- Complete observability of every agent step, tool use, and LLM interaction
- Built-in reliability with automatic fallbacks, retries, and load balancing
- 1600+ LLMs accessible through the same OpenAI-compatible interface
- Production monitoring with traces, logs, and real-time metrics
- Zero code changes to your existing Strands agent implementations
Strands Agents Documentation
Learn more about Strands Agents’ core concepts and features
Quick Start
1
Install Dependencies
2
Replace Your Model Initialization
Instead of initializing your OpenAI model directly:Initialize it through Portkey’s gateway:
3
Use Your Agent Normally
How the Integration Works
The integration leverages Strands’ flexibleclient_args parameter, which passes any arguments directly to the OpenAI client constructor. By setting base_url to Portkey’s gateway, all requests route through Portkey while maintaining full compatibility with the OpenAI API.
Setting Up Portkey
Before using the integration, you need to configure your AI providers and create a Portkey API key.1
Add Your AI Provider Keys
Go to Model Catalog in the Portkey dashboard and add your AI provider keys (OpenAI, Anthropic, etc.). Each provider gets an AI Provider slug that you’ll reference in configs.
2
Create a Configuration
Go to Configs to define how requests should be routed. A basic config looks like:For production setups, you can add fallbacks, load balancing, and conditional routing here.
3
Generate Your Portkey API Key
Go to API Keys to create a new API key. Attach your config as the default routing config, and you’ll get an API key that routes to your configured providers.
Complete Integration Example
Here’s a full example showing how to set up a Strands agent with Portkey integration:Production Features
1. Enhanced Observability
Portkey provides comprehensive visibility into your agent’s behavior without requiring any code changes.- Request Tracing
- Custom Metadata
- Real-time Monitoring
Track the complete execution flow of your agents with hierarchical traces that show: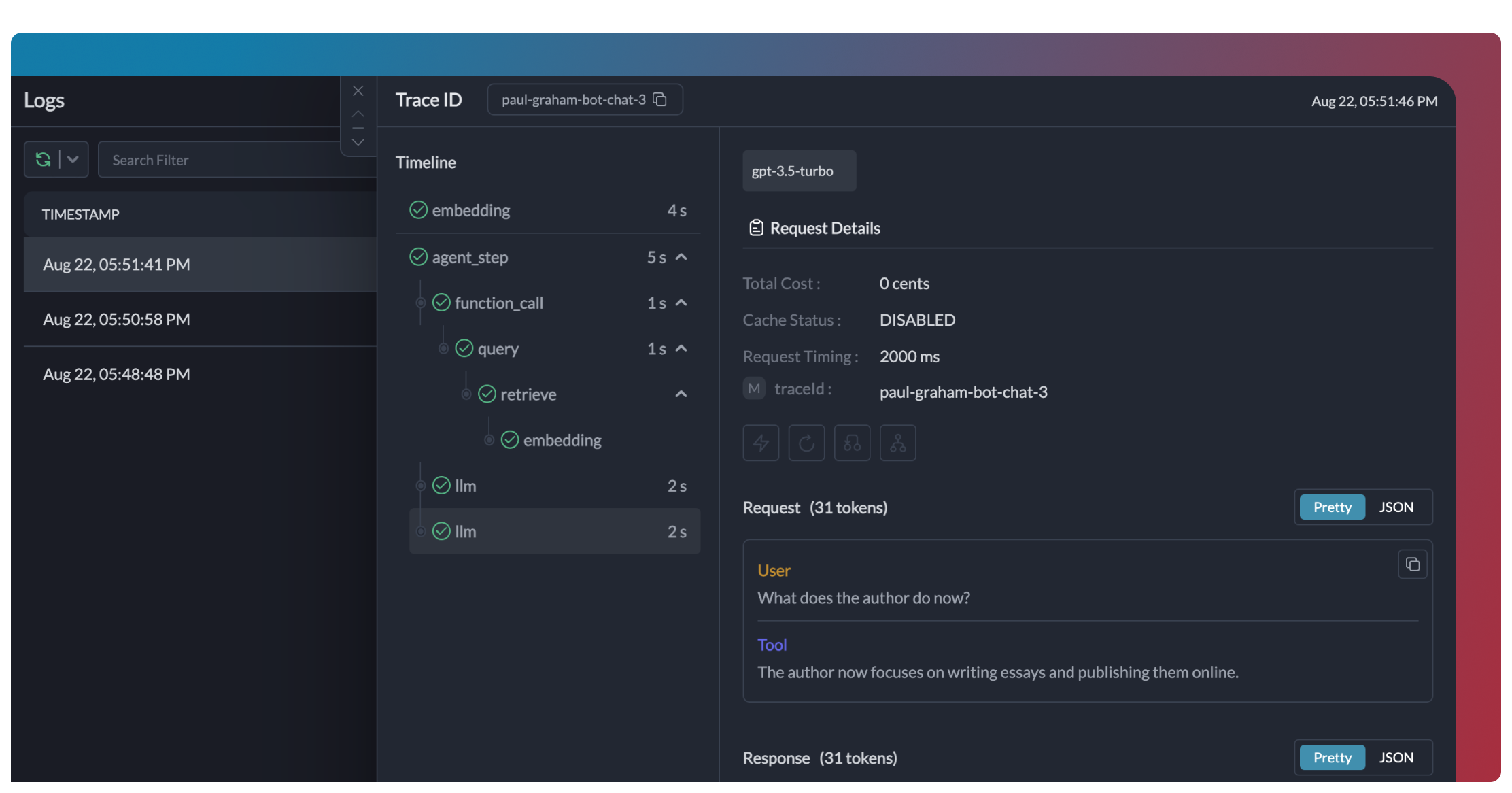
- LLM calls: Every request to language models with full payloads
- Tool invocations: Which tools were called, with what parameters, and their responses
- Decision points: How the agent chose between different tools or approaches
- Performance metrics: Latency, token usage, and cost for each step
2. Reliability & Fallbacks
When running agents in production, things can go wrong - API rate limits, network issues, or provider outages. Portkey’s reliability features ensure your agents keep running smoothly even when problems occur. It’s simple to enable fallback in your Strands Agents by using a Portkey Config that you can attach at runtime or directly to your Portkey API key. Here’s an example of attaching a Config at runtime:- Automatic Fallbacks
- Load Balancing
- Conditional Routing
Configure multiple providers so your agents keep working even when one provider fails:If OpenAI returns a rate limit error (429), Portkey automatically retries the request with Anthropic’s Claude, using default model mappings.
3. LLM Interoperability
Access 1,600+ models through the same Strands interface by changing just the provider configuration:- Using Anthropic
- Using Multiple Providers in One Agent
- OpenAI (GPT-4o, GPT-4 Turbo, etc.)
- Anthropic (Claude 3.5 Sonnet, Claude 3 Opus, etc.)
- Mistral AI (Mistral Large, Mistral Medium, etc.)
- Google Vertex AI (Gemini 1.5 Pro, etc.)
- Cohere (Command, Command-R, etc.)
- AWS Bedrock (Claude, Titan, etc.)
- Local/Private Models
Supported Providers
See the full list of LLM providers supported by Portkey
4. Guardrails for Safe Agents
Guardrails ensure your Strands agents operate safely and respond appropriately in all situations. Why Use Guardrails? Strands agents can experience various failure modes:- Generating harmful or inappropriate content
- Leaking sensitive information like PII
- Hallucinating incorrect information
- Generating outputs in incorrect formats
- Detect and redact PII in both inputs and outputs
- Filter harmful or inappropriate content
- Validate response formats against schemas
- Check for hallucinations against ground truth
- Apply custom business logic and rules
Learn More About Guardrails
Explore Portkey’s guardrail features to enhance agent safety
Advanced Configuration
- Environment-Specific Settings
- Request-Level Overrides
Configure different behavior for development, staging, and production:
Enterprise Governance
If you are using Strands inside your organization, you need to consider several governance aspects:- Cost Management: Controlling and tracking AI spending across teams
- Access Control: Managing which teams can use specific models
- Usage Analytics: Understanding how AI is being used across the organization
- Security & Compliance: Maintaining enterprise security standards
- Reliability: Ensuring consistent service across all users
Centralized Key Management
Instead of distributing raw API keys to developers, use Portkey API keys that you can control centrally:- Rotate provider keys without updating any code
- Set spending limits per team or API key
- Control model access (which teams can use which models)
- Monitor usage across all teams and projects
- Revoke access instantly if needed
Usage Analytics & Budgets
Track and control AI spending across your organization:- Per-team budgets: Set monthly spending limits for different teams
- Model usage analytics: See which teams are using which models most
- Cost attribution: Understand costs by project, team, or user
- Usage alerts: Get notified when teams approach their limits
Contact & Support
Enterprise SLAs & Support
Get dedicated SLA-backed support.
Portkey Community
Join our forums and Slack channel.
Resources
Strands Agents Docs
Book a Demo
Get personalized guidance on implementing this integration
Troubleshooting
Import Errors
Import Errors
Problem: Verify versions are compatible:
ModuleNotFoundError when importing Portkey componentsSolution: Ensure all dependencies are installed:Authentication Errors
Authentication Errors
Problem:
AuthenticationError when making requestsSolution: Verify your Portkey API key and provider setup: Verify your Portkey API key and provider setup. Test your Portkey API key directly and check for common issues such as wrong API key format, misconfigured provider, and missing config attachments.Rate Limiting
Rate Limiting
Problem: Hitting rate limits despite having fallbacks configuredSolution: Check your fallback configuration:Also verify that your backup providers have sufficient quota.
Model Compatibility
Model Compatibility
Problem: Model not found or unsupported model errorsSolution: Check that your model ID is correct for the provider:
Missing Traces/Logs
Missing Traces/Logs
Problem: Not seeing traces or logs in Portkey dashboardSolution: Verify your requests are going through Portkey:Also check the Logs section in your Portkey dashboard and filter by your metadata.
Frequently Asked Questions
How does Portkey enhance Strands Agents?
How does Portkey enhance Strands Agents?
Portkey adds production-readiness to Strands Agents through comprehensive observability (traces, logs, metrics), reliability features (fallbacks, retries, caching), and access to 1600+ LLMs through a unified interface. This makes it easier to debug, optimize, and scale your agent applications, all while preserving Strands Agents’ strong type safety.
Can I use Portkey with existing Strands Agents applications?
Can I use Portkey with existing Strands Agents applications?
Yes! Portkey integrates seamlessly with existing Strands Agents applications. You just need to replace your client initialization code with the Portkey-enabled version. The rest of your agent code remains unchanged and continues to benefit from Strands Agents’ strong typing.
Does Portkey work with all Strands Agents features?
Does Portkey work with all Strands Agents features?
Portkey supports all Strands Agents features, including tool use, multi-agent systems, and more. It adds observability and reliability without limiting any of the framework’s functionality.
Can I track usage across multiple agents in a workflow?
Can I track usage across multiple agents in a workflow?
Yes, Portkey allows you to use a consistent
trace_id across multiple agents and requests to track the entire workflow. This is especially useful for multi-agent systems where you want to understand the full execution path.How do I filter logs and traces for specific agent runs?
How do I filter logs and traces for specific agent runs?
Portkey allows you to add custom metadata to your agent runs, which you can then use for filtering. Add fields like
agent_name, agent_type, or session_id to easily find and analyze specific agent executions.Can I use my own API keys with Portkey?
Can I use my own API keys with Portkey?
Yes! Portkey uses your own API keys for the various LLM providers. It securely stores them, allowing you to easily manage and rotate keys without changing your code.
Next Steps
Now that you have Portkey integrated with your Strands agents:- Monitor your agents in the Portkey dashboard to understand their behavior
- Set up fallbacks for critical production agents using multiple providers
- Add custom metadata to track different agent types or user segments
- Configure budgets and alerts if you’re deploying multiple agents
- Explore advanced routing to optimize for cost, latency, or quality
Portkey Dashboard
View your agent logs, traces, and analytics
Supported Models
See all 1600+ models you can use with this integration
Enterprise Features
Explore governance, security, and compliance features