Portkey SDK Integration with AWS Bedrock
Portkey provides a consistent API to interact with models from various providers. To integrate Bedrock with Portkey:1. Install the Portkey SDK
Add the Portkey SDK to your application to interact with Anthropic’s API through Portkey’s gateway.- NodeJS
- Python
2. Initialize Portkey with the Bedrock Provider
There are two ways to integrate AWS Bedrock with Portkey:AWS Access Key
Use your
AWS Secret Access Key, AWS Access Key Id, and AWS Region to create your AI Provider on Portkey’s app.Integration Guide
AWS Assumed Role
Take your
AWS Assumed Role ARN and AWS Region to create your Bedrock provider.Integration Guide
- NodeJS SDK
- Python SDK
Using Bedrock Provider with AWS STS
If you’re using AWS Security Token Service, you can pass youraws_session_token along with the AI Provider slug:
- NodeJS
- Python
Not using Bedrock Provider from Model Catalog?
Check out this example on how you can directly use your AWS details to make a Bedrock request through Portkey.3. Invoke Chat Completions with AWS bedrock
Use the Portkey instance to send requests to Anthropic. You can also override the provider slug directly in the API call if needed.- NodeJS SDK
- Python SDK
Using the /messages Route with Bedrock Models
Access Bedrock’s Claude models through Anthropic’s native/messages endpoint using Portkey’s SDK or Anthropic’s SDK.
This route only works with Claude models on Bedrock. For other models, use the standard OpenAI compliant endpoint.
- cURL
- Python SDK
- NodeJS SDK
- Anthropic Python SDK
- Anthropic TypeScript SDK
Counting Tokens
Portkey supports the AWS Bedrock CountTokens API to estimate token usage before sending requests. Check out the count-tokens guide for more details.
Using Vision Models
Portkey’s multimodal Gateway fully supports Bedrock’s vision modelsanthropic.claude-3-sonnet, anthropic.claude-3-haiku, and anthropic.claude-3-opus
For more info, check out this guide:
Vision
Using S3 URIs in Chat Completions
Portkey supports S3 URIs directly in theimage_url field for chat completions. This allows you to reference files stored in S3 without needing to convert them to base64.
When using S3 URIs, the
mime_type parameter is required. The gateway cannot infer the MIME type from an S3 URI, so you must specify it explicitly.- Python SDK
- NodeJS SDK
- cURL
S3 URI Parameters
Supported Image Formats for S3 URIs
Ensure your Bedrock IAM role has the necessary S3 permissions (
s3:GetObject) to access the referenced objects.Extended Thinking (Reasoning Models) (Beta)
The assistants thinking response is returned in the
response_chunk.choices[0].delta.content_blocks array, not the response.choices[0].message.content string.us.anthropic.claude-3-7-sonnet-20250219-v1:0 support extended thinking.
This is similar to openai thinking, but you get the model’s reasoning as it processes the request as well.
Note that you will have to set strict_open_ai_compliance=False in the headers to use this feature.
Using reasoning_effort parameter
You can also use the OpenAI-compatible reasoning_effort parameter as a drop-in alternative to thinking.budget_tokens:
- Claude Opus 4.6 / Sonnet 4.6:
reasoning_effortenables adaptive thinking (thinking.type = "adaptive") — Claude decides the thinking budget automatically. - Other Claude reasoning models:
reasoning_effortis converted tothinking.budget_tokensas a ratio ofmax_tokens(minimal 10%, low 20%, medium 50%, high 80%), with a minimum of 1024 tokens.max_tokensmust be greater than 1024. reasoning_effort: "none"disables extended thinking.- An explicit
thinkingobject in the request always takes precedence overreasoning_effort.
Single turn conversation
Multi turn conversation
Inference Profiles
Inference profiles are a resource in Amazon Bedrock that define a model and one or more Regions to which the inference profile can route model invocation requests. To use inference profiles, your IAM role needs to additionally have the following permissions:Bedrock Guardrails
You can use Bedrock guardrails directly in your chat completions requests to add content filtering and safety measures. Guardrails help ensure that model responses adhere to your specific safety and content policies.We recommend using guardrails through the Portkey UI for easier management and configuration.
You can learn more about guardrails here.
Using Guardrails in Chat Completions
To enable guardrails, include theguardrailConfig parameter in your request:
- NodeJS SDK
- Python SDK
- cURL
Guardrail Configuration Parameters
Both
guardrailConfig (camelCase) and guardrail_config (snake_case) parameter names are supported for compatibility.guardrail_intervened stop reason. You can access detailed trace information if tracing is enabled.
Bedrock Converse API
Portkey uses the AWS Converse API internally for making chat completions requests. If you need to pass additional input fields or parameters likeanthropic_beta, top_k, frequency_penalty etc. that are specific to a model, you can pass it with this key:
Managing AWS Bedrock Prompts
You can manage all prompts to AWS bedrock in the Prompt Library. All the current models of Anthropic are supported and you can easily start testing different prompts. Once you’re ready with your prompt, you can use theportkey.prompts.completions.create interface to use the prompt in your application.
Making Requests without using Portkey’s Model Catalog
If you do not want to add your AWS details to Portkey vault, you can also directly pass them while instantiating the Portkey client.Mapping the Bedrock Details
Example
- NodeJS
- Python
- cURL
Using AWS PrivateLink for Bedrock [Self Hosted Enterprise]
Though using assumed role is in itself enough for enterprise security. You can additional configure AWS PrivateLink for Bedrock to ensure that your requests are not traversed outside your VPC.- Create a private link between the VPC you’ve deployed Portkey and AWS Bedrock (the endpoint is in most cases
https://bedrock.{your_region}.amazonaws.com). - When configuring your integration on portkey, simply configure the
custom hostoption to point to your VPC endpoint for the private link.
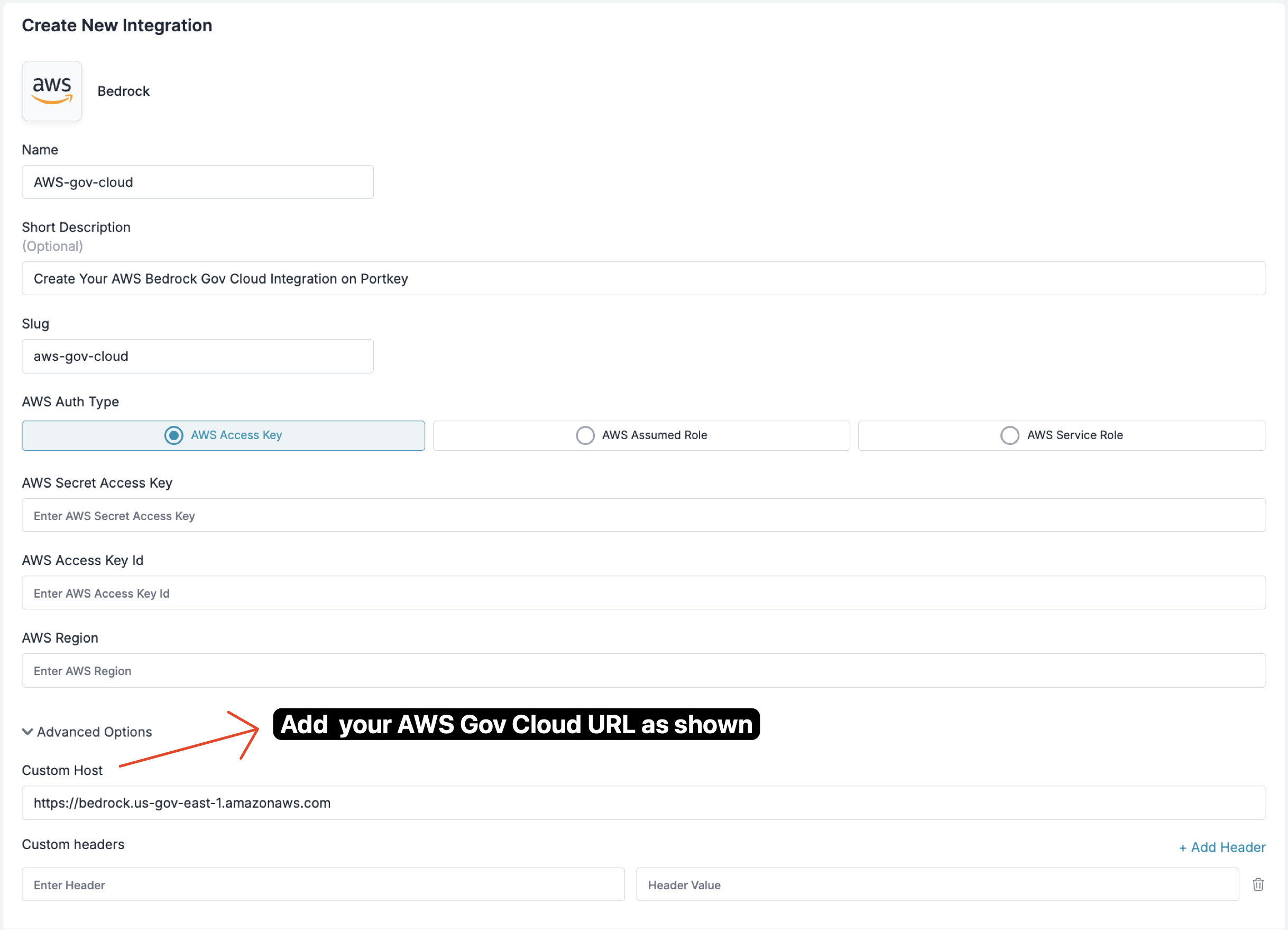
AWS GovCloud (US)
Integration is identical to standard Bedrock. Only the endpoint changes — set a Custom Host for your region.
Steps
- In Portkey, create or edit your Bedrock provider.
- Open “Advanced Options”.
- Set “Custom Host” to your GovCloud Bedrock endpoint:
https://bedrock.us-gov-east-1.amazonaws.comhttps://bedrock.us-gov-west-1.amazonaws.com- and more similarly…
- Save and use normally in SDKs and via the gateway.
Notes
- For the complete list of Bedrock endpoints, see the official AWS reference: Amazon Bedrock endpoints and quotas.
- For FIPS-compliant endpoints and additional compliance information, see: FIPS Endpoints by Service.
Supported Models
List of supported Amazon Bedrock model IDs
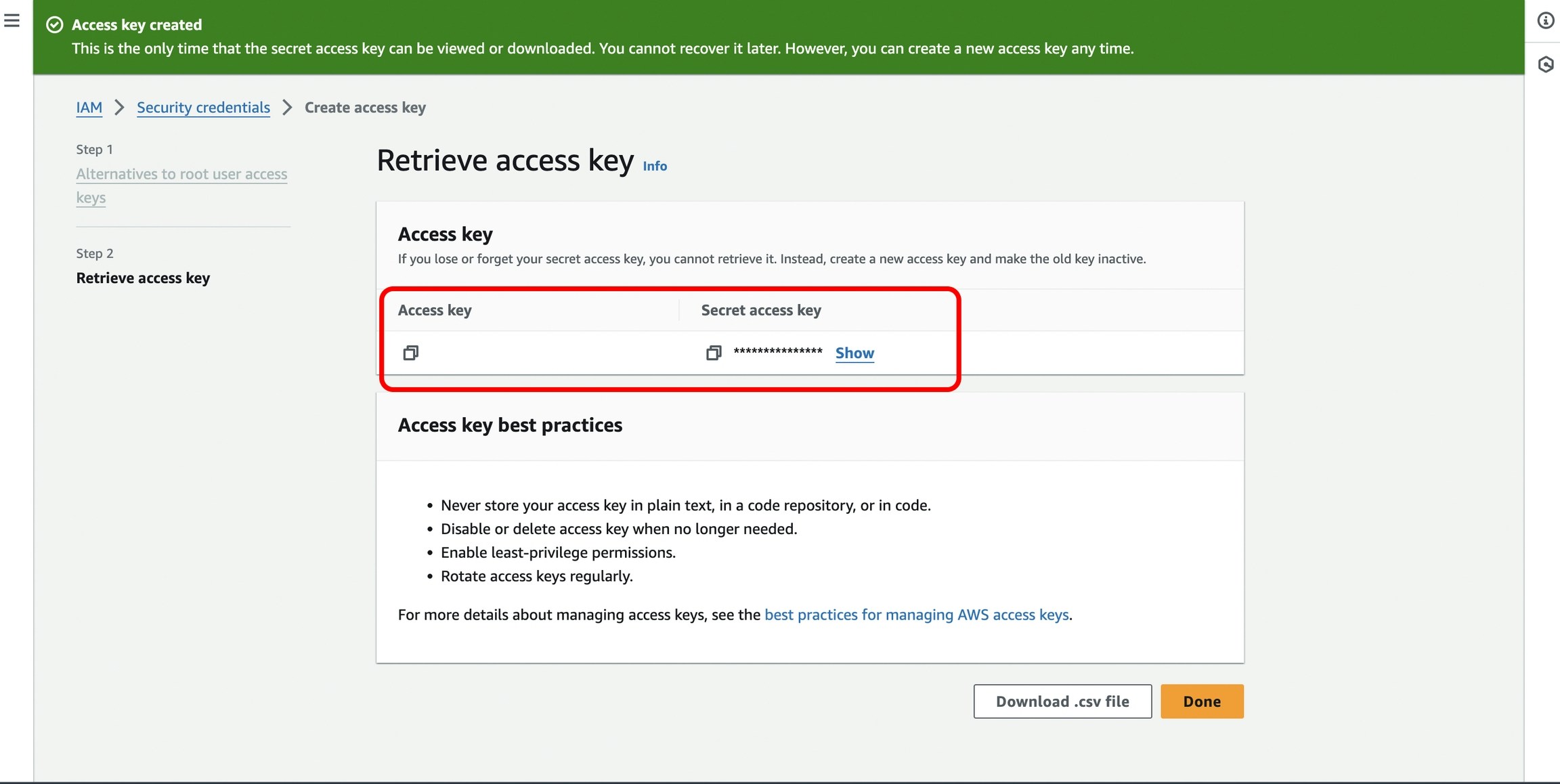
How to Find Your AWS Credentials
Navigate here in the AWS Management Console to obtain your AWS Access Key ID and AWS Secret Access Key.- In the console, you’ll find the ‘Access keys’ section. Click on ‘Create access key’.
- Copy the
Secret Access Keyonce it is generated, and you can view theAccess Key IDalong with it.

- On the same page under the ‘Access keys’ section, where you created your Secret Access key, you will also find your Access Key ID.
- And lastly, get Your
AWS Regionfrom the Home Page of AWS Bedrock as shown in the image below.