Integrate
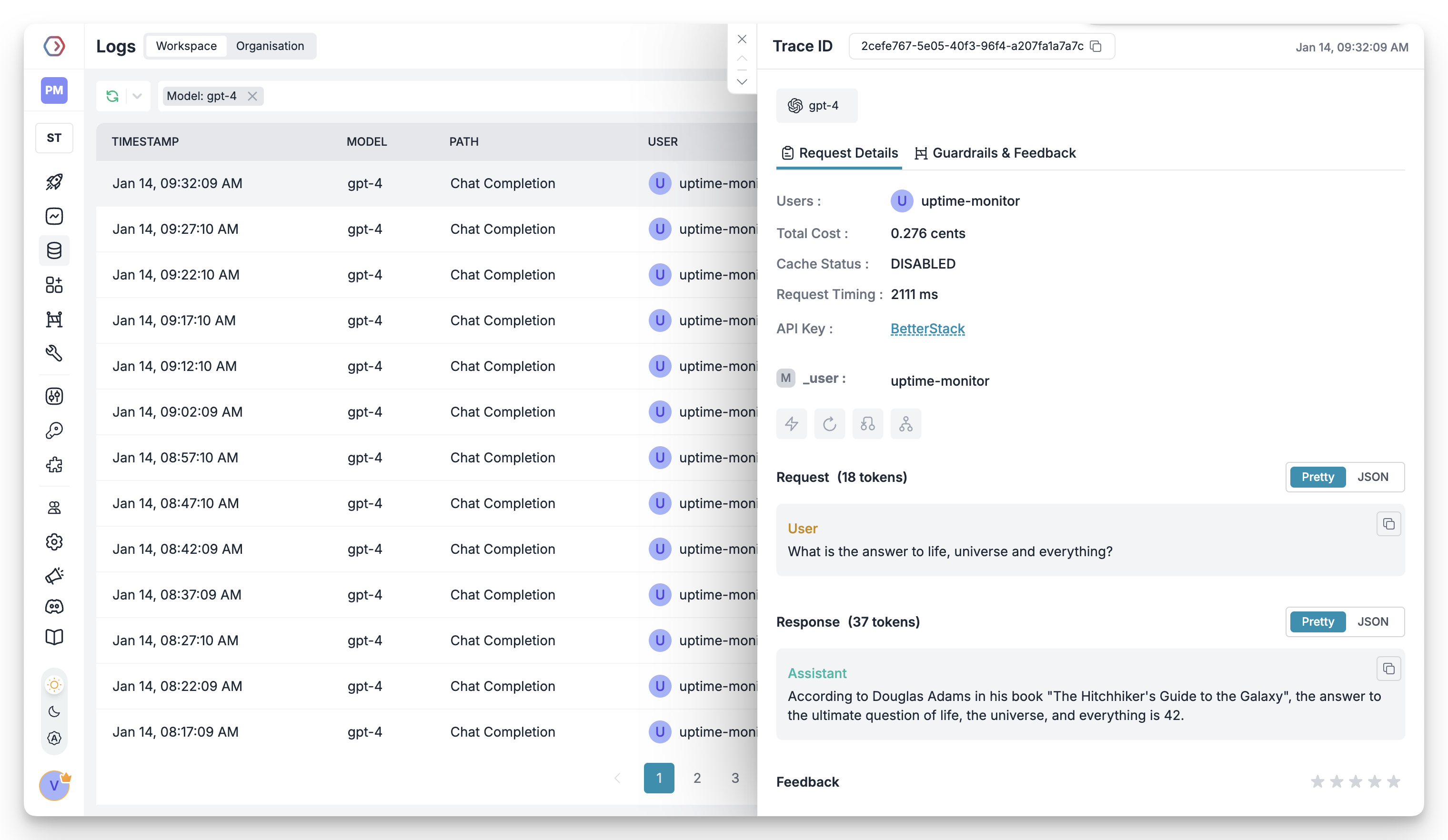
Add your OpenAI API Key from here to Model Catalog to create an AI Provider. Your OpenAI personal or service account API keys can be saved to Portkey. Additionally, your OpenAI Admin API Keys can also be saved to Portkey so that you can route to OpenAI Admin routes through Portkey API.Sample Request
Portkey is a drop-in replacement for OpenAI. You can make request using the official OpenAI or Portkey SDKs.- NodeJS
- Python
- cURL
- OpenAI Python SDK
- OpenAI NodeJS SDK
- Portkey Prompts
Local Setup
If you do not want to use Portkey’s hosted API, you can also run Portkey locally:
baseURL to the local Gateway URL, and make requests:
More details here →
Support for OpenAI Capabilities
Portkey works with all of OpenAI’s endpoints and supports all OpenAI capabilities like prompt caching, structured outputs, and more.OpenAI Tool Calling
OpenAI Structured Outputs
OpenAI Vision
OpenAI Embeddings
OpenAI Prompt Caching
OpenAI Image Generation
OpenAI STT
OpenAI TTS
OpenAI Realtime API
OpenAI Moderations
OpenAI Reasoning
OpenAI Predicted Outputs
OpenAI Fine-tuning
OpenAI Assistants
OpenAI Batch Inference API
OpenAI Tool Calling
Tool calling feature lets models trigger external tools based on conversation context. You define available functions, the model chooses when to use them, and your application executes them and returns results. Portkey supports OpenAI Tool Calling and makes it interoperable across multiple providers. With Portkey Prompts, you can templatize various your prompts & tool schemas as well.- Node.js
- Python
- cURL
- Portkey Prompts
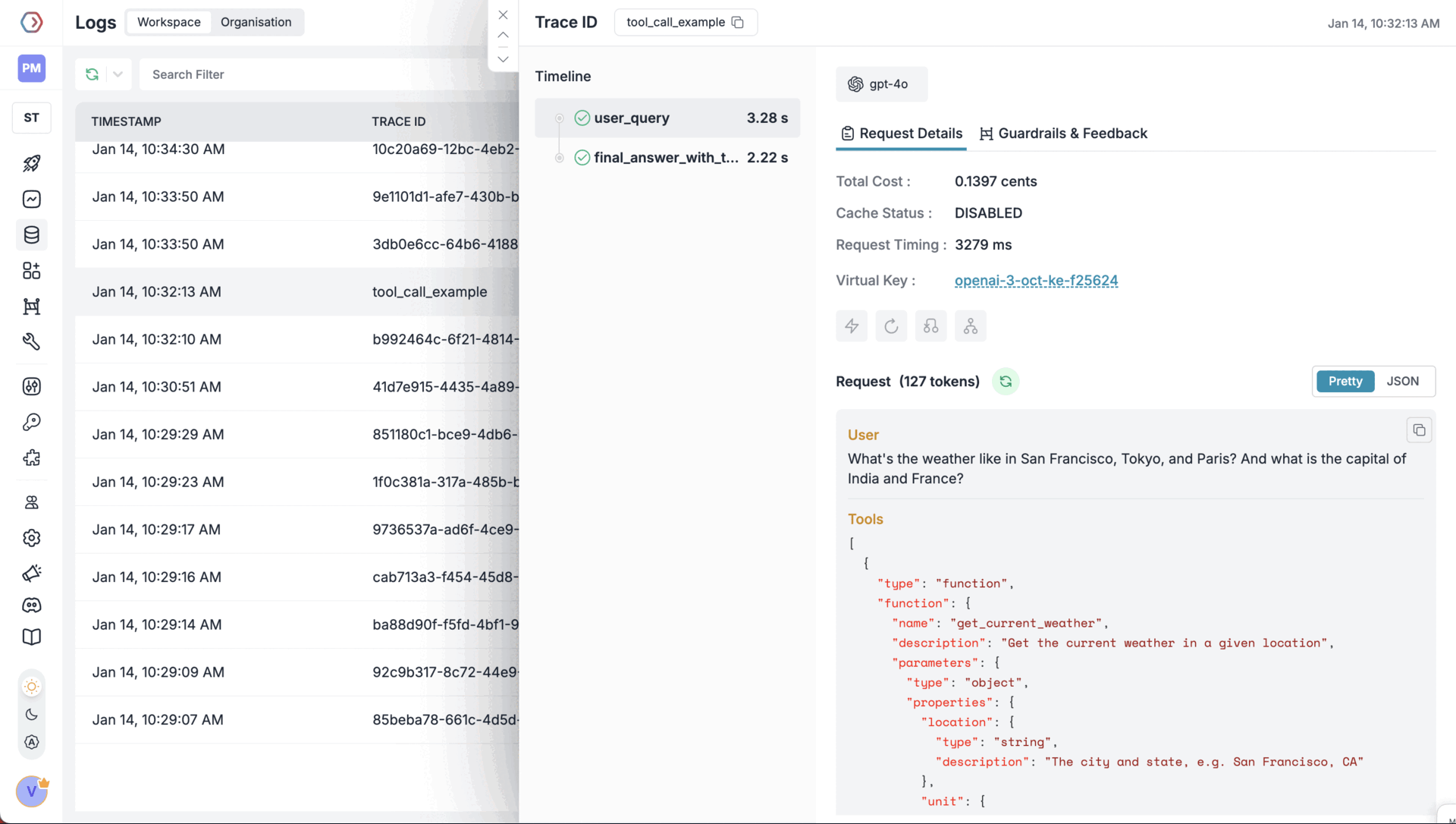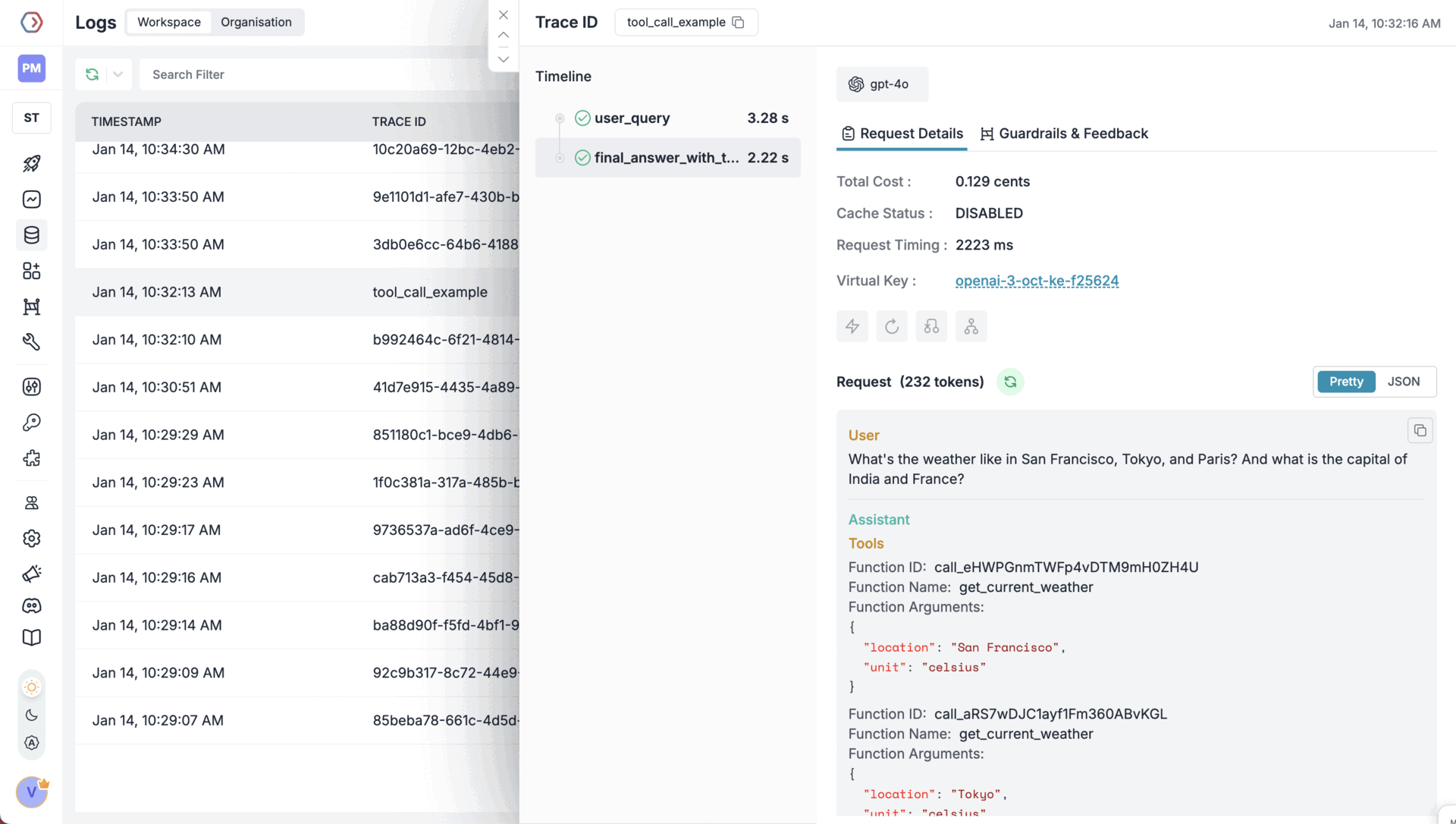
OpenAI Structured Outputs
Use structured outputs for more consistent and parseable responses:Structured Outputs Guide
OpenAI Vision
OpenAI’s vision models can analyze images alongside text, enabling visual question-answering capabilities. Images can be provided via URLs or base64 encoding in user messages.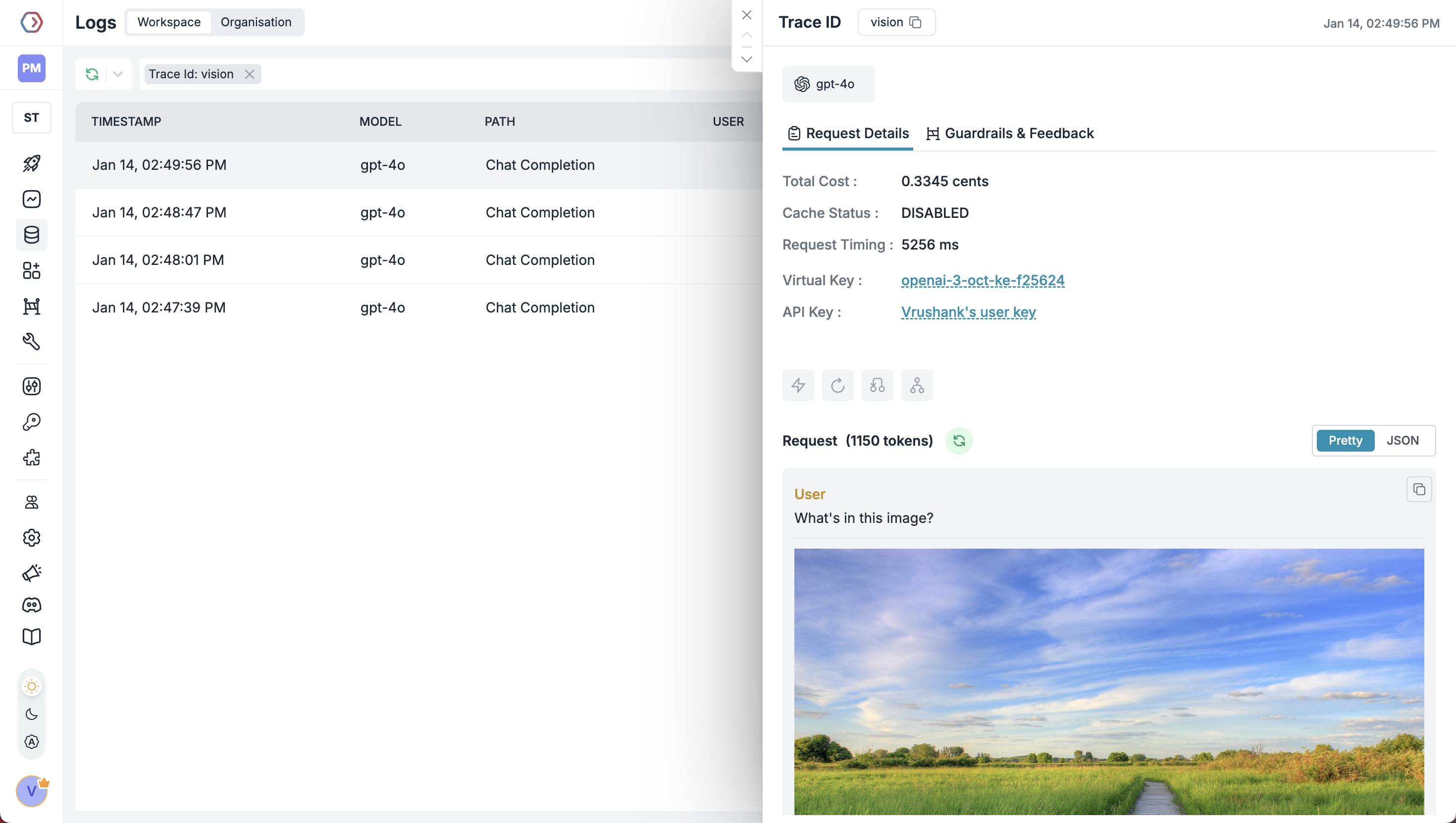
OpenAI Embeddings
OpenAI’s embedding models (liketext-embedding-3-small) transform text inputs into lists of floating point numbers - smaller distances between vectors indicate higher text similarity. They power use cases like semantic search, content clustering, recommendations, and anomaly detection.
Simply send text to the embeddings API endpoint to generate these vectors for your applications.
OpenAI Prompt Caching
Prompt caching automatically reuses results from similar API requests, reducing latency by up to 80% and costs by 50%. This feature works by default for all OpenAI API calls, requires no setup, and has no additional fees. Portkey accurately logs the usage statistics and costs for your cached requests.Prompt Caching Guide
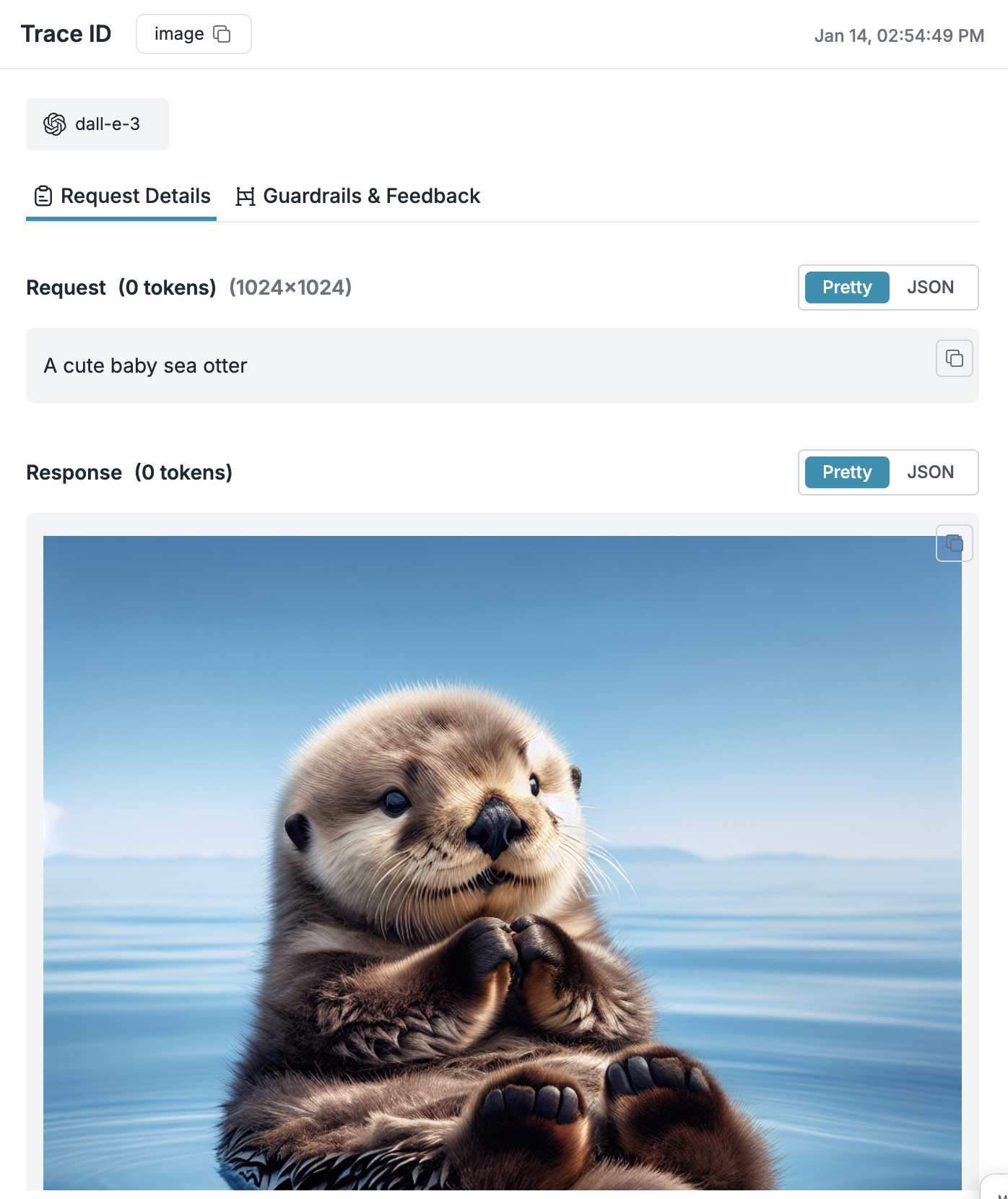
OpenAI Image Generations (DALL-E)
OpenAI’s Images API enables AI-powered image generation, manipulation, and variation creation for creative and commercial applications. Whether you’re building image generation features, editing tools, or creative applications, the API provides powerful visual AI capabilities through DALL·E models. The API offers three core capabilities:- Generate new images from text prompts (DALL·E 3, DALL·E 2)
- Edit existing images with text-guided replacements (DALL·E 2)
- Create variations of existing images (DALL·E 2)
OpenAI Transcription & Translation (Whisper)
OpenAI’s Audio API converts speech to text using the Whisper model. It offers transcription in the original language and translation to English, supporting multiple file formats and languages with high accuracy.OpenAI Text to Speech
OpenAI’s Text to Speech (TTS) API converts written text into natural-sounding audio using six distinct voices. It supports multiple languages, streaming capabilities, and various audio formats for different use cases.OpenAI Realtime API
OpenAI’s Realtime API enables dynamic, low-latency conversations combining text, voice, and function calling capabilities. Built on GPT-4o models optimized for realtime interactions, it supports both WebRTC for client-side applications and WebSockets for server-side implementations. Portkey enhances OpenAI’s Realtime API with production-ready features:- Complete request/response logging for realtime streams
- Cost tracking and budget management for streaming sessions
- Multi-modal conversation monitoring
- Session-based analytics and debugging
gpt-4o-realtimefor full capabilitiesgpt-4o-mini-realtimefor lighter applications
Realtime API Guide
More Capabilities
Streaming
Streaming
Predicted Outputs
Predicted Outputs
Fine-Tuning
Fine-Tuning
Batch Inference
Batch Inference
Assistants
Assistants
Moderations
Moderations
Reasoning
Reasoning
Portkey Features
Track End-User IDs
Track End-User IDs
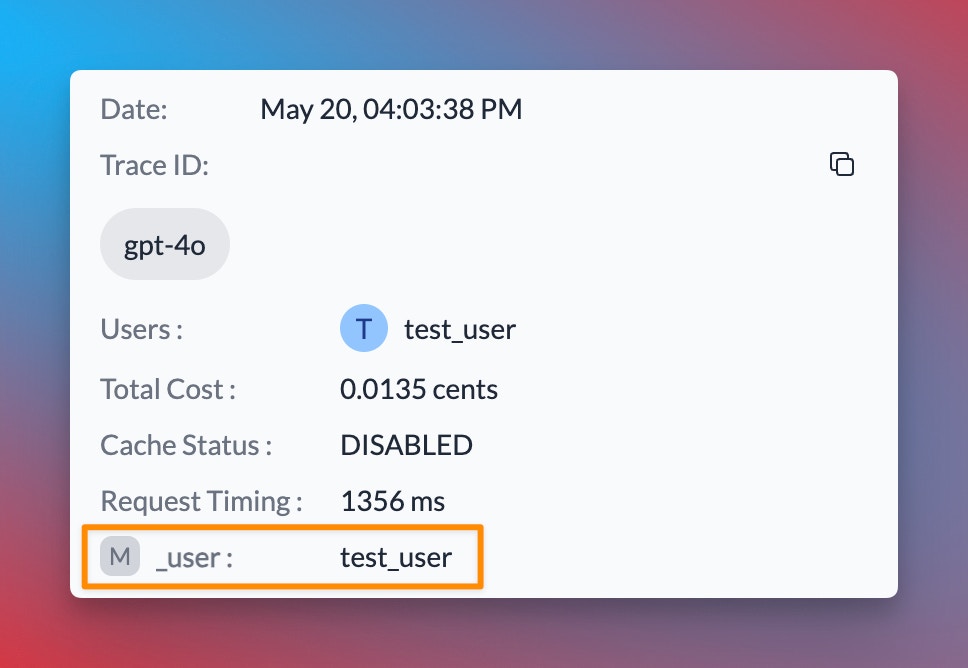
user parameter, Portkey allows you to send arbitrary custom metadata with your requests. This powerful feature enables you to associate additional context or information with each request, which can be useful for analysis, debugging, or other custom use cases.Learn More About Metadata
Setup Fallbacks & Loadbalancer
Setup Fallbacks & Loadbalancer
Create a Gateway Configuration
Process Requests
Set Up the Portkey Client
Load Balancing
Fallbacks
Conditional Routing
Caching
Setup Guardrails
Setup Guardrails
Learn More About Guardrails
Cache Requests
Cache Requests
Send Custom Metadata
Send Custom Metadata
Send Custom Metadata
Send Custom Metadata
Setup Rate Limits
Setup Rate Limits
Create & Deploy Prompt Templates
Create & Deploy Prompt Templates
Popular Libraries
You can make your OpenAI integrations with popular libraries also production-ready and reliable with native integrations.OpenAI with Langchain
OpenAI with LangGraph
OpenAI with LibreChat
OpenAI with CrewAI
OpenAI with Llamaindex
OpenAI with Vercel
More Libraries
Other popular projects
Other agent frameworks
Cookbooks
Setup a fallback from OpenAI to Azure OpenAI
A/B test your prompts
Appendix
OpenAI Projects & Organizations
Managing OpenAI Orgs on Portkey
Managing OpenAI Orgs on Portkey
Using Model Catalog
Using Model Catalog
Using Configs
Using Configs
While Making a Request
While Making a Request
Supported Parameters
List of supported & unsupported parameters from OpenAI
List of supported & unsupported parameters from OpenAI
Supported Models
List of OpenAI models supported by Portkey
List of OpenAI models supported by Portkey
Limitations
Limitations for Vision Requests
- Medical images: Vision models are not suitable for interpreting specialized medical images like CT scans and shouldn’t be used for medical advice.
- Non-English: The models may not perform optimally when handling images with text of non-Latin alphabets, such as Japanese or Korean.
- Small text: Enlarge text within the image to improve readability, but avoid cropping important details.
- Rotation: The models may misinterpret rotated / upside-down text or images.
- Visual elements: The models may struggle to understand graphs or text where colors or styles like solid, dashed, or dotted lines vary.
- Spatial reasoning: The models struggle with tasks requiring precise spatial localization, such as identifying chess positions.
- Accuracy: The models may generate incorrect descriptions or captions in certain scenarios.
- Image shape: The models struggle with panoramic and fisheye images.
- Metadata and resizing: The models do not process original file names or metadata, and images are resized before analysis, affecting their original dimensions.
- Counting: May give approximate counts for objects in images.
- CAPTCHAS: For safety reasons, CAPTCHA submissions are blocked by OpenAI.
Image Generations Limitations
- DALL·E 3 Restrictions:
- Only supports image generation (no editing or variations)
- Limited to one image per request
- Fixed size options: 1024x1024, 1024x1792, or 1792x1024 pixels
- Automatic prompt enhancement cannot be disabled
- Image Requirements:
- Must be PNG format
- Maximum file size: 4MB
- Must be square dimensions
- For edits/variations: input images must meet same requirements
- Content Restrictions:
- All prompts and images are filtered based on OpenAI’s content policy
- Violating content will return an error
- Edited areas must be described in full context, not just the edited portion
- Technical Limitations:
- Image URLs expire after 1 hour
- Image editing (inpainting) and variations only available in DALL·E 2
- Response format limited to URL or Base64 data
Speech-to-text Limitations
- File Restrictions:
- Maximum file size: 25 MB
- Supported formats: mp3, mp4, mpeg, mpga, m4a, wav, webm
- No streaming support
- Language Limitations:
- Translation output available only in English
- Variable accuracy for non-listed languages
- Limited control over generated audio compared to other language models
- Technical Constraints:
- Prompt limited to first 244 tokens
- Restricted processing for longer audio files
- No real-time transcription support
Text-to-Speech Limitations
- Voice Restrictions:
- Limited to 6 pre-built voices (alloy, echo, fable, onyx, nova, shimmer)
- Voices optimized primarily for English
- No custom voice creation support
- No direct control over emotional range or tone
- Audio Quality Trade-offs:
- tts-1: Lower latency but potentially more static
- tts-1-hd: Higher quality but increased latency
- Quality differences may vary by listening device
- Usage Requirements:
- Must disclose AI-generated nature to end users
- Cannot create custom voice clones
- Performance varies for non-English languages
FAQs
General
Is is free to use the OpenAI API key?
Is is free to use the OpenAI API key?
I am getting rate limited on OpenAI API
I am getting rate limited on OpenAI API
Vision FAQs
Can I fine-tune OpenAI models on vision requests?
Can I fine-tune OpenAI models on vision requests?
Can I use gpt-4o or other chat models to generate images?
Can I use gpt-4o or other chat models to generate images?
What type of files can I upload for vision requests?
What type of files can I upload for vision requests?
For vision requests, Iis there a limit to the size of the image I can upload?
For vision requests, Iis there a limit to the size of the image I can upload?
How do rate limits work for vision requests?
How do rate limits work for vision requests?
Can models understand image metadata?
Can models understand image metadata?
Embedding FAQs
How can I tell how many tokens a string has before I embed it?
How can I tell how many tokens a string has before I embed it?
How can I retrieve K nearest embedding vectors quickly?
How can I retrieve K nearest embedding vectors quickly?
Do V3 embedding models know about recent events?
Do V3 embedding models know about recent events?
text-embedding-3-large & text-embedding-3-small) is September 2021 - so they do not know about the most recent events.Prompt Caching FAQs
How is data privacy maintained for caches?
How is data privacy maintained for caches?
Does Prompt Caching affect output token generation or the final response of the API?
Does Prompt Caching affect output token generation or the final response of the API?
Is there a way to manually clear the cache?
Is there a way to manually clear the cache?
Will I be expected to pay extra for writing to Prompt Caching?
Will I be expected to pay extra for writing to Prompt Caching?
Do cached prompts contribute to TPM rate limits?
Do cached prompts contribute to TPM rate limits?
Is discounting for Prompt Caching available on Scale Tier and the Batch API?
Is discounting for Prompt Caching available on Scale Tier and the Batch API?
Does Prompt Caching work on Zero Data Retention requests?
Does Prompt Caching work on Zero Data Retention requests?
Image Generations FAQs
What's the difference between DALL·E 2 and DALL·E 3?
What's the difference between DALL·E 2 and DALL·E 3?
How long do the generated image URLs last?
How long do the generated image URLs last?
What are the size requirements for uploading images?
What are the size requirements for uploading images?
Can I disable DALL·E 3's automatic prompt enhancement?
Can I disable DALL·E 3's automatic prompt enhancement?
How many images can I generate per request?
How many images can I generate per request?
What image formats are supported?
What image formats are supported?
How does image editing (inpainting) work?
How does image editing (inpainting) work?
Speech-to-text FAQs
What audio file formats are supported?
What audio file formats are supported?
Can I translate audio to languages other than English?
Can I translate audio to languages other than English?
How do I handle audio files longer than 25 MB?
How do I handle audio files longer than 25 MB?
Does the API support all languages equally well?
Does the API support all languages equally well?
Can I get timestamps in the transcription?
Can I get timestamps in the transcription?
timestamp_granularities parameter, you can get timestamps at the segment level, word level, or both.How can I improve transcription accuracy for specific terms?
How can I improve transcription accuracy for specific terms?
What's the difference between transcription and translation?
What's the difference between transcription and translation?
Text-to-Speech FAQs
What are the differences between TTS-1 and TTS-1-HD models?
What are the differences between TTS-1 and TTS-1-HD models?
Which audio formats are supported?
Which audio formats are supported?
Can I create or clone custom voices?
Can I create or clone custom voices?
How well does it support non-English languages?
How well does it support non-English languages?
Can I control the emotional tone or style of the speech?
Can I control the emotional tone or style of the speech?
Is real-time streaming supported?
Is real-time streaming supported?
Do I need to disclose that the audio is AI-generated?
Do I need to disclose that the audio is AI-generated?