Getting Started
1. Install the required packages:
2. Configure your Langchain LLM objects:
Integration Guide
Here’s a simple Google Colab notebook that demonstrates Llama Index with Portkey integrationMake your agents Production-ready with Portkey
Portkey makes your Llama Index agents reliable, robust, and production-grade with its observability suite and AI Gateway. Seamlessly integrate 1600+ LLMs with your Llama Index agents using Portkey. Implement fallbacks, gain granular insights into agent performance and costs, and continuously optimize your AI operations—all with just 2 lines of code. Let’s dive deep! Let’s go through each of the use cases!1. Interoperability
Easily switch between 1600+ LLMs. Call various LLMs such as Anthropic, Gemini, Mistral, Azure OpenAI, Google Vertex AI, AWS Bedrock, and many more by simply changing theprovider and API key in the ChatOpenAI object.
- OpenAI to Azure OpenAI
- Anthropic to AWS Bedrock
If you are using OpenAI with CrewAI, your code would look like this:To switch to Azure as your provider, add your Azure details to Portley and create an integration (here’s how).
2. Reliability
Agents are brittle. Long agentic pipelines with multiple steps can fail at any stage, disrupting the entire process. Portkey solves this by offering built-in fallbacks between different LLMs or providers, load-balancing across multiple instances or API keys, and implementing automatic retries and request timeouts. This makes your agents more reliable and resilient. Here’s how you can implement these features using Portkey’s config3. Metrics
Agent runs can be costly. Tracking agent metrics is crucial for understanding the performance and reliability of your AI agents. Metrics help identify issues, optimize runs, and ensure that your agents meet their intended goals. Portkey automatically logs comprehensive metrics for your AI agents, including cost, tokens used, latency, etc. Whether you need a broad overview or granular insights into your agent runs, Portkey’s customizable filters provide the metrics you need. For agent-specific observability, addTrace-id to the request headers for each agent.
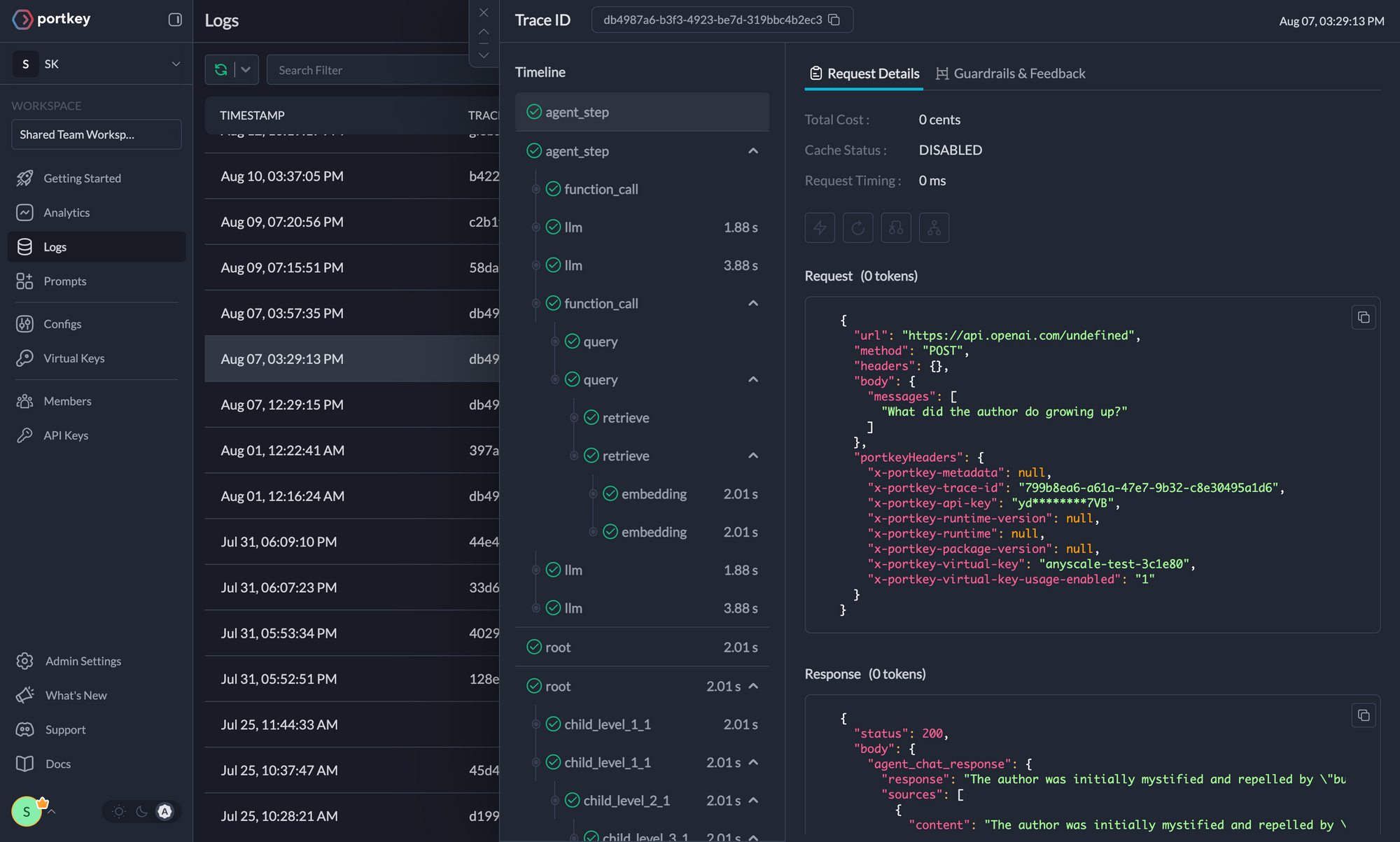
4. Logs
Agent runs are complex. Logs are essential for diagnosing issues, understanding agent behavior, and improving performance. They provide a detailed record of agent activities and tool use, which is crucial for debugging and optimizing processes. Portkey offers comprehensive logging features that capture detailed information about every action and decision made by your AI agents. Access a dedicated section to view records of agent executions, including parameters, outcomes, function calls, and errors. Filter logs based on multiple parameters such as trace ID, model, tokens used, and metadata.
5. Traces
With traces, you can see each agent run granularly on Portkey. Tracing your Langchain agent runs helps in debugging, performance optimzation, and visualizing how exactly your agents are running.Using Traces in Langchain Agents
Step 1: Import & Initialize the Portkey Langchain Callback Handler
Step 2: Configure Your LLM with the Portkey Callback
6. Guardrails
LLMs are brittle - not just in API uptimes or their inexplicable400/500 errors, but also in their core behavior. You can get a response with a 200 status code that completely errors out for your app’s pipeline due to mismatched output. With Portkey’s Guardrails, we now help you enforce LLM behavior in real-time with our Guardrails on the Gateway pattern.
Using Portkey’s Guardrail platform, you can now verify your LLM inputs AND outputs to be adhering to your specifed checks; and since Guardrails are built on top of our Gateway, you can orchestrate your request exactly the way you want - with actions ranging from denying the request, logging the guardrail result, creating an evals dataset, falling back to another LLM or prompt, retrying the request, and more.