Enable real-time internet search capabilities for any LLM in LibreChat using Portkey’s Exa integrationTransform your LibreChat experience by adding web search capabilities to any LLM - whether it’s GPT-5, Claude, Llama, or any of the 1,600+ models supported by Portkey. This guide shows you how to combine LibreChat, Portkey, and Exa to create a powerful AI chat interface with real-time internet access.
This integration builds upon the basic LibreChat + Portkey setup. Please complete that integration first before proceeding.
What You’ll Get
By following this guide, your LibreChat installation will have:- ✅ Web search for any LLM - Not just OpenAI’s browsing models
- ✅ Real-time information - Access to current events, latest data, and up-to-date facts
- ✅ All Portkey features - Observability, caching, fallbacks, and more
- ✅ Unified interface - One LibreChat setup for all your AI needs
- ✅ 1,600+ LLM support - Use web search with any model through Portkey
How It Works
1
User asks a question in LibreChat
When you send a message requiring current information
2
Request routes through Portkey
Portkey intercepts the request and triggers the Exa plugin
3
Exa searches the web
Relevant search results are fetched from across the internet
4
Context enhancement
Search results are added to your prompt as additional context
5
LLM responds with current information
Your chosen LLM now has access to real-time data to answer accurately
Prerequisites
Before starting, ensure you have:- ✅ LibreChat installed and running
- ✅ Basic Portkey + LibreChat integration completed
- ✅ Portkey account with API key
- ✅ Exa account with API key
Setup Guide
Step 1: Enable Exa Plugin in Portkey
First, activate the Exa plugin in your Portkey account:- Log into your Portkey dashboard
- Navigate to
Settings→Pluginsin the sidebar - Find Exa in the list of available plugins
- Click Enable and enter your Exa API key
- Save your settings
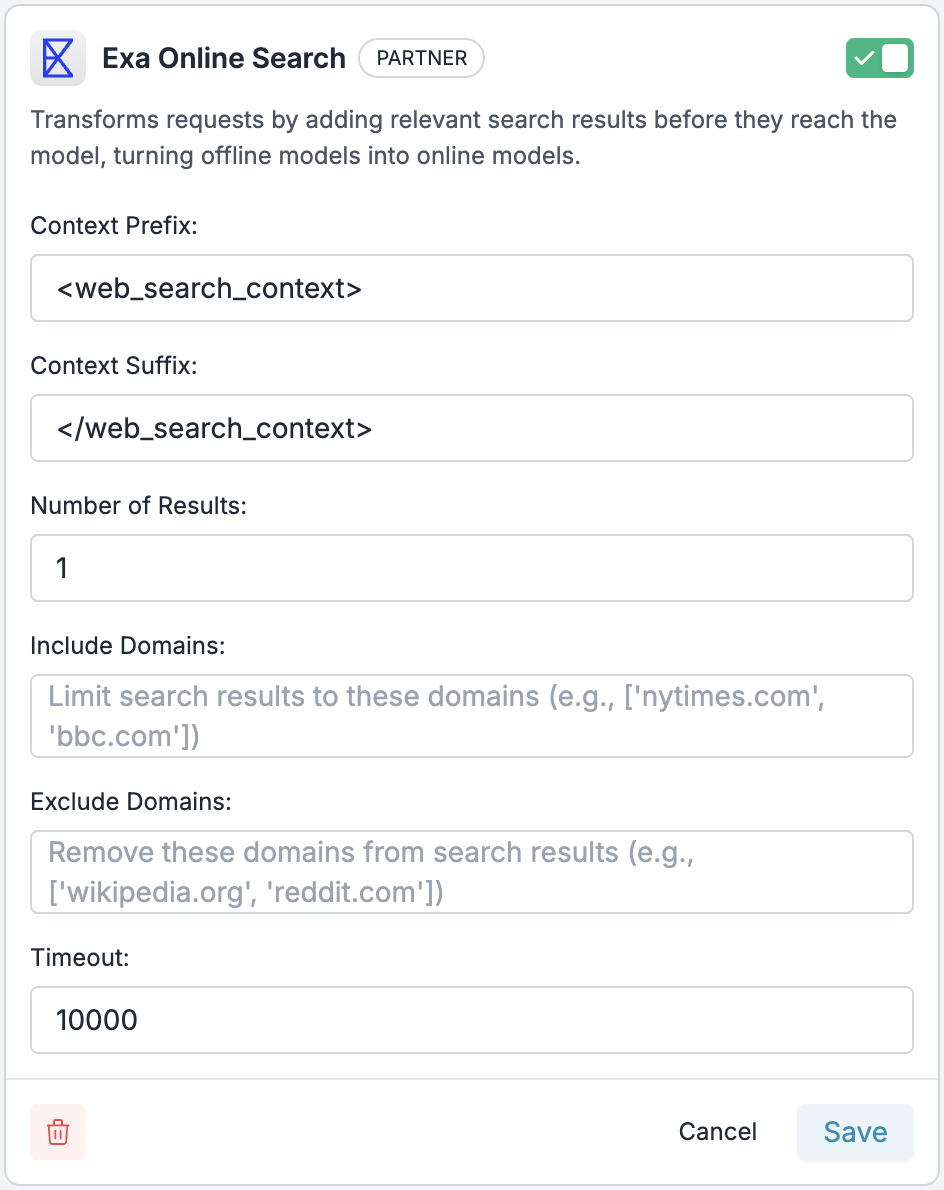
Step 2: Create an Exa Guardrail
Next, create a guardrail that will add web search to your requests:- Go to the
Guardrailspage in Portkey - Click
Create New Guardrail - Search for “Exa Online Search” and click
Add - Configure the following parameters:
Recommended Settings:
- Number of Results: 3-5 (balances information vs token usage)
- Timeout: 10000ms (10 seconds)
- Include/Exclude Domains: Leave empty for general use, or specify trusted sources
- Set the action to
passthrough(default) - Save the guardrail and copy the Guardrail ID
Step 3: Create a Config with Web Search
Now create a Portkey config that includes your Exa guardrail:- Navigate to
Configsin the Portkey dashboard - Click
Create New Config - Add your configuration:
Config
- Save the config and note the Config ID (e.g.,
pc-websearch-xxx)
Step 4: Update Your LibreChat Configuration
Finally, update your LibreChat setup to use the web-search enabled config:- Edit your
librechat.yamlfile:
librechat.yaml
- Restart your LibreChat instance
Step 5: Test Your Setup
- Open LibreChat in your browser
- Select “Portkey with Web Search” as your endpoint
- Try asking questions that require current information:
Advanced Configuration
Domain Filtering
For specialized use cases, you can limit search results to specific domains:Config
- Include Domains:
["arxiv.org", "nature.com", "pubmed.ncbi.nlm.nih.gov"](for academic research) - Exclude Domains:
["reddit.com", "twitter.com"](to avoid social media)
Multiple Configurations
Create different configs for different use cases:librechat.yaml
Combining with Other Portkey Features
Enhance your web-search enabled config with additional Portkey features:Config
Monitoring Web Search Usage
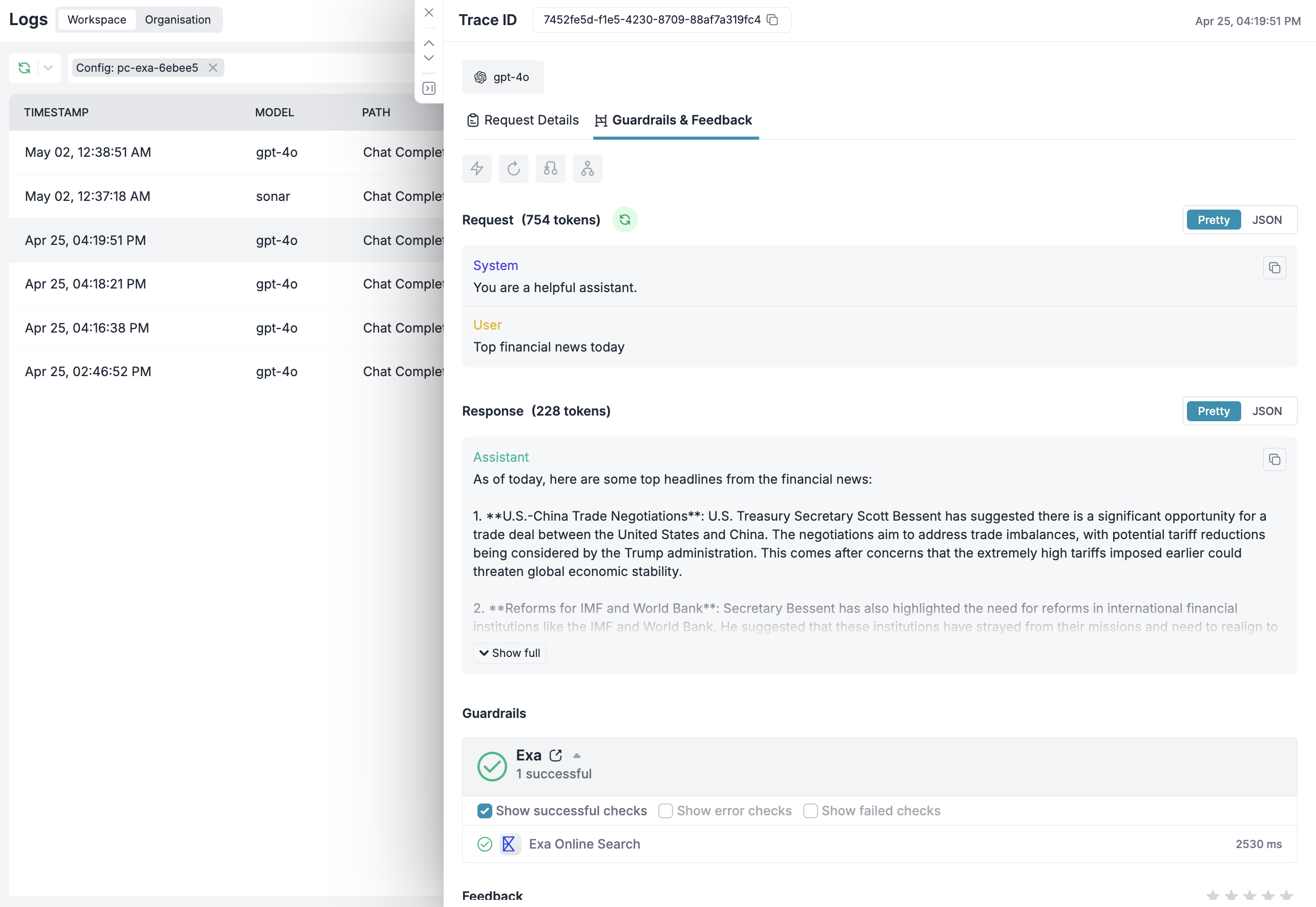
Track your web-search enhanced conversations in the Portkey dashboard:- Navigate to Logs in Portkey
- Filter by config ID to see web-search requests
- Click on individual logs to see:
- The original user query
- Web search results added as context
- Token usage (including search context)
- Response time and costs
Best Practices
Token Management
Monitor token usage as web search adds context. Adjust the number of search results based on your needs and budget.
Model Selection
Some models handle web context better than others. Test different models to find the best fit for your use case.
Query Optimization
Not every query needs web search. Consider creating separate endpoints for general chat vs. current information needs.
Caching Strategy
Use semantic caching for frequently asked current events questions to reduce API calls and costs.
Next Steps
- Try different models with web search to compare performance
- Monitor costs using Portkey’s analytics dashboard
- Create specialized configs for your team’s specific use cases
- Set up access controls with user-specific API keys