Reliable applications gracefully handle failure. When a primary AI provider is slow, at capacity, or returns an error, your application must remain operational. Portkey’s fallback feature is designed for exactly this, ensuring continuity by automatically switching to a backup provider.
This cookbook provides hands-on recipes to help you test and understand this critical feature. You will learn to intentionally trigger failures to see how fallbacks protect your application.
What You’ll Test:
- Model Failure: What happens when a requested model name is invalid?
- Rate Limit Errors: How does the app react when a provider is too busy?
- Guardrail Violations: How can you enforce content rules while maintaining availability?
By the end, you will have the confidence to build more resilient AI applications.
Prerequisites: Setting Up Your Environment
Before you start, ensure you have:
- A Portkey account.
- At least two AI Providers configured in the Model Catalog. We’ll use
@openai-prod and @anthropic-prod.
- Python with the Portkey SDK installed:
pip install portkey-ai.
- Your Portkey API Key set as an environment variable.
To set an environment variable, use one of the commands below in your terminal:
Recipe 1: Fallback on Model Failure
A model failure is a common issue, often caused by an invalid model string. This recipe simulates this failure and shows the fallback in action. When the primary provider cannot find the requested model, it returns an error, and Portkey steps in.
No special UI setup is needed for this recipe beyond having a valid @openai-prod provider. The failure will be induced directly in our request config by referencing a model name that does not exist.
Step 2: Run the Test
The following code attempts a request using a config where the primary target specifies an invalid model name. Portkey will detect the 404 Not Found error from the provider and automatically retry with the valid fallback provider.
Step 3: Verify the Fallback
The final response comes from Anthropic, your fallback provider.
To see the complete journey, go to the Logs Page in your Portkey dashboard. Find the most recent request. You will see two attempts associated with it:
FAILED: The first request to @openai-prod, which failed with a 404 Not Found status because the model name was invalid.SUCCESS: The automatic fallback request to @anthropic-prod.
Recipe 2: Fallback on Rate Limit Errors
High traffic can cause providers to return a 429 Too Many Requests error. This recipe shows how to configure a fallback that triggers only on this specific error.
In your Portkey dashboard, navigate to your valid OpenAI provider (@openai-prod) and apply a strict Rate Limit: 1 Request per Minute.
Step 2: Run the Test
This script sends two requests in quick succession. The second request will hit the rate limit, forcing a fallback. The config uses on_status_codes: [429] to ensure the fallback only triggers for rate limit errors.
Step 3: Verify the Fallback
The first request succeeds with OpenAI. The second request returns a successful response from Anthropic.
Check the Logs page for the second request. You will see the FAILED attempt to @openai-prod with a 429 status, followed by the SUCCESS call to @anthropic-prod.
Recipe 3: Fallback on Guardrail Violations
Portkey Guardrails can block requests that violate your content policies, returning a 446 status code. You can use this to trigger a fallback, perhaps to a different model better suited for the filtered content.
-
Navigate to Guardrails → Create
-
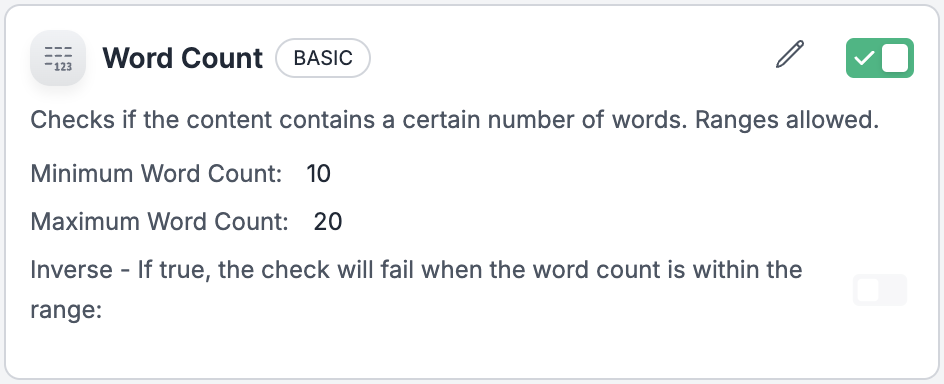
Search for “word count” under Basic guardrails
-
Create a guardrail as shown below.
-
In the actions tab select
Deny the request if guardrail fails flag.
-
Save the guardrail and note the
guardrail ID for next step
Create a saved Portkey Config in the UI.
-
Navigate to Configs in your Portkey dashboard and click Create.
-
Use a clear ID like
fallback-on-guardrail-fail.
-
Paste the following JSON. Notice the
input_guardrails block is nested inside the first target:
-
Save the Config.
Step 2: Run the Test
This code sends an input that is intentionally too long, violating our 10-word limit. This will trigger the 446 error and the fallback.
Step 3: Verify the Fallback
The request succeeds, and the response comes from Anthropic.
Go to the Logs page and find the request you just sent. You’ll see its trace:
FAILED: The first attempt to @openai-prod, blocked by the word_count guardrail with a 446 status.SUCCESS: The automatic fallback to @anthropic-prod, which processed the input.
Summary of Best Practices
- Test Your Configs: Actively test your fallback logic to ensure it behaves as you expect during a real outage.
- Be Specific with Status Codes: Use
on_status_codes to control precisely which errors trigger a fallback. This prevents unnecessary fallbacks on transient issues.
- Monitor Your Logs: The Trace View in Portkey Logs is your best tool for understanding fallback behavior, latency, and costs.
- Consider Your Fallback Chain: Choose fallback providers that are compatible with your use case and be mindful of their different performance and cost profiles.
Last modified on August 11, 2025