Key Benefits
- Unified API Access: Manage private and commercial LLMs through a single, consistent interface
- Enhanced Reliability: Leverage Portkey’s fallbacks, retries, and load balancing for your private deployments
- Comprehensive Monitoring: Track performance, usage, and costs alongside your commercial LLM usage
- Simplified Access Control: Manage team-specific permissions and usage limits
- Secure Credential Management: Protect sensitive authentication details through Portkey’s secure vault
Integration Options
PrerequisitesYour private LLM must implement an API specification compatible with one of Portkey’s supported providers (e.g., OpenAI’s
/chat/completions, Anthropic’s /messages, etc.).- Using Model Catalog: Store your deployment details securely in Portkey’s Model Catalog
- Direct Integration: Pass deployment details in your requests without storing them
Option 1: Using Model Catalog
Step 1: Add Your Private LLM to Model Catalog
Navigate to Model Catalog → Add Provider in your Portkey dashboard.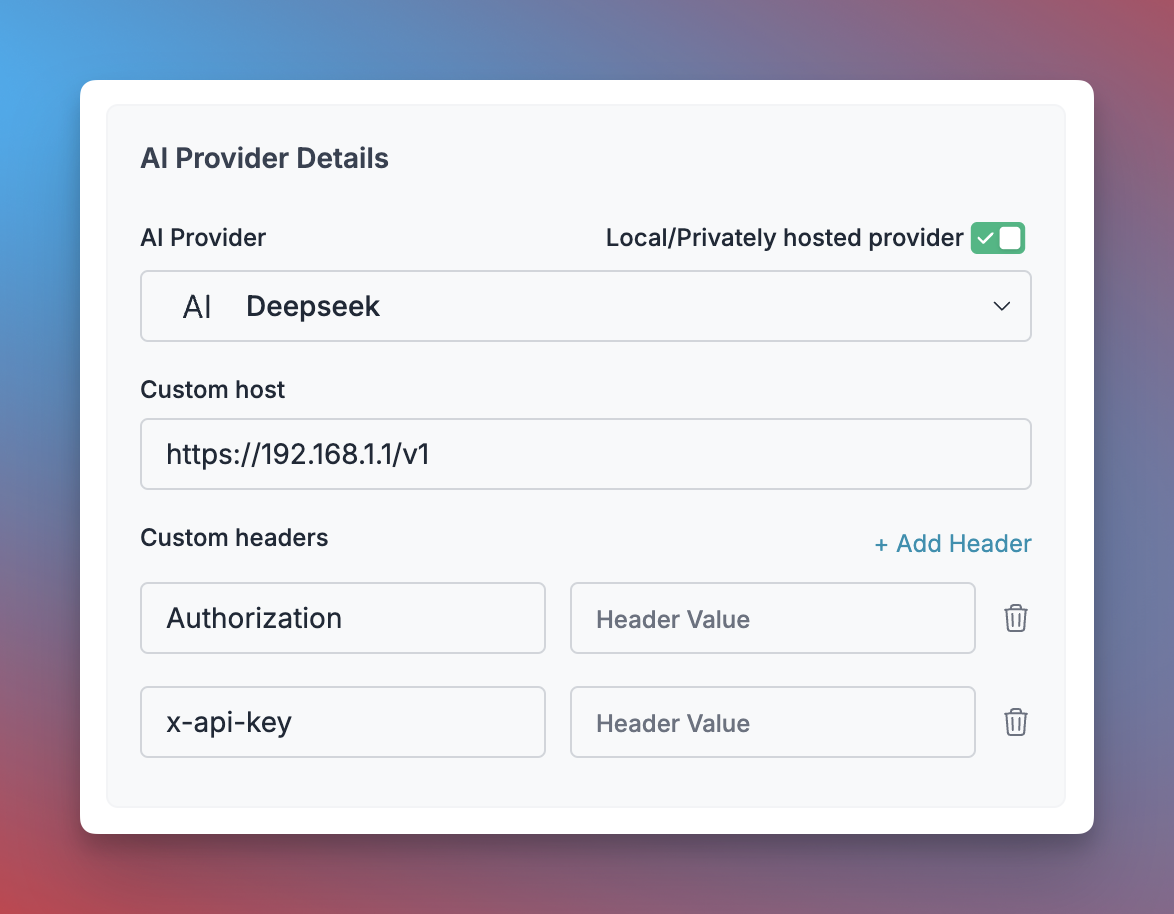
Adding a private LLM to Model Catalog
- Click “Add Provider” and enable the “Local/Privately hosted provider” toggle
- Configure your deployment:
- Select the matching provider API specification (typically
OpenAI) - Enter your model’s base URL in the
Custom Hostfield - Add required authentication headers and their values
- Select the matching provider API specification (typically
- Name your provider (e.g.,
my-private-llm) - Click “Create” to save your configuration
Step 2: Use Your Provider in Requests
After adding your provider to the Model Catalog, you can use it in your applications:Option 2: Direct Integration Without Model Catalog
If you prefer not to store your private LLM details in Portkey’s Model Catalog, you can pass them directly in your API requests:The
custom_host must include the API version path (e.g., /v1/). Portkey will automatically append the endpoint path (/chat/completions, /completions, or /embeddings).Portkey blocks requests to private and reserved IP ranges by default. If your private LLM runs on an internal network IP, see Custom hosts for blocked patterns and how to allowlist specific hosts.
Securely Forwarding Sensitive Headers
For headers containing sensitive information that shouldn’t be logged or processed by Portkey, use theforward_headers parameter to pass them directly to your private LLM:
- NodeJS
- Python
- cURL
In the JavaScript SDK, convert header names to camelCase. For example,
X-My-Custom-Header becomes xMyCustomHeader.Using Forward Headers in Gateway Configs
You can also specifyforward_headers in your Gateway Config for consistent header forwarding:
Advanced Features
Using Private LLMs with Gateway Configs
Private LLMs work seamlessly with all Portkey Gateway features. Some common use cases:- Load Balancing: Distribute traffic across multiple private LLM instances
- Fallbacks: Set up automatic failover between private and commercial LLMs
- Conditional Routing: Route requests to different LLMs based on metadata
Monitoring and Analytics
Portkey provides comprehensive observability for your private LLM deployments, just like it does for commercial providers:- Log Analysis: View detailed request and response logs
- Performance Metrics: Track latency, token usage, and error rates
- User Attribution: Associate requests with specific users via metadata

Portkey Analytics Dashboard for Private LLMs
Troubleshooting
FAQs
Can I use any private LLM with Portkey?
Can I use any private LLM with Portkey?
Yes, as long as it implements an API specification compatible with one of Portkey’s supported providers (OpenAI, Anthropic, etc.). The model should accept requests and return responses in the format expected by that provider.
How do I handle multiple deployment endpoints?
How do I handle multiple deployment endpoints?
You have two options:
- Create separate integration for each endpoint
- Use Gateway Configs with load balancing to distribute traffic across multiple endpoints
Are there any request volume limitations?
Are there any request volume limitations?
Portkey itself doesn’t impose specific request volume limitations for private LLMs. Your throughput will be limited only by your private LLM deployment’s capabilities and any rate limits you configure in Portkey.
Can I use different models with the same private deployment?
Can I use different models with the same private deployment?
Yes, you can specify different model names in your requests as long as your private LLM deployment supports them. The model name is passed through to your deployment.
Can I mix private and commercial LLMs in the same application?
Can I mix private and commercial LLMs in the same application?
Absolutely! One of Portkey’s key benefits is the ability to manage both private and commercial LLMs through a unified interface. You can even set up fallbacks between them or route requests conditionally.