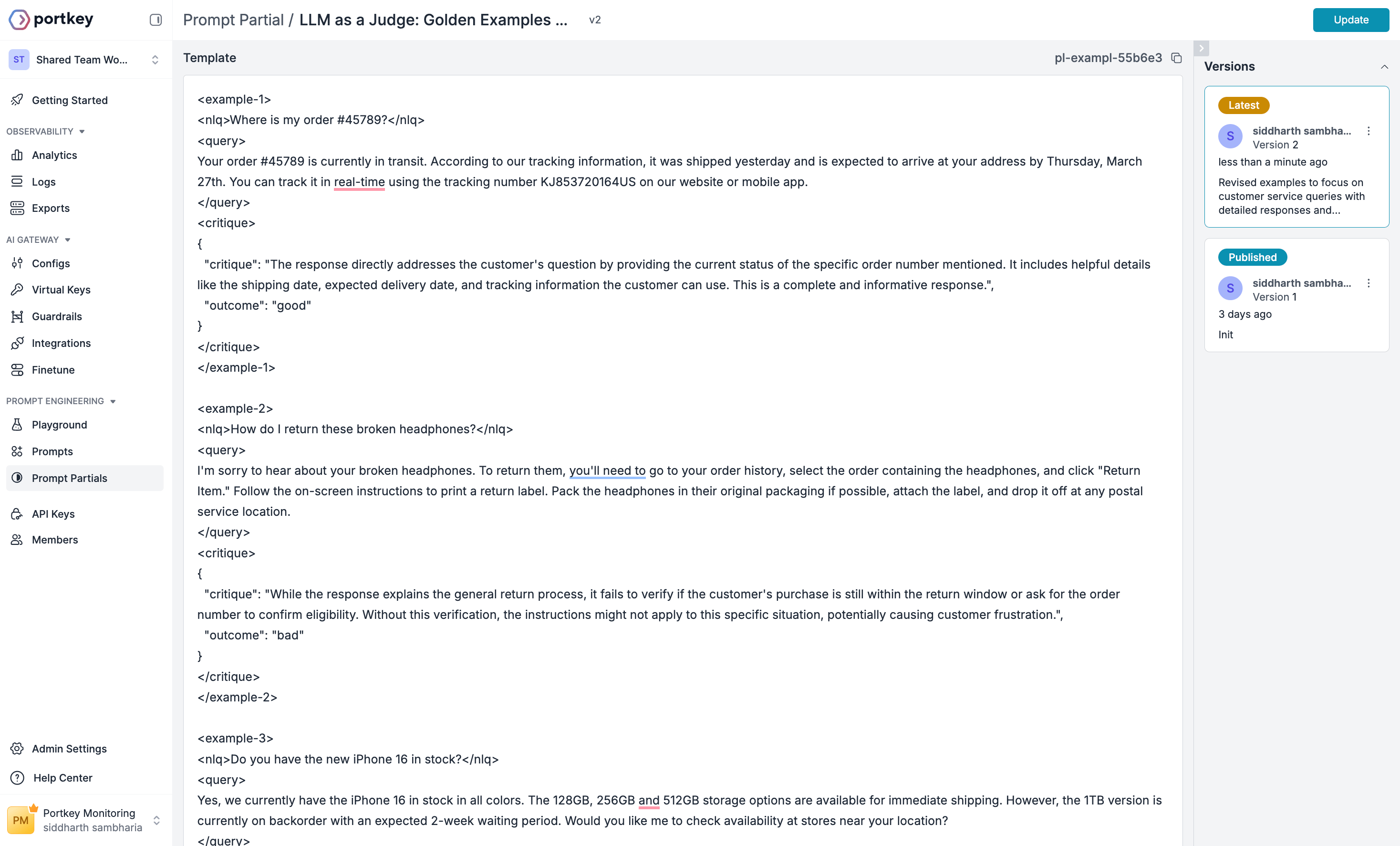
Golden Example Partial Prompt
Golden Example Partial Prompt
- Include diverse scenarios covering different types of customer questions
- Show the reasoning process by explaining why an answer is good or bad
- Include both good and bad examples
- Match your actual use cases with examples that reflect your real customer interactions
- Be consistent with the format structure
pl-exampl-55b6e3) to reference in your main template.
Step 4: Create the Main Judge Prompt Template
Now that you have all the partials, it’s time to create the main judge prompt template that brings everything together. We will reference the partials we created earlier to provide context, guidelines, and examples to the judge using mustache variables.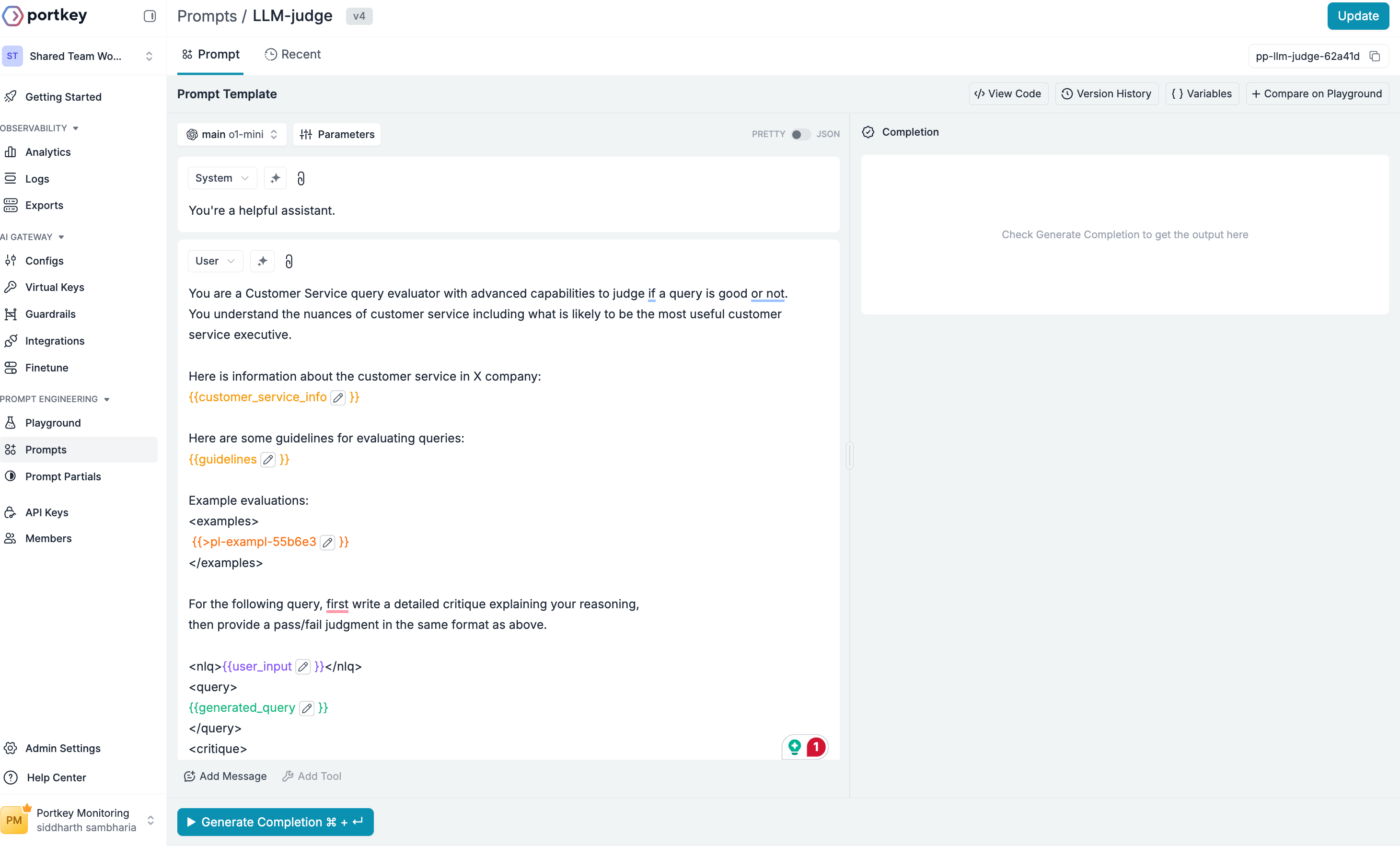
Main LLM as a Judge Prompt
Main LLM as a Judge Prompt
System
User
Some LLMs don’t support strcutured output generation. In those cases you should use LLMs function calling ability to generate JSON output.
Tool Calling Supported LLM
Tool Calling Supported LLM
If your LLM does not support Structure Outputs, you will have to add this tool in your prompt template along with the prompt above.Choose
Tool Choice = Required in your prompt template.Step 5: Implementing the Evaluation Code with Structured Output
Now that you have your prompt template set up in Portkey, use this Python code to evaluate customer support interactinos. You can use either of the following ways to go ahead with this cookbook, depending upon what your LLM supports:- Structured Output
- Tool Calling Supported LLM
Example Output
Example Output
Example output:
Step 6: Iterate with Domain Experts
The most important part of building an effective LLM-as-a-Judge is iterating on your prompt with feedback from domain experts:- Create a small test dataset with 20-30 representative customer support interactions
- Have human experts evaluate these interactions using the same criteria
- Compare the LLM judge results with human expert evaluations
- Calculate agreement rate and identify patterns in disagreements
- Update your prompt based on what you learn
Portkey Observability for Continuous Improvement
Visualizing Evaluation Results on the Portkey Dashboard
The feedback data we collect using theportkey.feedback.create() method automatically appears in the Portkey dashboard, allowing you to:
- Track evaluation outcomes over time
- Identify specific areas where your agent consistently struggles
- Measure improvement after making changes to your AI agent
- Share results with stakeholders through customizable reports
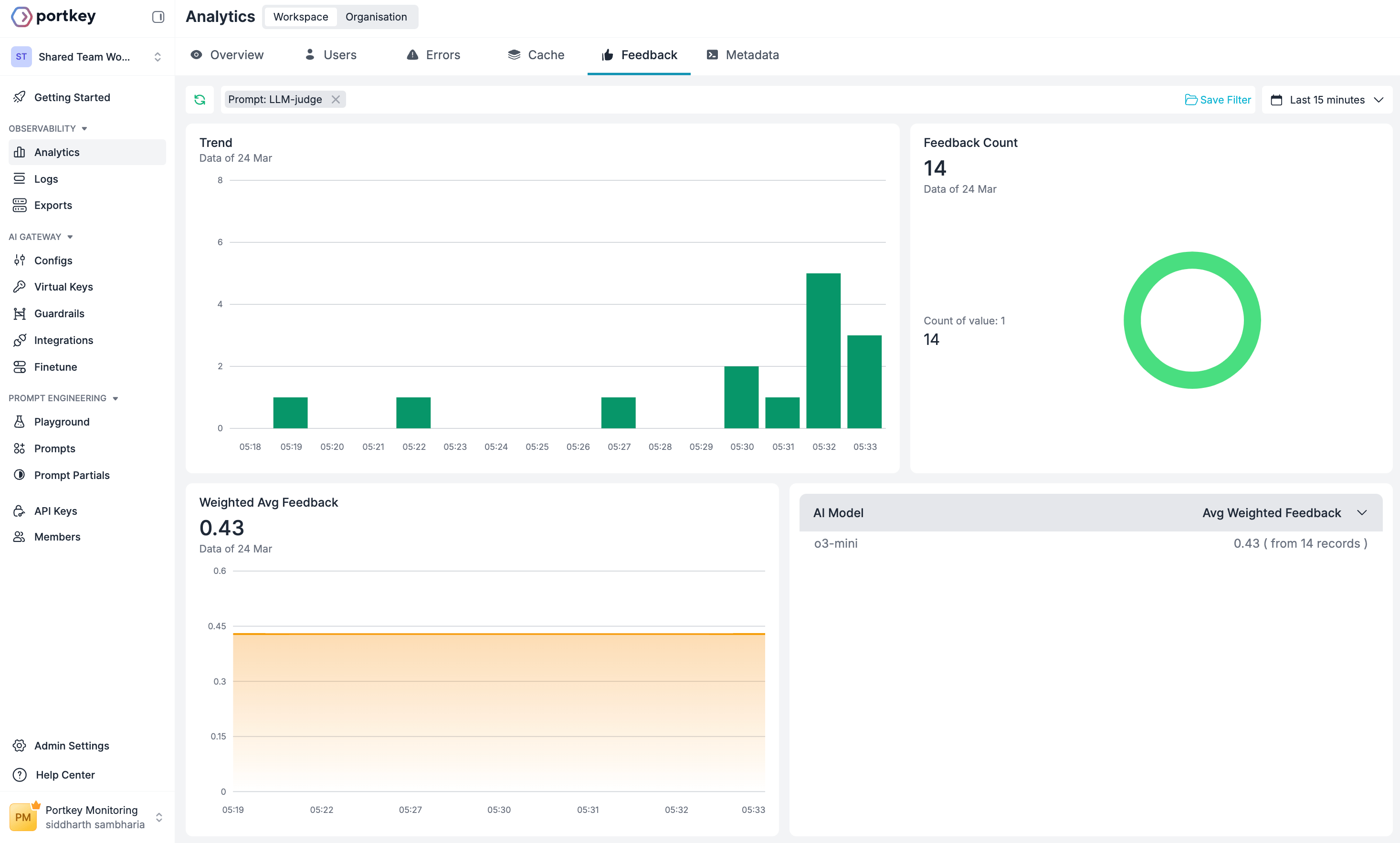
Running Evaluation on Scale
Running evaluation on scale
Running evaluation on scale
Next Steps
After implementing your LLM-as-a-Judge system, here are key ways to leverage it:- Analyze quality trends: Track pass rates over time to measure improvement
- Identify systematic issues: Look for patterns in failing responses to address root causes
- Improve your support AI: Use the detailed critiques to refine your support system